一种具有高泛化能力的分层联邦学习方法
本发明涉及电数字数据处理,尤其涉及一种具有高泛化能力的分层联邦学习方法。
背景技术:
1、随着人工智能技术的飞速发展,尤其是深度学习和强化学习领域的不断突破,机器学习模型在解决复杂问题上的能力日益增强。然而,在传统的联邦学习中,不论是同步更新及其变体或者是异步更新,都需要在多次更新中交换大量模型参数。为了克服这些挑战,研究者们提出了联邦学习(federated learning,fl)和分层学习(hierarchicallearning,hl)的概念,并结合深度强化学习(deep reinforcement learning,drl)中dqn(deep q-network)网络的优势,构建了一种新型的学习框架,即一种基于深度强化学习、具有泛化能力的分层联邦学习框架,它由1个云、l个边缘服务器和n个客户端以及n个强化学习网络组成。
2、现有的技术,通过深度神经网络的感知能力和深度强化学习的决策能力将训练任务分为多个子任务,并由相对应的低层策略执行,然后通过模型聚合算法设计激励机制,同时实时监测参与者的联邦学习过程,最后根据高层策略对联邦学习过程进行协同互动,实现了复杂环境下的智能决策。
3、例如公告号为:cn112668877b发明专利公告的结合联邦学习和强化学习的事物资源信息分配方法及系统,包括:待分配事物的管理和分配由管理者进行统一分配,且待分配事物并不能在数量上同时满足所有个体;管理者设计深度强化学习模型,并分发给每一个个体,个体使用深度强化学习模型对待分配事物进行选择;管理者通过联邦学习产生新的全局模型。
4、例如公开号为:cn117252253a专利申请公开的异步联邦边缘学习中的客户端选择和个性化隐私保护方法,包括:使用私有数据集对客户端的本地学习模型进行本地训练并进行本地更新;采用异步聚合方案将未及时参与聚合的客户端产生陈旧模型;当t=0时,边缘服务器初始化全局参数和陈旧模型陈旧度列表,将全局参数广播给所有客户端进行初始同步,并通知客户端开始本地训练;客户端收到全局模型后使用sgd算法进行本地更新,获得本地模型参数;当客户端在本地完成上述计算过程后,立即通过无线链路上传至边缘服务器。
5、但本技术在实现本技术实施例中发明技术方案的过程中,发现上述技术至少存在如下技术问题:
6、现有技术中,激励机制设计主要聚焦于参与者的异构性,这种单一维度的关注往往不足以全面应对联邦学习中长期效率和稳定性的挑战,存在分层联邦学习框架开销与模型准确性之间平衡性考虑不充分的问题。
技术实现思路
1、本技术实施例通过提供一种具有高泛化能力的分层联邦学习方法,解决了现有技术中分层联邦学习框架开销与模型准确性之间平衡性考虑不充分的问题,实现了分层联邦学习框架开销与模型准确性之间平衡性的提高。
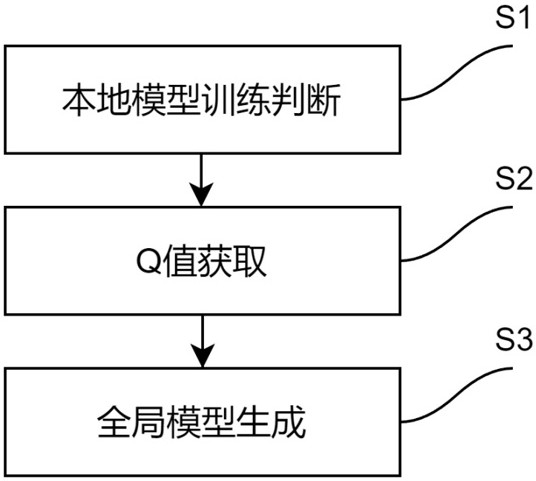
2、本技术实施例提供了一种具有高泛化能力的分层联邦学习方法,包括以下步骤:s1,获取客户端在预设时间段内提供的训练样本数据,根据训练样本数据判断客户端是否参与本地模型训练,若是,则执行s2,所述训练样本数据存储于联邦学习环境中,所述联邦学习环境包括状态空间和动作空间,所述本地模型通过联邦学习环境中的训练样本数据进行训练;s2,将参与本地模型训练的训练样本数据输入至dqn网络中得到预测q值和目标q值,同时根据dqn网络的内置参数对q网络进行训练以获取平衡状态值,所述预测q值用于预测当前状态下本地模型训练后的输出值,所述目标q值用于反映给定状态下本地模型训练后的期望值;s3,根据训练样本数据获取客户端的样本对并根据获取的样本对获取损失期望值,同时根据获取的损失期望值选择边缘服务器,将dqn网络中训练完成的本地模型上传至选择的边缘服务器进行模型聚合以生成边缘模型,并将生成的边缘模型上传至云端服务器生成全局模型,所述边缘服务器具有泛化能力,所述边缘模型用于实时处理训练样本数据并提高调度决策,所述全局模型用于根据调度决策评估和改进本地模型和边缘模型。
3、进一步的,所述根据训练样本数据判断客户端是否参与本地模型训练的具体流程为:判断训练样本数据是否等于0:若训练样本数据等于0,则表明对应的客户端不参与该轮本地模型训练,同时实时监测训练样本数据在预设时间段内的变化情况;若训练样本数据不等于0,则表明对应的客户端参与该轮本地模型训练,同时将对应的训练样本数据通过多层感知机输入至预设数据库中进行存储,所述多层感知机用于将客户端提供的不等于0的训练样本数据转换为q-learning的可处理状态。
4、进一步的,所述根据获取的样本对获取损失期望值的具体步骤为:根据本地模型训练过程中的预测值和样本标签值获取损失函数,所述预测值为本地模型参数对应的函数,所述损失函数用于量化预测值与样本标签值之间的差异程度;根据获取的损失函数得到客户端对应样本对的损失值,同时结合损失值对应的采样结果获取损失期望值,所述损失值用于反映本地模型在单个样本对上的预测准确性,所述采样结果为客户端选中的样本对,所述损失期望值用于反映本地模型在客户端的样本对上的平均性能表现。
5、进一步的,所述将参与本地模型训练的训练样本数据输入至dqn网络中得到预测q值和目标q值,之后还包括根据dqn网络的内置参数对q网络进行训练以获取平衡状态值;所述内置参数包括q网络参数以及target网络更新频率;所述q网络参数包括学习率、衰减率、折扣因子;所述平衡状态值为q网络在训练过程中的预测q值与目标q值达到平衡状态时的偏差q值;所述平衡状态为偏差q值等于参考偏差q值时对应的稳定状态;所述偏差q值为目标q值与预测q值的差值;所述参考偏差q值通过预设数据库中历史时间段内的历史偏差q值中不为0的最小值求和平均后的结果表示。
6、进一步的,所述根据内置参数对q网络进行训练的具体流程包括:步骤一,将参与本地模型训练的训练样本数据作为输入,获取用于训练q网络的训练限定数据,所述训练限定数据包括当前状态、给定状态和动作任务;步骤二,将当前状态输入至q网络中,通过q网络的前向传播过程获取当前状态下对应动作任务的预测q值,同时通过target网络获取给定状态下对应动作任务的目标q值;步骤三,通过q网络的反向传播过程按照target网络更新频率将q网络参数输入至target网络中以确保q网络在训练过程中的稳定性;步骤四,判断偏差q值是否等于参考偏差q值,若是,则完成q网络训练,否则返回步骤一,直至预测q值与目标q值之间的差值等于参考偏差q值后停止q网络训练。
7、进一步的,所述偏差q值的具体限制表达式为:
8、;
9、;
10、;
11、式中,t为当前时间步骤的编号,,t为当前时间步骤的总数量,表示dqn网络在当前时间步骤t的偏差q值,表示target网络在当前时间步骤t的目标q值,表示q网络在当前时间步骤t的预测q值,表示dqn网络在当前时间步骤t的状态空间,表示客户端在状态空间中选择的状态值,表示dqn网络在当前时间步骤t的动作空间,表示客户端在状态空间中选择的动作,表示客户端选定动作的动作目标值,表示未来系数,表示从当前时间步骤t到未来时间步骤k的折扣累积,表示本地模型在当前时间步骤t训练过程中的即时奖励,表示折扣因子,表示动作任务的调度决策进入联邦学习环境中对应当前时间步骤t的未来状态空间,表示target网络在未来状态空间下执行所有动作的最大目标q值。
12、本技术实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
13、1、通过获取客户端在预设时间段内提供的训练样本数据,根据训练样本数据判断客户端是否参与本地模型训练,同时获取本地模型训练过程中的损失期望值并选择边缘服务器,然后将参与本地模型训练的训练样本数据输入至dqn网络中得到预测q值和目标q值,最后将训练完成的本地模型上传至选择的边缘服务器中生成全局模型,从而实现了dqn网络与本地训练模型准确性之间平衡性的提高,进而实现了分层联邦学习框架开销与模型准确性之间平衡性的提高,有效解决了现有技术中分层联邦学习框架开销与模型准确性之间平衡性考虑不充分的问题;
14、2、通过判断训练样本数据是否等于0:若训练样本数据等于0,则实时监测训练样本数据在预设时间段内的变化情况,若训练样本数据不等于0,则将对应的训练样本数据通过多层感知机输入至预设数据库中进行存储,从而实现了训练样本数据的更精准判断,进而实现了本地模型训练客户端判断准确性的提高;
15、3、通过本地模型训练过程中的预测值和样本标签值获取损失函数,接着根据获取的损失函数得到客户端对应样本对的损失值,最后结合损失值对应的采样结果获取损失期望值,从而实现了损失值的更准确获取,进而实现了损失期望值获取准确性和可靠性的提高。
- 还没有人留言评论。精彩留言会获得点赞!