一种基于拆分学习的隐私保护联合训练平台
本发明主要涉及人工智能以及图像检测领域,特别是基于拆分学习和差分隐私技术的图像检测方法。
背景技术:
1、随着数据隐私保护需求的增加,传统的集中式学习方法面临着数据泄露和隐私侵犯的风险。拆分学习作为一种新兴的分布式学习方法,允许参与方在不共享原始数据的情况下共同训练模型,从而有效保护数据隐私。通过将数据分散在不同的设备或地点,拆分学习可以在各自的本地进行模型训练,仅共享模型参数或梯度信息,从而避免直接接触敏感数据。
2、与此同时,差分隐私技术为数据的保护提供了理论基础。差分隐私通过在模型训练过程中添加随机噪声,确保任何单个数据点对模型输出的影响是有限的,从而保护用户的隐私。然而,差分隐私的实现往往会导致模型性能的下降,尤其是在数据量有限的情况下。
3、结合拆分学习和差分隐私技术的研究逐渐受到关注,旨在在确保数据隐私的同时,提升模型的学习效果和预测准确性。这一领域的研究和应用有助于在多个行业中安全地利用大数据,尤其是在医疗、金融等对隐私保护要求较高的领域。
技术实现思路
1、本发明提供了一种基于拆分学习的隐私保护联合训练平台,旨在解决多方协作中的数据隐私保护问题,特别是在皮肤健康检测领域。通过将模型分为两部分,前半部分在参与方本地训练,后半部分在中央服务器聚合,参与方仅需共享模型参数或中间激活值,避免了原始数据的传输,从而有效保护用户隐私。此外,平台引入差分隐私技术,通过向梯度添加随机噪声,限制单个数据点对模型输出的影响,确保数据使用的合规性。该平台灵活可扩展,适用于医疗、金融等多个领域,推动了联合学习技术的发展。
2、本发明的目的可以通过以下技术方案来实现:
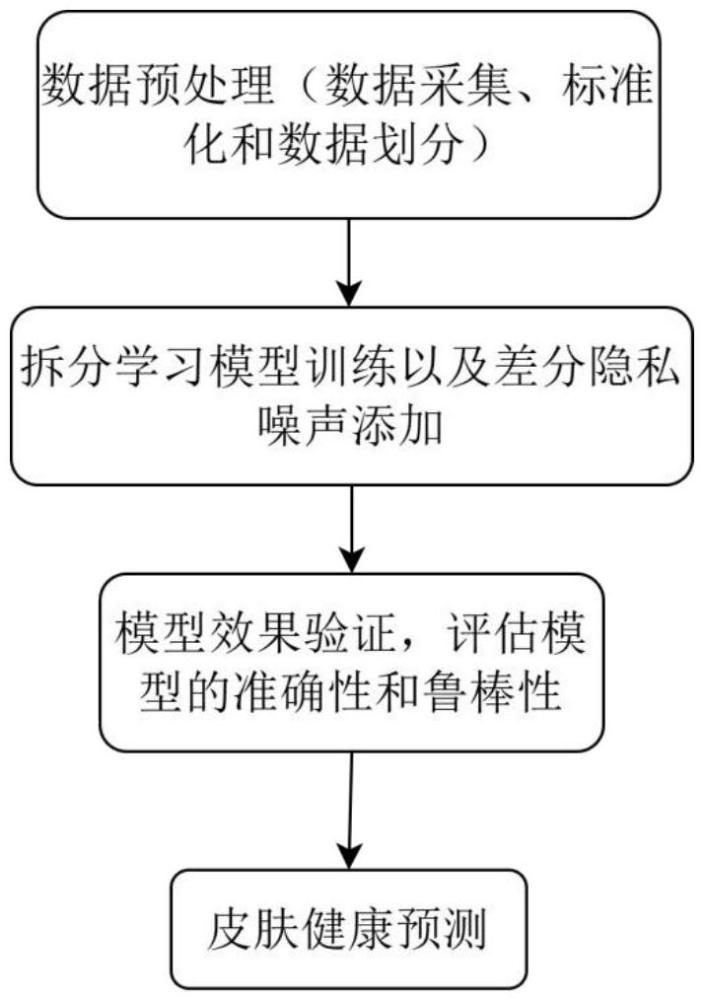
3、步骤s1:数据预处理,具体包括数据采集、标准化和数据划分;
4、步骤s2:模型训练,在多个设备上使用拆分学习方法对模型进行训练,所述方法包括模型初始化、参数更新和差分隐私添加,在模型训练过程中使用差分隐私技术向模型参数更新中添加噪声,以确保用户数据隐私;
5、步骤s3:模型验证,通过各种性能评估方法,评估模型的准确性和鲁棒性,确保其在未见数据上的表现;
6、步骤s4:皮肤健康预测,将训练好的模型应用于新的皮肤图像,输出皮肤健康检测结果。
7、进一步的,步骤s1包括:
8、步骤s1.1:数据采集,从公开数据集ham10000获取皮肤图像数据,所述数据集包含多种类型的皮肤病变图像;
9、步骤s1.2:数据标准化,将数据集中不同来源的图像进行标准化处理,具体包括:将图像缩放到统一的尺寸;将图像都转化为pytorch张量;最后按照
10、
11、进行标准化,其中outputc为标准化后的图像在通道c的像素值;inputc为原始图像在通道c的像素值;meanc为通道c的均值;stdc为通道c的标准差;
12、步骤s1.3:数据划分,将处理后的数据集划分为训练集dtrain和测试集dtest,具体包括:训练集用于模型的训练;测试集用于调参,模型选择以及最终性能评估,以确保模型的泛化能力。
13、进一步的,步骤s2包括:
14、步骤s2.1:模型初始化,在多个设备上初始化模型参数,具体包括选择合适的深度学习模型架构,例如模型的初始参数θ0;配置训练超参数,如学习率η、批量大小b和训练轮数e;
15、步骤s2.2:隐私保护下的拆分学习训练过程,具体包含客户端以及服务器端的训练过程以及噪声的添加;
16、步骤s2.3:监控训练过程,实时监控训练过程中的损失函数l(θ;dtrain),l(θ;dtest)和准确率acc(θ;dtrain),acc9θ;dtest),以便判断模型的收敛情况,具体包括:记录每个训练轮次的损失值和准确率;根据监控结果,调整学习率η和其他超参数,以优化训练效果;
17、步骤s2.4:终止条件判断,在训练过程中根据预设的终止条件判断是否停止训练,具体包括:当验证集的性能在若干轮次内未能提升时,停止训练以防止过拟合;达到最大训练轮数e时,终止训练过程。
18、进一步的,步骤s2.2包括:
19、步骤s2.2.1:前向传播,在客户端进行前向传播,计算每层的激活值,直到达到客户端的最后一层;
20、步骤s2.2.2:发送激活信息,将客户端最后一层的输出激活信息发送给服务器端;
21、步骤s2.2.3:服务器端前向传播,服务器端继续进行前向传播并计算损失;
22、步骤s2.2.4:服务器端反向传播,服务器端进行反向传播,计算梯度然后将梯度信息发送回客户端;
23、步骤s2.2.5:服务器端噪声添加,在服务器端反向传播后,进行梯度裁剪后向梯度添加噪声,计算带噪声的梯度:
24、
25、
26、其中是经过裁剪后的梯度,为添加的随机噪声,此噪声符合均值为0,方差为σ2c2的高斯分布,其中σ是标准差,c是裁剪大小,i是梯度维度。为服务器端添加噪声后的平均梯度;
27、步骤s2.2.6:服务器端模型参数更新:
28、
29、其中表示当前的服务器端模型参数,表示更新后的服务器端模型参数;
30、步骤s2.2.7:客户端反向传播,客户端利用接收到的梯度信息进行反向传播,完成整个模型的训练;
31、步骤s2.2.8:客户端噪声添加,在客户端反向传播后,向模型参数更新中添加噪声,计算带噪声的梯度:
32、
33、
34、其中参数的含义与服务器端一致,只是参数为客户端所拥有;
35、步骤s2.2.9:客户端模型参数更新,使用添加噪声后的梯度更新客户端模型参数:
36、
37、其中参数的含义同样与服务器端一致。
38、进一步的,步骤s3包括:
39、步骤s3.1:交叉验证,将验证集dval划分为k个子集{dval,1,dval,2,…,dval,k},进行k次训练和验证,具体包括:每次选择一个子集作为验证集其余k-1个子集作为训练集dtrain,k=dval\dval,i,以评估模型的泛化能力;
40、步骤s3.2:性能评估,使用多种评估指标来评估模型在验证集上的性能,具体包括:
41、准确率(accuracy):
42、
43、其中tp(true positives)是真正例,tn(true negatives)是真负例,fp(falsepositives)是假正例,fn(false negatives)是假负例。
44、召回率(recall):
45、
46、精确率(precision):
47、
48、
49、步骤s3.3:超参数调优,根据交叉验证的结果,调整模型的超参数(如学习率η、批量大小b和训练轮数e)以优化模型性能,具体包括:选择在验证集上表现最佳的超参数组合;
50、步骤s3.4:最终评估,在模型训练和验证完成后,使用测试集dtest对最终模型进行评估,计算最终的性能指标,以确认模型的有效性,确保模型在未见数据上的表现。
51、进一步的,步骤s4包括:
52、步骤s4.1:输入图像处理,将新的皮肤图像xnew进行预处理,具体处理过程与数据预处理中的表转化过程保持一致,即将图像缩放到统一的尺寸,接着将图像都转化为pytorch张量,最后按照
53、
54、进行标准化,其中outputc为标准化后的图像在通道c的像素值;inputc为原始图像在通道c的像素值;meanc为通道c的均值;stdc为通道c的标准差;
55、步骤s4.2:模型推理,将处理后的图像x′输入到训练好的模型中进行推理,计算输出的病变类型概率分布p(y|x′;θ),其中y表示病变类型,θ为训练好的模型参数;
56、步骤s4.3:结果输出,根据模型的输出概率分布,确定最终的预测结果通过公式
57、
58、选择概率最高的病变类型作为预测结果。
- 还没有人留言评论。精彩留言会获得点赞!