源码编译方法、装置、计算机设备及可读存储介质与流程
本技术涉及研发框架,尤其涉及一种源码编译方法、装置、计算机设备及可读存储介质。
背景技术:
1、在组件化的浪潮下,通过如采用monorepo等工具将所有的项目或模块存储在同一个代码库中,相互之间有依赖关系,可以共享代码和资源。可以方便地共享代码和资源,减少代码重复,便于维护和升级。但是代码库过于庞大,会导致编译和构建时间增加,同时也需要更加严格的代码管理规范,以避免代码冲突和错误。
2、为解决代码库过于庞大的问题,当下通过不同的项目或模块分别存储在不同的代码库中,每个代码库独立管理,相互之间没有依赖关系,修改一个代码库不会影响其他代码库,可以灵活地进行版本控制和发布。而在如monorepo内组件中由于修改没有独立的提交记录,组件版本将会信息丢失。无法确定每次修改和当前的修改都是兼容的,导致对代码库的版本管理十分混乱。
3、因此,亟需一种面向多个代码库的源码编译方法,以确定每次修改和当前的修改都是兼容的。
技术实现思路
1、本技术提供了一种源码编译方法、装置、计算机设备及可读存储介质,旨在解决当下通过不同的项目或模块分别存储在不同的代码库中,每个代码库独立管理,相互之间没有依赖关系,修改一个代码库不会影响其他代码库,可以灵活地进行版本控制和发布。而在如monorepo内组件中由于修改没有独立的提交记录,组件版本将会信息丢失。无法确定每次修改和当前的修改都是兼容的,导致对代码库的版本管理十分混乱的问题。
2、第一方面,本技术提供了一种源码编译方法,包括:
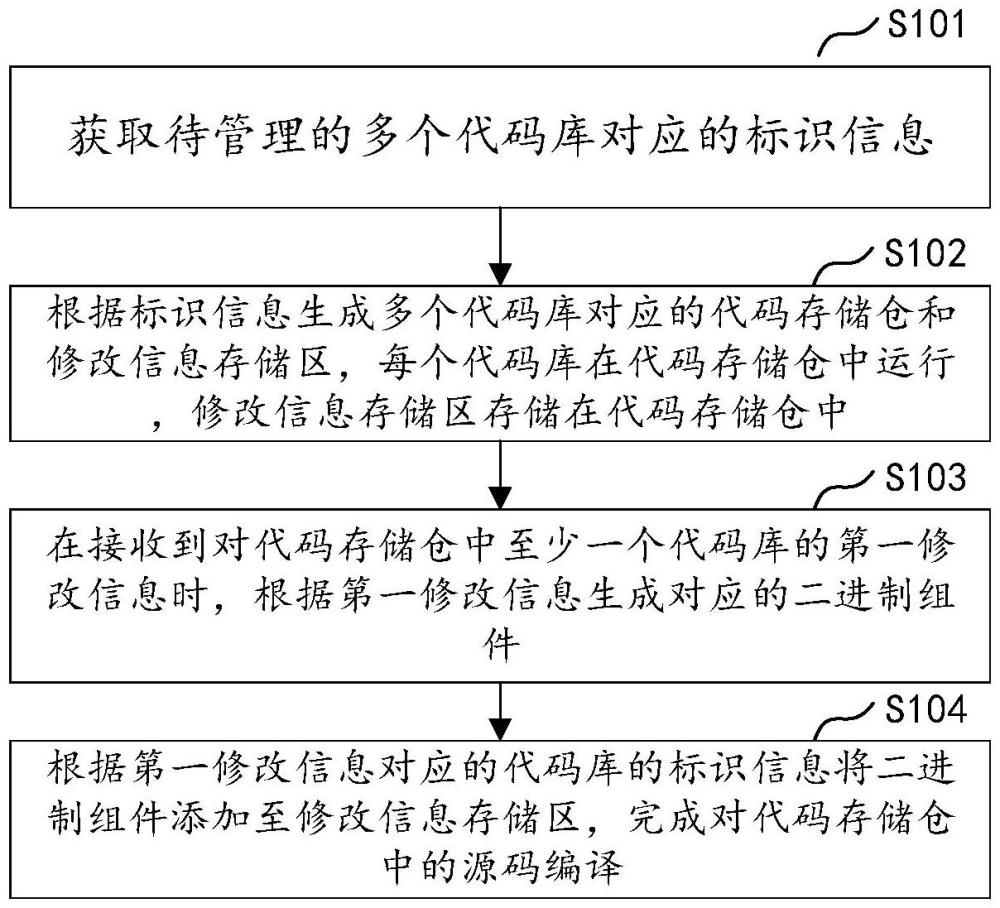
3、获取待管理的多个代码库对应的标识信息;
4、根据标识信息生成多个代码库对应的代码存储仓和修改信息存储区,每个代码库在代码存储仓中运行,修改信息存储区存储在代码存储仓中;
5、在接收到对代码存储仓中至少一个代码库的第一修改信息时,根据第一修改信息生成对应的二进制组件;
6、根据第一修改信息对应的代码库的标识信息将二进制组件添加至修改信息存储区,完成对代码存储仓中的源码编译。
7、在一些实施例中,标识信息至少包括代码库的名称、url和路径;代码存储仓为git存储仓;根据标识信息生成多个代码库对应的代码存储仓和修改信息存储区,包括:创建空白的git存储仓;将每个代码库和对应的标识信息添加至git存储仓中,每个代码库作为git存储仓中的一个子模块;在预设的开发环境中克隆git存储仓和每个子模块,以确保所有子模块都能在本地开发环境中访问和使用;在git存储仓中根据每个子模块对应的标识信息生成修改信息存储区,用于存储修改记录。
8、在一些实施例中,在根据第一修改信息对应的代码库的标识信息将二进制组件添加至修改信息存储区之后,二进制组件生成标识信息对应的历史修改组件;在完成对代码存储仓中的源码编译之后,还包括:在接收到新的第二修改信息时,根据第二修改信息生成对应的二进制组件;根据第二修改信息对应的代码库的标识信息在代码存储仓中检索,若第二修改信息对应的标识信息在代码存储仓中存在对应的历史修改组件,将第二修改信息对应的二进制组件添加至历史修改组件中。
9、示例性的,在将第二修改信息对应的二进制组件添加至历史修改组件中之前,还包括:将第二修改信息对应的修改内容与历史修改组件对应的修改内容进行合法性校验,获取校验结果;若根据校验结果确定合法性校验不通过,将校验结果返回至第二修改信息对应的终端设备,以提示对第二修改信息进行调整。
10、需要说明的是,在一些实施例中,将第二修改信息对应的修改内容与历史修改组件对应的修改内容进行合法性校验,包括:根据第二修改信息对应的修改内容与历史修改组件对应的修改内容进行比较,获取代码结构相似度评分、接口变更影响评分和依赖关系一致度评分;获取第二修改信息对应的修改内容的代码质量评分;根据代码结构相似度评分、接口变更影响评分、依赖关系一致度评分和代码质量评分完成合法性校验。
11、需要说明的是,在一些实施例中,若根据校验结果确定合法性校验不通过,方法还包括:根据校验结果在第二修改信息中确定合法性校验不通过对应的目标代码;取消对第二修改信息对应的代码库中目标代码对应的修改。
12、在一些实施例中,若第一修改信息对应代码存储仓中多个代码库,根据第一修改信息生成对应的二进制组件,根据第一修改信息对应的代码库的标识信息将二进制组件添加至修改信息存储区,包括:解析第一修改信息,获取多个子修改信息和每个子修改信息对应的代码库的标识信息;子修改信息至少包括版本号、编译时间和编译者标识;根据每个子修改信息和对应的标识信息生成子二进制组件;根据每个子二进制组件生成第一修改信息对应二进制组件。根据每个子二进制组件对应的标识信息将每个子二进制组件和添加至修改信息存储区中。
13、第二方面,本技术提供了一种源码编译装置,包括:
14、信息获取单元,用于获取待管理的多个代码库对应的标识信息;
15、存储生成单元,用于根据所述标识信息生成多个所述代码库对应的代码存储仓和修改信息存储区,每个所述代码库在所述代码存储仓中运行,所述修改信息存储区存储在所述代码存储仓中;
16、修改接收单元,用于在接收到对所述代码存储仓中至少一个所述代码库的第一修改信息时,根据第一修改信息生成对应的二进制组件;
17、编译完成单元,用于根据所述第一修改信息对应的代码库的标识信息将所述二进制组件添加至所述修改信息存储区,完成对所述代码存储仓中的源码编译。
18、第三方面,本技术还提供了一种计算机设备,包括:
19、存储器和处理器;
20、所述存储器用于存储计算机程序;
21、所述处理器,用于执行所述计算机程序并在执行所述计算机程序时实现如上第一方面所述的源码编译方法的步骤。
22、第四方面,本技术还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时使所述处理器实现如上第一方面所述的源码编译方法的步骤。
23、本技术实施例提供的一种源码编译方法、装置、计算机设备及可读存储介质,旨在解决多代码库管理和编译过程中存在的问题,特别是涉及到单一代码库(monorepo)内部组件管理时,在不破坏组件独立性的同时,保持对组件修改记录和版本的清晰跟踪。
24、首先,方法所搭载的系统能够识别并获取每个需要管理的代码库的唯一标识(如代码库的名称、id、或url等),以便后续的操作能够针对每个代码库进行有效的管理和区分。这种标识信息的收集使得系统可以动态地适应不同代码库的需求。
25、然后,代码存储仓是用于存放各代码库源代码的空间,而修改信息存储区则是专门用来记录代码库中发生的修改信息的区域。这两个存储空间的创建保证了代码及其修改历史的清晰分离,有利于之后的版本控制和问题追踪。每个代码库都有其独立的代码存储仓,这意味着可以独立运行、构建、测试,同时不会干扰到其他代码库的工作流。
26、再然后,当开发人员对任一代码库中的代码进行修改后,方法能自动捕获这些修改信息。这里的“第一修改信息”指的是任意一次修改操作的详细信息,包括但不限于修改的时间、修改内容、修改者等。通过对已修改的源代码进行编译,生成可以独立运行的二进制组件。这一步骤是确保源代码能够转化为实际可用的软件产品或服务的关键。每修改一次代码,理论上都会生成一个新的二进制组件版本,保证了每个修改都有对应的可执行版本。
27、最后,将生成的二进制组件及其相关的修改信息(如版本号、修改时间、修改者等)添加到该代码库对应的修改信息存储区中。这样做不仅保留了组件的版本信息,还使开发团队能够轻松回溯到任何特定时间点的构建状态,为代码审查、问题排查、以及后续的持续集成和持续部署(ci/cd)提供了坚实的基础。
28、进而所提供的方法具有以下有益效果:
29、1.提升版本控制的精确性:通过将每个代码库的修改信息与二进制组件绑定,该方法极大地提高了版本控制的精确程度,确保了每一次代码变更都有迹可循,有助于维护代码质量和稳定性。
30、2.增强代码库管理的灵活性:既支持多代码库并行开发,又允许在monorepo中进行细粒度的组件管理,为不同的开发场景提供了更多的灵活性。
31、3.提高团队协作效率:清晰的修改记录和版本信息使得团队成员可以更容易地理解彼此的工作进展,减少了沟通成本,提高了开发效率。
32、4.简化持续集成/持续部署过程:由于每一次修改都会生成一个新的二进制组件,并将其详细信息记录在案,这大大简化了ci/cd流程中的构建、测试和发布步骤,加速了软件的交付周期。
33、5.降低错误率和维护成本:通过自动化的编译和版本管理,减少了人为错误的可能性,同时也简化了长期维护的工作,尤其是当涉及多个版本同时需要支持时。
34、综上,该源码编译方法通过巧妙地结合代码存储与修改信息记录,为复杂多代码库或单一大型代码库中的并发开发提供了一套高效的解决方案,显著提升了软件开发过程中的版本管理精度、开发灵活性、团队协作效率以及自动化程度,对于提高软件产品质量和加快开发速度具有重要意义。
35、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!