一种基于多维缩略语语义识别的数据库数据筛选方法、系统及存储介质、计算机程序产品与流程
本技术涉及语义分析、数据整理,尤其涉及一种基于语义识别的数据库数据筛选领域。
背景技术:
1、目前数据库字段检索方法有:(1)根据中文注释推断字段含义方法,如cn113032360a公开了一种推测数据库字段含义的方法,该方法虽然能部分解决字段匹配问题,但推断不了不带中文注释的字段含义,其只能直接通过数据库字段名来推断其含义;(2)基于rdf联邦查询,如cn 118364073a公开了一种基于大模型的分布式rdf数据语义检索方法,该方法基于大语言模型,从用户问句中提取实体关键词组,在rdf数据资源的基础上构建向量数据库,根据提取关键词匹配rdf数据资源,该方法是通过关键词正向检索内容匹配度低,只能根据缩略语去推断字段含义。
2、随着大数据技术的快速发展,企业和科研机构在数据分析、存储、应用等方面的需求大幅增长。数据库作为信息存储的主要载体,通常包含大量未标准化的字段命名方式,包括英文缩写、拼音首字母缩写等非正式表达。这种字段命名方式虽然节省了存储空间,但给后续数据筛选、分析带来了极大的障碍,尤其是难以准确识别列名的实际含义。
3、现有技术在字段缩写的语义识别上存在以下缺陷:
4、1.识别局限性:依赖字段的中文注释信息进行推断的方案无法处理无注释或仅含拼音首字母的字段,对简化命名的字段适应性差,缺乏直接从字段名推断含义的能力。
5、2.匹配精度不足:关键词匹配和正向检索方法对字段名中的缩略语识别较弱,主要依赖关键词直接匹配,导致在处理不规则缩写或多义性字段时准确性差,难以实现有效的语义推断。
6、3.多义性和语义分割问题:现有方法在识别拼音缩写等多义性字段时,缺少关联分析和语义分割手段,无法在含义冲突中选择最优解释,容易导致识别错误。
7、4.领域适应性不足:自然语言方法方法解决不了缩略语检索,自然语言模型针对非常规字段含义推断准确性较低。
技术实现思路
1、基于上述现有技术存在的不足,本发明提出一种基于缩略语语义识别的数据库数据筛选方法、系统及存储介质、计算机程序产品,具有高准确度的多语言字段含义识别效果,从而为数据筛选和分析提供更加高效和智能化的工具。
2、本发明提供一种基于多维缩略语语义识别的数据库数据筛选方法,包括:
3、s10.构造中文词库和英语词库,其中所述中文词库包括首字母词库,所述首字母词库包括首字母表、词典字母表和词典语境表,所述英语词库包括非标准英语词库;
4、s20.对待检测语句进行中文语义推断,如不符合预定的中文推断情况则进行英文语义推断;
5、s30.将所述中文语义推断或英文语义推断的结果输入nlp大模型进行语义预测。
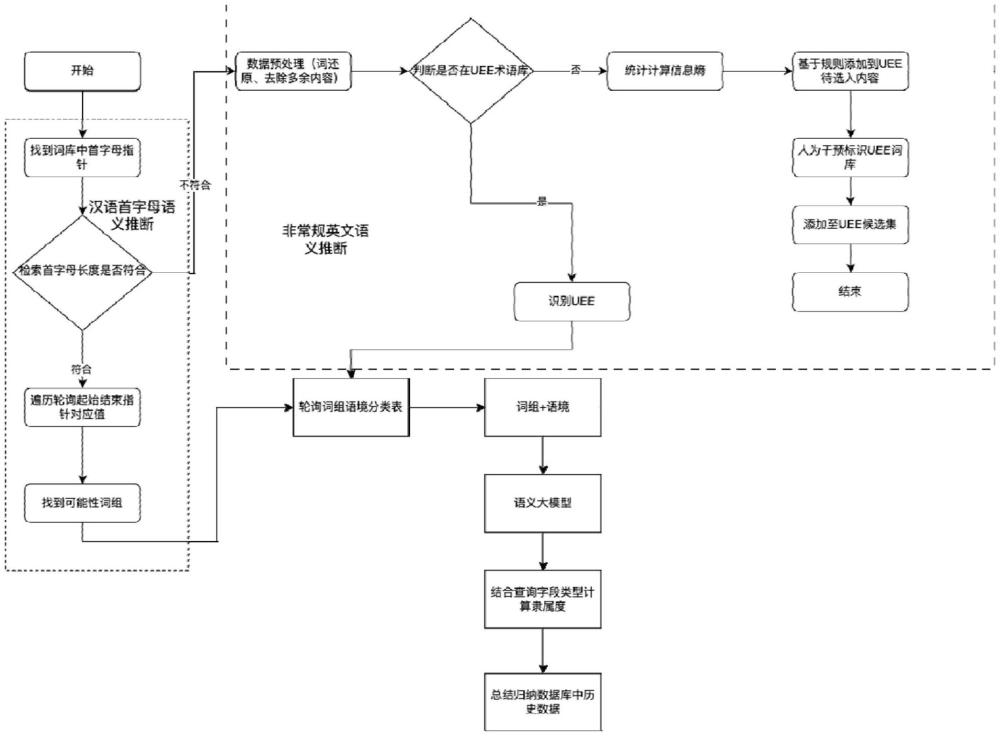
6、进一步地,所述步骤s20中,对待检测语句进行中文语义推断包括:根据数据库字段缩略语句,查询所述首字母表,判断首字母长度是否符合所述首字母表长度要求,如果符合长度要就进入到汉语首字母语义推断流程,通过轮询所述首字母表中的起始与结束指针位置来找到符合首字母对应中文词组;如在词典字母表中未找到对应的词组,则跳出中文推断流程进入到英文字母匹配流程。
7、进一步地,所述首字母表包括首字母,词典开始指针位置以及词条结束指针位置;所述词典字母表包括首字母,词典字母表识别标记,首字母长度,首字母对应起始词指针地址起始位以及首字母对应末尾词指针;所述词典语境表包括首字母词条,词典语境表识别标记以及关联语境内容。
8、进一步地,所述步骤s20中,对待检测语句进行英文语义推断包括:对数据进行预处理,根据对数据库字段中的特殊符号进行统一处理去除多余符号,经过上述预处理之后的数据作为查询非标准英语词库的条件,判断是否找到其含义,再通过含义找到其对应的场景分类表查询其对应场景。
9、进一步地,若在非标准英语词库中未找到,则进入到新的语言相关性与信息量指标计算环节,通过语言单元的相关性、信息量指标计算取交集结果之后,得出经过处理之后的数据将最终计算所得的交集结果输入到待入选非标准英语词库中,最终通过人为干预输入到非标准英语词库中。
10、进一步地,非标准英语词库包括非标准英语标识,非标准英语的解释语句以及非标准英语的关联表达。
11、进一步地,所述步骤s30中通过nlp大模型进行语义预测包括:
12、从数据库查询的字段信息以及可能的结果场景描述,推断出字段的初步含义,并将这些初步含义与场景描述进行比对,以筛选出最具相关性的语义候选项;调用预训练的nlp模型对语义候选项进行上下文扩展分析。该步骤通过模型理解字段所在的上下文,生成符合场景要求的语义表达。
13、本发明还提供一种基于多维缩略语语义识别的数据库数据筛选系统,包括:
14、中文词库,所述中文词库包括首字母词库,所述首字母词库包括首字母表、词典字母表和词典语境表;
15、英语词库,所述英语词库包括非标准英语词库;
16、推断模块,所述推断模块对待检测语句进行中文语义推断,如不符合预定的中文推断情况则进行英文语义推断;
17、npl语义大模型,所述nlp大模型根据所述推断模块输出的所述中文语义推断或英文语义推断的结果进行语义预测。
18、本发明还提供一种计算机存储介质,其特征在于,包括计算机指令,当所述计算机指令在电子设备上运行时,所述电子设备执行前述的基于多维缩略语语义识别的数据库数据筛选方法。
19、本发明还提供一种计算机程序产品,其特征在于,当所述计算机程序产品在计算机上运行时,所述计算机执行前述的基于多维缩略语语义识别的数据库数据筛选方法。
20、与现有技术相比,本发明提供的基于多维缩略语语义识别的数据库数据筛选方法具有以下有益效果:
21、1.本发明通过分析数据库中字段列名推断其语义含义,以筛选出目标数据的方法。该方法主要包括三个维度:一是识别数据库中的英文非正式字段缩写,通过建立与完善非标英语库来识别与推断英文缩略语的实际含义;二是建立中文首字母缩写表,通过构建并对比中文词库还原各个首字母缩写所代表的完整汉字;将上述两种方式所得出的可能语义与关联场景表做比得出结果,最终将得出的结果输入大语言模型进行语义分割和关联分析得出字段语义;查询数据库行数据类型判断如浮点、字符、布尔、整型、中文注释情况计算隶属度,最终从词库中检索出最符合的含义。该方法能够有效提高数据库字段含义的推断精度,从而在多维度数据筛选中准确定位关键信息,广泛适用于数据整理、智能分析等数据库应用领域。
22、2.提高字段语义识别的精准度。传统方法通常只能基于字段名称的字面含义来识别字段语义,容易忽视实际应用中的上下文和业务关联性。本发明通过多维语义推断和上下文扩展分析,将字段含义与数据库应用场景进行深度结合,提高了字段语义识别的准确性,使其更贴近实际业务含义。
23、3.多语言缩略语支持。本发明不仅支持英文字段的缩写识别,引入了中文首字母缩写的还原,通过中英文词库的构建和匹配,实现对非标准英文缩写和中文首字母缩写的双向支持。这种多语言缩略语识别在跨语言数据库应用场景中尤为实用,解决了以往技术无法准确理解中文字段缩写的难题。
24、4.领域分类与业务场景映射。通过预训练的nlp模型和领域分类模型,本发明能够预测字段所属的具体业务或技术领域,从而为字段提供更加符合行业需求的语义解释。
25、5.动态适应性强。本发明利用场景关联表和词库的动态更新,能够适应不断变化的数据库结构和业务需求。与以往依赖静态规则的技术相比,本发明方法的适应性更强,可以快速响应新的业务场景和字段缩写,从而有效支持数据库管理和分析的动态需求。
26、6.增强的数据筛选与分析能力。通过多维度语义识别,本发明显著提升了数据库字段筛选的准确性,能够在复杂的数据库环境中快速定位关键信息。该优势在需要高效数据筛选的智能分析、数据挖掘等应用领域具有重要价值,弥补了传统方法在复杂筛选条件下效率不足的缺陷。
- 还没有人留言评论。精彩留言会获得点赞!