POI推荐装置、方法、电子设备及可读存储介质
本技术涉及数据处理,具体涉及一种poi推荐装置、方法、电子设备及可读存储介质。
背景技术:
1、poi(point of interest,兴趣点)推荐技术本质上利用用户的历史签到和其他多模态信息(例如location属性和好友网络)来推荐下一组适合用户的poi。大量早期工作专注于传统的机器学习技术,依赖于通过人为制定的特征模式。近年来,深度学习技术再poi推荐领域的应用日益增多,越来越多的工作开始使用深度神经网络模型来提高poi task的准确率。其中,深度学习方法(如卷积神经网络(cnn)或循环神经网络(rnn))在自动特征提取方面具有许多优势,减少了人为制定特征的设计困难。一些最新研究通过图嵌入技术来丰富模型的语义地理空间信息,进一步提升了推荐模型的性能。
2、现有系统可能没有充分考虑不同用户群体(如不同年龄、性别、职业)的多样化偏好,导致推荐结果可能无法满足所有用户群体的需求。例如,不同的用户有不同的习惯和偏好,例如年轻人通常喜欢在周末去购物中心,有些人喜欢在午夜去吃夜宵。而老年人可能喜欢在下午去花园,几乎从不在午夜外出。不同性别和职业的人群中也存在类似的现象。为了满足不同的偏好,需要将具有相似因素的人归为一类。poi推荐系统应该对不同的人群给出不同的推荐。同时有些群体在数据集里占比很小,因此由他们产生的轨迹数据也相对小,那么数据集里就存在数据不平衡问题。
3、群体公平性是指模型的输出对各个群体是否公平。现有系统中,如果同时考虑多个群体的目标,无法用一个统一的目标函数很好地表达,或者简单地将多个目标函数相加,而是需要对不同群体的目标函数施加一些约束。近年来,一些方法也考虑将帕累托纳入群体公平问题,以整体满意度、群体公平和社会福利为多优化目标,即,通过检查添加新的推荐项目是否会超过当前多目标函数的最优值来不断搜索帕累托前沿,直到收敛;但这些方法在poi推荐系统中的应用和效果尚未明确。因此,现有系统没有关注过数据集中不同群体的数据不平衡问题,会造成相对于数据量大的群体,模型对数据量较小的群体预测的不够准确的问题。
技术实现思路
1、本发明主要解决的技术问题是提供一种poi推荐装置、方法、电子设备及可读存储介质,有效地解决现有poi推荐系统中的数据不平衡、群体偏好多样性和群体公平性等问题,达到了提高推荐准确性、增强公平性和优化训练过程的技术效果。
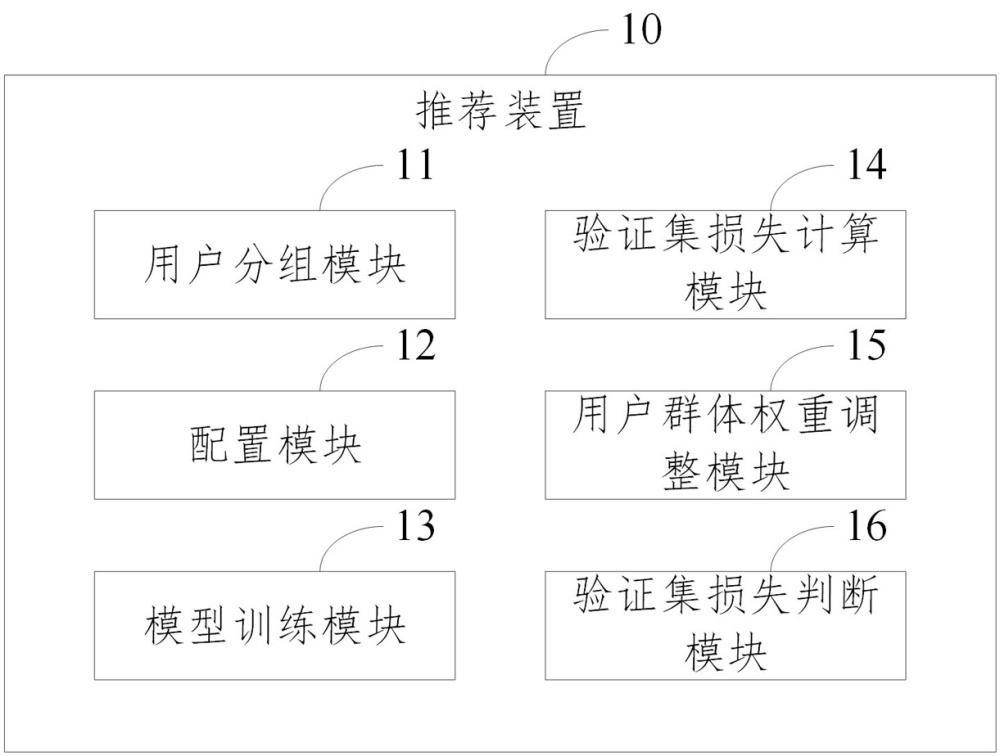
2、为解决上述技术问题,本发明采用的一个技术方案是:提供一种poi推荐装置,所述装置包括:用户分组模块,用于对用户进行分组,以将用户分为不同的用户群体;配置模块,用于为每个用户群体分配初始权重,以及初始化模型参数;模型训练模块,用于利用目标函数,对深度神经网络模型进行训练以得到训练集损失函数;验证集损失计算模块,用于基于所述模型训练模块对深度神经网络模型进行训练得到的训练集损失函数计算验证集损失值;用户群体权重调整模块,用于根据所述验证集损失计算模块计算得到的验证集损失值,按照预定的权重更新规则调整各用户群体的权重;其中,所述权重更新规则为:如果用户群体的验证集损失值不小于历史中迭代中得到的最好模型学习最差的用户群体的验证集损失函数值,则调高所述群体的权重值;验证集损失判断模块,用于判断当前迭代得到验证集损失值向量是否在所有用户群体上都不大于历史最优模型的验证集损失值向量;所述配置模块,还用于:在所述验证集损失判断模块确定当前迭代得到验证集损失值向量在所有用户群体上都不大于历史最优模型的验证集损失值向量时,并且在至少一个用户群体上取得了更好的结果时,更新历史最优模型参数,并记录当前模型的损失值作为新的基准,同时重置所述模型参数;以及在所述验证集损失判断模块确定当前迭代得到验证集损失值向量未在所有用户群体上都不大于历史最优模型的验证集损失值向量时,调整所述模型参数以减小用户群体权重的调整幅度;所述模型训练模块,还用于判断模型是否收敛;所述配置模块,还用于:当确认模型已经收敛时,调用历史最优模型的参数,并为模型配置所述历史最优模型的参数,以利用所述模型预测用户的poi;以及当确认模型没有收敛时,调用历史最优模型的参数,并为模型配置所述历史最优模型的参数,使得所述模型训练模块继续利用目标函数对当前模型进行训练,直至模型收敛。
3、其中,所述用户分组模块,用于根据用户的行为特征和社交属性将用户分为不同的组,以形成不同的用户群体;其中,所述用户的行为特征和社交属性包括签到数和好友数。
4、其中,所述目标函数由公式(2)定义,μg是用户群体g的权重,lg(h)表示在模型参数h下,用户群体g的训练集损失;
5、公式(2)
6、其中,所述预定的权重更新规则由公式(3)定义,α和k是模型参数:
7、公式(3)。
8、为解决上述技术问题,本发明采用的另一个技术方案是:提供一种poi推荐方法,所述方法包括:对用户进行分组,以将用户分为不同的用户群体;并为每个用户群体分配初始权重,以及初始化模型参数;利用目标函数,对深度神经网络模型进行训练以得到训练集损失函数;基于对深度神经网络模型进行训练得到的训练集损失函数计算验证集的损失值;根据计算得到的所述验证集损失值,按照预定的权重更新规则调整各用户群体的权重;其中,所述权重更新规则为:如果用户群体g的验证集损失值不小于历史中迭代中得到的最好模型学习最差的用户群体的验证集损失函数值,则调高所述群体的权重值;判断当前迭代得到的验证集损失值向量是否在所有用户群体上都不大于历史最佳模型的验证集损失值向量;在当前迭代得到验证集损失值向量在所有用户群体上都不大于历史最优模型的验证集损失值向量时,并且在至少一个用户群体上取得了更好的结果时,更新历史最优模型参数,并记录当前模型的损失值作为新的基准,同时重置所述模型参数;在当前迭代得到验证集损失值向量未在所有用户群体上都不大于历史最优模型的验证集损失值向量时,调整所述模型参数以减小用户群体权重的调整幅度;在确定模型收敛时,调用历史最优模型的参数,并为模型配置所述历史最优模型的参数,以利用所述模型预测用户的poi;在确定模型尚未收敛时,调用历史最优模型的参数,并为模型配置所述历史最优模型的参数,继续利用目标函数对当前模型进行训练,直至模型收敛。
9、其中,对用户进行分组,以将用户分为不同的用户群体,具体为:根据用户的行为特征和社交属性将用户分为不同的组,以形成不同的用户群体;其中,所述用户的行为特征和社交属性包括签到数和好友数。
10、其中,所述目标函数由公式(2)定义,μg是用户群体g的权重,lg(h)表示在模型参数h下,用户群体g的训练集损失;
11、公式(2)
12、其中,所述预定的权重更新规则由公式(3)定义,α和k是模型参数:
13、公式(3)。
14、为解决上述技术问题,本发明采用的另一个技术方案是:提供一种电子设备,包括:处理器和存储器,存储器用于存储计算机程序代码,计算机程序代码包括计算机指令,当处理器执行所述计算机指令时,电子设备执行如上所述的poi推荐方法的步骤。
15、为解决上述技术问题,本发明采用的另一个技术方案是:提供一种可读存储介质,可读存储介质中存储有计算机程序,计算机程序包括程序指令,程序指令当被电子设备的处理器执行时,使处理器执行如上所述的poi推荐方法的步骤。
16、本发明提供的一种poi推荐装置、方法、电子设备及可读存储介质,通过用户的行为特征和社交属性将用户分为不同的群体,例如根据签到数和好友数进行分组,以形成不同的用户群体,并为每个用户群体分配初始权重,考虑了不同用户群体的多样化偏好,使得推荐结果能够更好地满足不同用户群体的需求,解决了数据集中不同群体的数据不平衡问题,提高了模型对数据量较小群体的预测准确性;使用深度神经网络模型,并通过目标函数进行多epoch训练,考虑数据量对各用户群体验证损失的影响,优化群体公平性;根据验证集损失值,使用类似minimax算法的策略调整各用户群体的权重,确保pareto效用;判断当前迭代的验证集损失值向量是否优于历史最优模型,以接近pareto最优;从而通过权重调整和pareto优化,确保了模型输出对各个群体的公平性,避免了单一目标函数无法平衡多群体目标的问题。
- 还没有人留言评论。精彩留言会获得点赞!