少样本的司法庭审文件实体提取方法、系统及存储介质
本发明涉及自然语言处理,特别是涉及一种少样本的司法庭审文件实体提取方法、系统及存储介质。
背景技术:
1、法官在民事、刑事、行政案件庭审过程中,通过查阅多种材料,如起诉文书、证据材料、检察文书等以了解案件信息,此部分材料多以结构化数据、半结构数据为主。司法人员在提取法律案件的案情要素过程中需要耗费大量的人力,这不仅效率不高,而且容易受到个人主观判断的影响。
2、随着自然语言处理和大数据分析等技术的不断进步,相关技术人员已经开发出了一些可以实现案情要素提取的工具,这为司法工作人员提供了便利。例如,中国发明专利申请公开号cn118364047a提供了一种实体关系提取模型训练、实体关系提取方法、装置及设备,该方法通过收集文本数据,并为每个文本单元标注是否属于实体以及实体间的关系;利用标注好的文本样本训练实体关系提取模型,使其学习识别实体及其关系;使用特征映射网络将文本单元转换为特征向量;通过全局指针网络分析特征向量序列,预测实体关系,生成实体关系预测矩阵。该方案虽然可以实现从文本数据中识别实体信息和实体间的逻辑关系,但是该方案没有考虑训练样本不够足够多以及文件每一个模块的特征多样的特点,使得实体和实体类型的识别准确率不高。
技术实现思路
1、基于此,有必要针对现有司法庭审文件民事起诉状中训练样本不足且实体和实体类型提取准确率不高的问题,提供一种少样本的司法庭审文件民事起诉状中实体和实体类型提取的检索系统和方法。
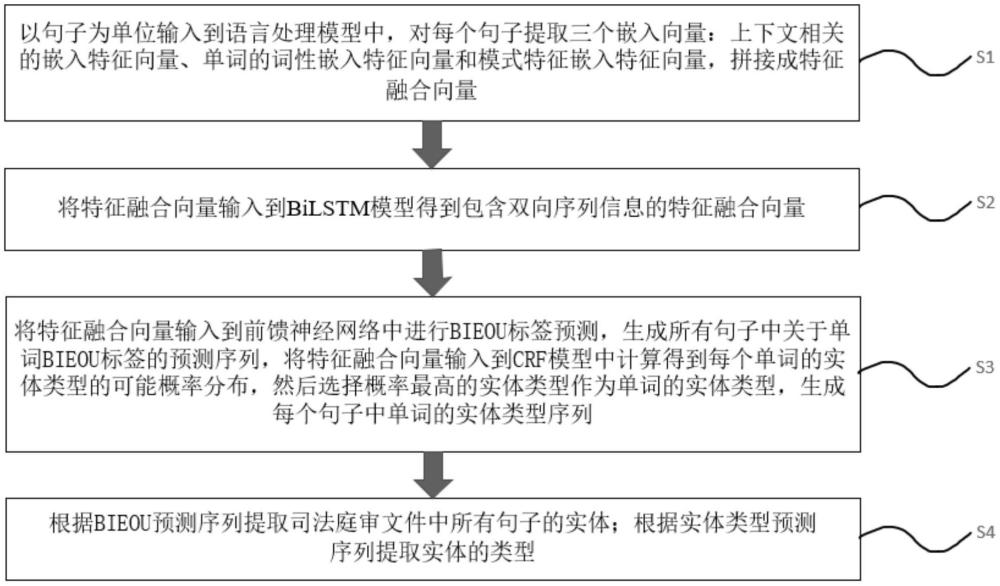
2、一种少样本司法庭审文件中的实体提取方法,其在缺少训练样本的情况下对所有模型进行训练,通过训练好的各个模型对司法庭审文件中的实体和实体类型进行提取;其中,对模型进行训练的方法包括以下步骤:
3、对训练样本进行数据增强生成增强数据;所述数据增强的方法包括:保留实体的类别标签,并对实体和上下文进行掩码,并生成增强数据;改变实体的类别标签去掩码预测实体和上下文,并生成增强数据;添加一个实体类别,进行实体和上下文的掩码预测,并生成增强数据;
4、对生成的所述增强数据进行筛选:删除实体类别与具体实体不符合的增强数据,保留实体类别与具体实体相符的增强数据;
5、将筛选后的所述增强数据与训练样本进行混合,共同作为模型的训练样本进行输入;
6、对司法庭审文件中的实体和实体类型进行提取包括以下步骤:
7、司法庭审文件包括l个句子,每个句子包括m个单词;以句子为单位输入到语言处理模型中生成三个嵌入向量:上下文相关的嵌入特征向量单词的词性嵌入特征向量和模式特征嵌入特征向量三个嵌入向量集合成特征融合向量ti;
8、将特征融合向量ti输入到bilstm模型得到包含双向序列信息的特征融合向量ti′;
9、将特征融合向量ti′输入到前馈神经网络中进行bieou标签预测,并生成所有句子中关于单词bieou标签的预测序列yl={y1,y2,…,ym},其中,yl表示句子的bieou标签序列,ym表示句子中第m个单词属于的bieou标签种类;
10、将特征融合向量ti′输入到crf模型中计算得到每个单词的实体类型的可能概率分布,然后选择概率最高的实体类型作为单词的实体类型,生成每个句子中单词的实体类型序列zl={z1,z2,…,zm},其中,zl表示句子的实体类型序列,zm表示句子中第m个单词的实体类型;
11、根据预测序列yl={y1,y2,…,ym}提取司法庭审文件中所有句子的实体;根据实体类型序列zl={z1,z2,…,zm}提取实体的类型。
12、作为优选实例,所述增强数据与原始训练样本进行混合的公式为:
13、
14、a~u(1,a) b~u(1,b) x~u(1,c) y~u(1,c)
15、式中,saug代表混合后的训练样本,代表从训练样本中随机抽取的第k个句子,代表从增强数据中随机抽取的第q个句子,x代表从原始训练样本中随机抽取的句子的数量,y代表从原始训练样本中随机抽取的句子的数量,a是原始训练样本中句子的数量,b是增强数据集中句子的数量,c代表可以连接的最大句子数量,u(1,a)、u(1,b)和u(1,c)分别表示从1到a、1到b和1到c之间随机选择一个数,a是从原始训练样本随机抽取的句子的序号,b是从增强数据集中随机抽取的句子的序号。
16、作为优选实例,语言处理模型包括bert语言模型和word2vec词向量模型;所述句子通过bert语言模型生成嵌入特征向量所述句子通过word2vec词向量模型生成嵌入特征向量
17、作为优选实例,所述句子引入模式特征,其用于捕捉实体提及在子词级别上的内在单词形状;将所述模式特征编码后依次输入cnn、bilstm模型中获取模式特征嵌入特征向量
18、作为优选实例,得到包含双向序列信息的特征融合向量ti′的方法包括以下步骤:
19、将特征融合向量ti输入到bilstm模型中得到前向隐藏状态和后向隐藏状态
20、
21、将前向隐藏状态和后向隐藏状态进行拼接得到特征融合向量ti′:
22、
23、式中,[t1,t2,…,tm]是经过特征融合的句子序列,⊕表示向量连接操作。
24、作为优选实例,生成预测序列yl={y1,y2,…,ym}的方法包括以下步骤:
25、计算句子中每个单词关于bieou标签的概率pi:
26、pi=softmax(ffn(ti′))
27、式中,softmax为softmax函数,ffn为前馈神经网络;
28、选择单词中概率pi最大的bieou标签作为该单词的bieou标签:
29、yi=argmax(pi)
30、式中,yi表示句子中第i个单词的bieou标签,argmax为argmax函数;
31、根据单词的bieou标签结果得到预测序列yl={y1,y2,…,ym}。
32、作为优选实例,生成实体类型序列zl={z1,z2,…,zm}的方法包括以下步骤:
33、计算句子中每个单词属于预定义中每个实体类型的概率qi:
34、qi=crf(ti′)
35、式中,crf为crf模型;
36、选择单词中概率qi最大的实体类型作为该单词的实体类型:
37、zi=viterbi(qi)
38、式中,zi表示句子中第i个单词的实体类型,viterbi为viterbi算法;
39、根据单词的实体类型结果得到实体类型序列zl={z1,z2,…,zm}。
40、作为优选实例,单词的实体类型为预定义的实体类型,预定义的实体类型包括:法院、商业实体、政府机构、法规、犯罪嫌疑人、受害人、作案工具、被盗物品、物品价值、法律名、法官、原告、被告、政治体、用工单位、个体工商户和工作职位。
41、一种少样本司法庭审文件中的实体提取系统,其使用如上所述的少样本司法庭审文件中的实体提取方法;所述实体提取系统包括:
42、训练模块,其用于对训练样本进行数据增强生成增强数据,随后对生成的所述增强数据进行筛选;将筛选后的增强数据与训练样本进行混合后共同对模型进行训练;
43、向量化模块,其用于将司法庭审文件中的每个句子生成三个嵌入向量,分别为上下文相关的嵌入特征向量单词的词性嵌入特征向量和模式特征嵌入特征向量随后将三个嵌入向量集合成特征融合向量ti;
44、实体提取模块,其用于根据特征融合向量ti生成所有句子中关于单词bieou标签的预测序列yl={y1,y2,…,ym};
45、实体类型提取模块,其用于根据特征融合向量ti生成每个句子中单词的实体类型序列zl={z1,z2,…,zm}。
46、一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的少样本司法庭审文件中的实体提取方法。
47、本发明的有益效果在于:
48、1、本发明采用数据增强技术,通过保留实体类别标签掩码实体、改变实体类别标签预测实体以及添加新实体类别掩码预测的方法,扩充训练数据集。接着,将增强后的数据与原始数据混合,输入到语言模型中进行训练,从而解决了司法庭审文件民事起诉状中训练样本不足的问题。
49、2、本发明利用语言模型生成上下文相关、词性和模式特征的嵌入向量,这些向量被融合为特征融合向量,随后,特征融合向量被输入到bi-lstm网络捕捉双向信息,并结合前馈神经网络ffn预测bieou标签,生成预测序列。同时,bi-lstm的输出也输入到条件随机场(crf)层,基于概率选择最可能的实体类型。最终,根据预测序列提取实体,并利用crf输出的标签频率确定实体类型,如人名、地点等,实现对司法文件中各类实体的精准识别。与现有方案相比,本发明方案能够准确从半结构化的文本数据中识别实体信息和实体的类型。
- 还没有人留言评论。精彩留言会获得点赞!