一种基于主动学习的低资源语言机器翻译方法
本发明涉及自然语言处理,尤其涉及一种基于主动学习的低资源语言机器翻译方法。
背景技术:
1、低资源语言(low-resource languages)机器翻译(machine translation,mt)任务指的是在目标语言数据量有限的情况下,利用神经网络技术进行机器翻译,以提高翻译质量和效率。在低资源环境下,机器翻译面临的主要挑战之一是可用于训练的高质量平行语料的缺乏。在传统的机器翻译框架中,大量的平行语料是必不可少的,以确保模型能够学习到从源语言到目标语言的准确映射。然而,对于许多语言对而言,这种资源的稀缺性极大限制了神经网络模型的性能。
2、尽管现有的一些方法在一定程度上取得了显著成效,但还是无法完全突破语言数据稀疏的限制。例如,当在原始数据本身质量较低时,数据增强生成的数据质量可能不高,同时数据增强方法需要额外的计算资源来生成或处理这些数据。通过迁移学习的方式时,模型可能出现灾难性遗忘,即在适应低资源语言对的同时,模型可能忘记原有的高资源语言对的知识,同时其缺点还表现出当语言之间的相似性越低,迁移学习的效果越差的现象。半监督学习最明显的缺点是未标注数据的噪声会导致模型性能下降。在低资源语言翻译中主动学习相比于上述几种方法在提升数据利用效率,加快模型收敛速度,提高模型的泛化能力具有明显优势。现有的主动学习方法有核心集(core-set,cs)、判别式主动学习(discriminative active learning,dal)、往返翻译似然(round trip translationlikelihood,rttl)。前两种方法的核心思想都是选择一个数据子集来最大化对整个数据分布的覆盖,rttl方法则是训练两个相反的模型,源句子经过这两个模型后,根据翻译的句子与源句子作对比,以此分析该数据的价值。但是目前的这些方法都存在着一些问题,dal和cs方法的问题是选择出来的数据集虽然能在一定程度上保证数据的覆盖度(多样性),但是无法满足模型对于部分类型数据的密度需求。而rttl依赖两个模型的相互翻译,这种方法不但会使计算量增加,同时还会放大数据中的噪声,对模型的性能产生干扰。
3、而主动学习(active learning,al)是一种机器学习策略,旨在从未标注的数据中主动查询最有价值的样本进行标注,以此来最大化模型性能的提升,同时最小化标注成本。因此,主动学习恰好是解决低资源语言机器翻译任务上的一种有效的方法。
技术实现思路
1、有鉴于此,本发明的目的是为了克服现有技术中的不足,提供一种基于主动学习的低资源语言机器翻译方法,以提升低资源环境下的机器翻译准确性。
2、第一方面,本技术提供了一种基于主动学习的低资源语言机器翻译方法,包括:
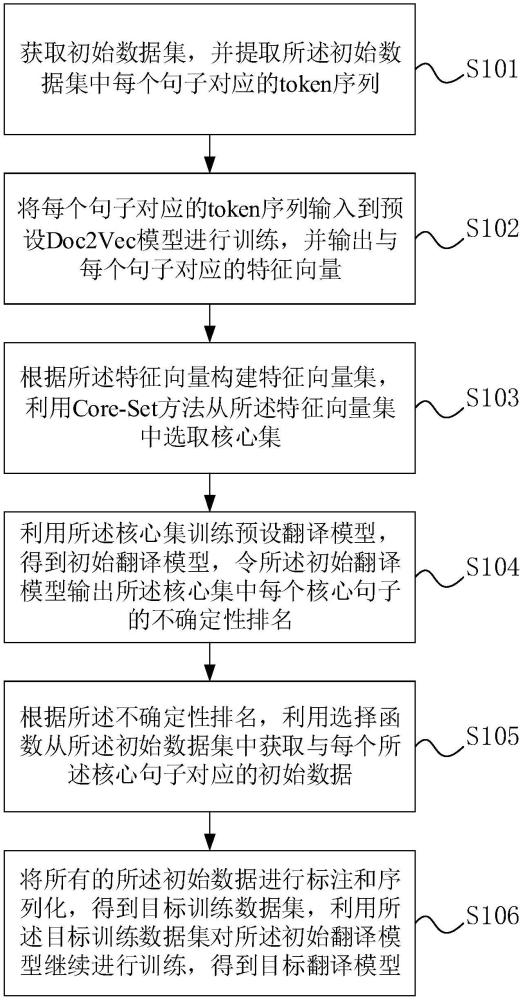
3、获取初始数据集,并提取所述初始数据集中每个句子对应的token序列;
4、将每个句子对应的token序列输入到预设doc2vec模型进行训练,并输出与每个句子对应的特征向量;
5、根据所述特征向量构建特征向量集,利用core-set方法从所述特征向量集中选取核心集;
6、利用所述核心集训练预设翻译模型,得到初始翻译模型,令初始翻译模型输出所述核心集中每个核心句子的不确定性排名;
7、根据所述不确定性排名,利用选择函数从所述初始数据集中获取与每个所述核心句子对应的初始数据;
8、将所有的所述初始数据进行标注和序列化,得到目标训练数据集,利用所述目标训练数据集对所述初始翻译模型进行训练,得到目标翻译模型。
9、在一种实施方式中,所述提取所述初始数据集中每个句子对应的token序列,包括:
10、对所述初始数据集进行数据清洗和分词操作,得到所述初始数据集中每个句子的token;
11、对所有的token进行去重并生成词典,根据所述词典将所述初始数据集中每个句子进行序列化,得到每个句子的token序列。
12、在一种实施方式中,所述预设doc2vec模型的训练过程,包括:
13、将doc2vec模型作为特征提取模型,利用所述token序列对特征提取模型进行训练,得到训练好的特征提取模型,并令训练好的特征提取模型输出与所述token序列对应的特征向量;
14、根据所述特征向量计算所述token序列的对数似然损失,判断连续多个训练迭代中对数似然损失的变化幅度是否均小于预设阈值;
15、若大于等于所述预设阈值,则调整所述初始模型的参数并继续训练;
16、若小于所述预设阈值,则将多个所述对数似然中的最大值对应的特征提取模型,作为所述预设doc2vec模型。
17、在一种实施方式中,所述对数似然计算公式为:
18、
19、其中,wt是时间步t的目标词,wt-k,…,wt+k是目标词上下文的token,d是与整个文档相关联的唯一文档向量,p(wt|wt-k,…,wt+k,d)是通过softmax函数计算。
20、在一种实施方式中,所述利用core-set方法从所述特征向量集中选取核心集,包括:
21、利用core-set方法从所述特征向量集中选取多个核心句子,利用多个所述核心句子构建初始核心集;所述初始核心集的数据分布与所述初始数据集的数据分布相同或相近;
22、对所述初始核心集中的所述核心句子进行标注,得到平行句对,将所述平行句对进行序列化操作得到所述核心集。
23、在一种实施方式中,所述令初始翻译模型输出所述核心集中每个核心句子的不确定性排名,包括:
24、利用所述初始翻译模型,获取每个所述核心句子对应的token的概率分布;
25、根据熵值计算公式,利用所述概率分布计算每个所述核心句子的熵值;
26、根据熵值大小,确定每个所述核心句子的不确定性排名。
27、在一种实施方式中,所述熵值计算公式为:
28、
29、其中,h(s)为熵值,s代表句子,n是句子中token的总数,wi代表句子中的token,e[i(wi)]表示句子中每个词语的平均信息量,e[i(wi)]是对信息量i(wi)的期望,p(wi)是模型预测的第i个词出现的概率。
30、在一种实施方式中,根据所述不确定性排名,利用选择函数从所述初始数据集中获取与每个所述核心句子对应的初始数据,包括:
31、根据所述不确定性排名,确定每个所述核心句子对应的初始数据的目标数量,所述初始数据是所述初始数据集中与所述核心句子的特征相似度最小的前n个句子;
32、利用所述选择函数,根据所述目标数量从所述初始数据集中获取所述初始数据。
33、在一种实施方式中,所述选择函数的公式为:
34、
35、或
36、
37、其中,i为不确定性排名的顺序,从0开始,m-1结束,n为总计要选择数据的条数,m为初始数据集的大小。
38、在一种实施方式中,所述利用所述目标训练数据集对所述初始翻译模型继续进行训练,得到目标翻译模型,包括:
39、将所述目标训练数据集转换为初始输入序列,通过位置编码为所述初始输入序列中的每个数据注入位置信息,得到目标输入序列;
40、将所述目标输入序列输入到所述初始翻译模型,输出与所述目标输入序列对应的目标语言句子token序列;
41、通过所述目标语言句子token序列中目标句子的对数概率评估函数,对所述初始翻译模型进行参数优化;
42、若连续对数似然差值大于预设阈值,则持续调整所述初始翻译模型的参数并继续进行训练,并在每次训练后重新评估所述对数似然;
43、若多次连续对数似然差值都小于预设阈值,则停止训练,得到目标翻译模型。
44、本发明的实施例具有如下有益效果:
45、本发明提供的一种基于主动学习的低资源语言机器翻译方法,从初始数据集的覆盖度考虑,从所述特征向量集中选取核心集,保证核心数据具备初始数据集的分布特征,然后根据模型对于此数据的输出分析得出该条数据的不确定性,根据模型对不同数据的不确定性按照选择函数动态的选择不同条数的数据,使模型更有侧重点的学习,整个过程既不丢失整个数据集的分布特征,同时还权衡了数据的覆盖度和密度,缓解了模型在最不确定数据上的数据稀疏问题,提高了低资源环境下机器翻译的准确性。
46、为使本发明的上述目的、特征和优点能更明显和易懂,下文特举较佳实施例,并配合所附附图,做详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!