开发文档智能解析方法与流程
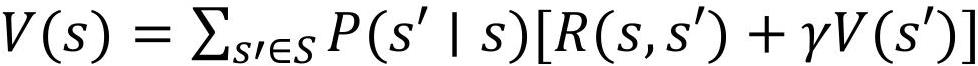
本发明属于深度学习自然语言处理领域,具体涉及一种从开发文档中解析生成结构化数据的方法。
背景技术:
1、软件开发过程中普遍存在与第三方系统对接的需求。为了实现这一需求,开发人员需耗费大量时间阅读并理解各第三方提供的开发文档,以完成对接和调试等工作。
2、传统的处理方式是开发人员需逐一查阅相关文档,通过人工方式对文档内容进行解读并完成代码的开发。这种方式不仅工作量大,而且每次改动时都需要重新阅读文档,浪费大量的时间与精力。
3、为解决上述问题,本领域技术人员往往会在阅读文档的同时根据内容整理出对应的结构化数据。此类结构化数据一般包括url地址、请求方法、请求体、响应体等信息。后续开发人员不仅可以参照整理的结构化数据进行代码的开发,也可以利用结构化数据和一些工具快速生成简单的代码。这种方式虽然在一定程度上提高了开发效率,减少了开发人员的重复性劳动,但依然存在结构化数据整理工作量大的问题。
技术实现思路
1、本发明提出了一种开发文档智能解析方法,其目的是:解决基于开发文档整理结构化数据工作量大、效率低下的问题。
2、本发明技术方案如下:
3、一种开发文档智能解析方法,该解析方法用于从开发文档中解析出结构化数据集合;所述结构化数据集合包含若干数据项,每个数据项中包含用于描述该数据项的第一属性,还包括实体属性和状态量;所述实体属性为包含若干参数项的集合,每个参数项中包含若干用于描述该参数项的第二属性;所述状态量用于指向当前编辑的实体属性;
4、定义第一类别集合和第二类别集合;所述第一类别集合中的第一类别包括用于描述数据项中第一属性的类别,还包括与实体属性对应的“包装实体”和“表格”类别以及代表无需关注内容的“噪声”类别;所述第二类别集合中的第二类别是用于描述参数项下第二属性的类别;
5、构建第一语义识别网络和第二语义识别网络,所述第一语义识别网络用于判断所输入的内容所属的第一类别,所述第二语义识别网络用于判断所输入的内容所属的第二类别;
6、构建若干关键词提取模块,各关键词提取模块分别对应不同的第一类别,关键词提取模块用于从输入的内容中提取出关键词;
7、解析步骤为:
8、步骤1、初始化结构化数据集合、段落stored和第一类别全局id,所述段落stored用于存储已读取且待处理的段落,所述第一类别全局id用于记录当前段落stored中内容所属的第一类别;
9、步骤2、将开发文档划分为多个部分,然后依次遍历每个部分,对于每个部分,分别按步骤3的方式进行处理;
10、步骤3、判断当前读取的部分是文字段落还是表格,如果是文字段落则执行步骤4、否则执行步骤5;
11、步骤4、将当前读取的文字段落作为段落current,使用第一语义识别网络得到段落current对应的第一类别,确认段落current不属于“噪声”之后,判断段落current的第一类别与第一类别全局id是否一致,一致则将段落current加入到段落stored中并结束对当前读取的部分的处理,不一致则对段落stored中的内容进行结算处理,然后将段落stored清空、将段落current加入到段落stored中,最后将段落current的第一类别作为第一类别全局id;
12、步骤5、判断段落stored是否包含内容,如果包含则依次执行步骤5-1和步骤5-2,否则直接执行步骤5-2;
13、步骤5-1、对段落stored中的内容进行结算处理,然后将段落stored清空;
14、步骤5-2、遍历处理当前读取的表格的每一行;对于当前行,先将该行内容合并为字符串,然后使用第一语义识别网络对该字符串进行识别,如果识别出的第一类别是“包装实体”或“表格”,则将该行按列分为多个单元格,并创建一个参数项;对于每个单元格,使用第二语义识别网络对单元格的内容进行识别得到所属的第二类别,然后将单元格的内容赋值到创建的参数项中与识别出的第二类别所对应的第二属性;每一行的单元格遍历完成后,将该行对应的参数项加入到当前指向的数据项中其状态量所指向的实体属性中。
15、作为所述开发文档智能解析方法的进一步改进,所述结算处理是指:如果第一类别全局id表示要开始一个新的接口的描述,则创建一个新的数据项,然后使用与第一类别全局id对应的关键词提取模块从段落stored中提取出关键词,将提取出的关键词赋值到该数据项中与第一类别全局id对应的第一属性,然后将第一类别全局id赋值到该数据项中的状态量,再将该数据项加入到结构化数据集合中并指向当前该新加入的数据项;否则,使用关键词提取模块从段落stored中提取出关键词,将提取出的关键词赋值到当前指向的数据项中与第一类别全局id对应的第一属性。
16、作为所述开发文档智能解析方法的进一步改进,所述关键词提取模块的工作过程为:从输入的内容中提取若干状态得到状态序列,然后查询训练阶段得到的状态价值集合,得到状态序列中每个状态的价值,然后根据判断规则获取到关键词在输入的内容中的位置,完成关键词的提取。
17、作为所述开发文档智能解析方法的进一步改进,所述关键词提取模块的训练过程为:
18、步骤a-1、构建训练集,训练集中的每个训练样本中分别包含一个要提取的关键词,同时标记出关键词在训练样本中的位置;
19、步骤a-2、从每个训练样本中分别提取状态,得到状态集合,并将状态集合中与训练样本中的关键词直接相邻的状态确定为终止态;
20、步骤a-3、遍历状态集合中的每个状态,为每个状态创建关联状态集合;
21、步骤a-4、设置奖励和惩罚机制,并为状态构建价值函数,通过策略迭代算法得到状态集合中每个状态的价值大小。
22、作为所述开发文档智能解析方法的进一步改进,步骤a-2中获得状态集合的过程为:
23、步骤a-2-1、从输入的内容中的第一个字开始向右遍历每一个字,对于每一个字都通过以下步骤进行处理:
24、步骤a-2-1-1、判断当前遍历到的字是否属于关键词,属于的话结束步骤a-2-1,否则将当前字作为一个状态提取出来,并将当前字作为判断范围,继续执行步骤a-2-1-2;
25、步骤a-2-1-2、在输入的内容中基于当前的判断范围向右扩展一个字得到新的判断范围,如果扩展的字属于关键词,则结束当前遍历到的字的处理,否则继续执行步骤a-2-1-3;
26、步骤a-2-1-3、将当前判断范围中的内容作为一个状态提取出来,然后跳转至步骤a-2-1-2;
27、步骤a-2-2、从输入的内容中的最后一个字开始向左遍历每一个字,对于每一个字都通过以下步骤进行处理:
28、步骤a-2-2-1、判断当前遍历到的字是否属于关键词,属于的话结束步骤a-2-2,否则将当前字作为一个状态提取出来,并将当前字作为判断范围,继续执行步骤a-2-2-2;
29、步骤a-2-2-2、在输入的内容中基于当前的判断范围向左扩展一个字得到新的判断范围,如果扩展的字属于关键词,则结束当前遍历到的字的处理,否则继续执行步骤a-2-2-3;
30、步骤a-2-2-3、将当前判断范围中的内容作为一个状态提取出来,然后跳转至步骤a-2-2-2。
31、作为所述开发文档智能解析方法的进一步改进,步骤a-3具体方式为:对于当前遍历到的状态,如果状态集合中的其它状态能够通过该状态通过向左扩展一字或向右扩展一字而得到,则将这些其它状态加入到该状态的关联状态集合中。
32、作为所述开发文档智能解析方法的进一步改进,步骤a-4中,为状态集合中的终止态设置正奖励,为状态集合中关联状态集合为空的状态设置负奖励,构建状态的价值函数为:
33、;
34、其中,是状态的价值函数,是状态的关联状态集合,是依据关联状态集合得到的从状态过渡到状态的概率,为从状态过渡到状态得到的奖励,为折扣因子。
35、作为所述开发文档智能解析方法的进一步改进,关键词提取模块从输入的内容中得到状态序列的过程为:
36、步骤b-1、按从左到右的顺序遍历输入内容中的每一个字,对每一个字分别按步骤b-2进行处理;
37、步骤b-2、从当前遍历到的字向右探索,找到能与状态集合中的状态所匹配的最长的字符串作为该字对应的状态,将该状态加入到状态序列中。
38、作为所述开发文档智能解析方法的进一步改进,步骤b-2具体包括:
39、步骤b-2-1、将当前遍历到的字作为判断范围,并创建一个状态对象;
40、步骤b-2-2、判断当前判断范围中的字符串是否与状态集合中的任一状态相匹配,如果匹配则用该状态覆盖状态对象中的值,然后执行步骤b-2-3,否则判断状态对象中是否存有有效的状态,如存在则将该状态加入到状态序列中,结束当前遍历到的字的探索;
41、步骤b-2-3、在输入的内容中从当前判断范围向右扩展一个字,然后跳转至步骤b-2-2。
42、作为所述开发文档智能解析方法的进一步改进:所述关键词提取模块中,根据判断规则获取到关键词在输入的内容中的位置时,将状态序列按每个状态的价值大小视为高度不同的山峰;先找到状态序列中价值最高的状态,将该状态定义为最高峰;再以最高峰为分界,将最高峰左侧的状态中价值最高的状态定义为左高峰,将最高峰右侧的状态中价值最高的状态定义为右高峰;并且将状态序列中的所有终结态定义为终结峰,然后按以下规则进行关键词的提取:
43、规则1、定义条件1:最高峰为终结峰,左高峰和右高峰之一也为终结峰,且最高峰在输入的内容中的字符范围与左高峰及右高峰的字符范围均不相交;
44、如果满足条件1,则将两个终结峰之间的字符作为关键词进行提取;
45、规则2、定义条件2:最高峰是终结峰,且左高峰和右高峰都不是终极峰;
46、如果满足条件2,则将左高峰和右高峰中价值最高的山峰与最高峰之间的字符作为关键词进行提取;
47、规则3、如果条件1和条件2都不满足,同时最高峰右侧不存在山峰,且在输入的内容中最高峰右侧还存在字符,则将最高峰右侧的全部字符作为关键词进行提取;
48、规则4、如果条件1和条件2都不满足,同时最高峰右侧不存在山峰,且最高峰右侧不存在字符,则将最高峰左侧的全部字符作为关键词进行提取;
49、规则5、如果条件1和条件2都不满足,同时最高峰左侧不存在山峰,最高峰左侧还存在字符,则将最高峰左侧的全部字符作为关键词进行提取;
50、规则6、如果条件1和条件2都不满足,同时最高峰左侧不存在山峰,且最高峰左侧不存在字符,则将最高峰右侧的全部字符作为关键词进行提取;
51、规则7、如果条件1和条件2都不满足,同时最高峰左右两侧均存在山峰,右高峰高于左高峰,且最高峰的字符范围与右高峰的字符范围没有相交,则将最高峰和右高峰间的字符作为关键词进行提取;
52、规则8、如果条件1和条件2都不满足,同时最高峰左右两侧均存在山峰,右高峰高于左高峰,且最高峰的字符范围与右高峰的字符范围相交,则将右高峰覆盖的字符作为关键词进行提取;
53、规则9、如果条件1和条件2都不满足,同时最高峰左右两侧均存在山峰,左高峰高于右高峰,且最高峰的字符范围与左高峰的字符范围没有相交,则将最高峰和左高峰间的字符作为关键词进行提取;
54、规则10、如果条件1和条件2都不满足,同时最高峰左右两侧均存在山峰,左高峰高于右高峰,且最高峰的字符范围与左高峰的字符范围相交,则将左高峰覆盖的字符作为关键词进行提取。
55、相对于现有技术,本发明具有以下有益效果:
56、1、本发明能够自动读取开发文档并准确提取出需要的结构化数据,从而大幅节省了开发人员阅读和整理文档所需要的时间,提高了开发效率。
57、2、本发明通过两种语义识别网络分别进行段落中内容类别的识别和表格单元格内容的识别,不仅适用于不同格式的文档,而且可以充分识别文档中的重要信息,保证解析结果的完整性。
58、3、本发明的关键词提取模块基于强化学习动态规划算法,首先定义和计算出不同状态的价值函数,然后根据段落中包含的各个状态的价值大小和判断规则自动提取出关键词,准确性高,并具有较好的适应性。
- 还没有人留言评论。精彩留言会获得点赞!