一种基于图掩码和时空扩散的地点推荐方法
本发明涉及兴趣点推荐方法,特别涉及一种基于图掩码和时空扩散的地点推荐方法。
背景技术:
1、基于位置的社交网络(lbsn)和提供基于位置的服务的应用程序的使用的激增,激发了人们对兴趣点(poi)推荐模型的日益关注。这些模型用于为用户提供涵盖广泛的服务和产品的个性化推荐。以poi为中心的推荐模型已经成为yelp、weibo和foursquare等各种签到应用程序中不可或缺的功能,旨在为用户提供基于历史数据预测的未来可能访问的地点,这种推荐在商业分析、城市规划和消费者行为研究等领域中至关重要。然而,poi推荐系统通常受限于以用户为驱动的轨迹数据的固有稀疏性和其内部复杂的时空关系,这些问题增加了推荐模型在处理这些数据时的噪声干扰和不确定性,从而降低了推荐的准确性和个性化水平。
2、在poi推荐系统中,两大主要挑战——数据稀疏性和复杂时空关系的难提取共同制约了推荐的精度和泛化性。数据稀疏性主要源于用户与地点的互动自然有限:大部分用户通常只访问有限的地点,而大量地点由于缺乏足够的用户互动而变得信息匮乏。这种互动的局限性不仅妨碍了有效用户偏好和地点特性的学习,还增加了模型在训练过程中的不确定性和过拟合风险。同时,poi之间的时空关系本质上高度复杂,数据稀疏性和轨迹数据集的低质性共同加剧了从这些关系中提取有价值信息的困难:数据稀疏性使得有效信息缺乏,而轨迹数据的低质性导致提取的时空关系常含大量噪声和不可靠信息,这进一步增加了理解这些复杂时空关系的难度。
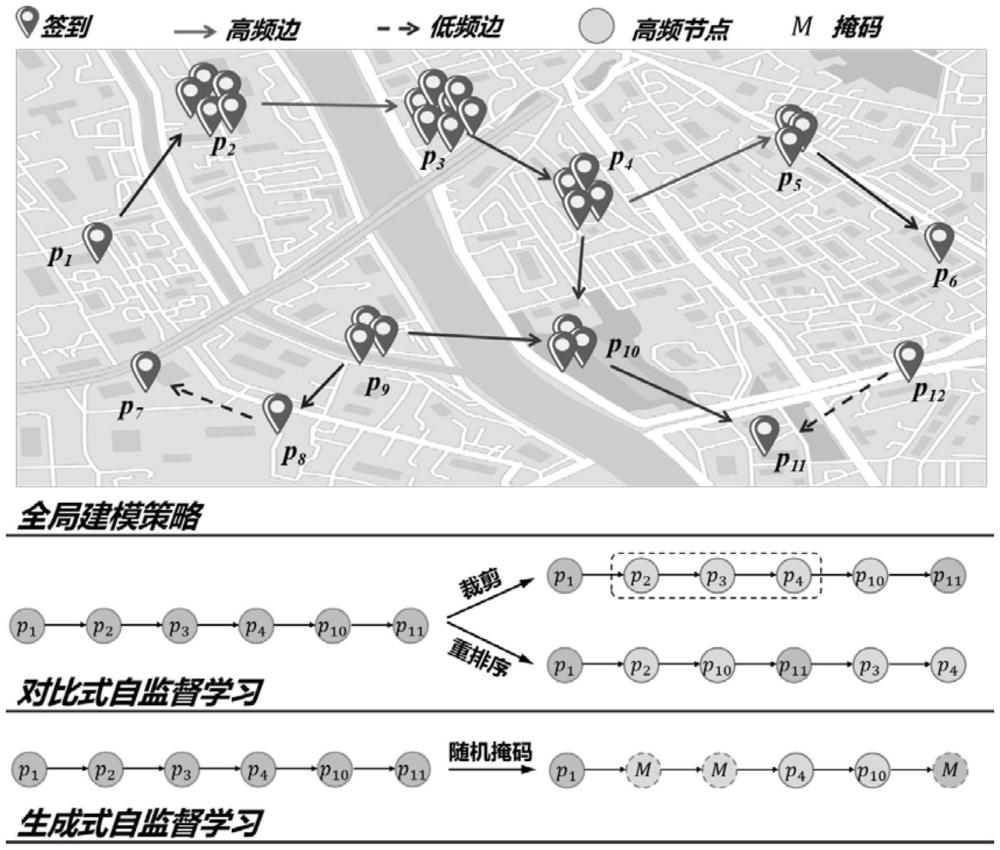
3、在现有的poi推荐系统中,图神经网络和自监督学习是解决数据稀疏性的两大主流方法。有很多研究通过使用图结构建模全局用户轨迹,从中提取通用的移动模式,以此来缓解数据稀疏性,但其在处理大量低质量的节点和边时却可能引入或加剧噪声问题,如图1中全局建模策略中的低签到poi p1、p6等以及边p8→p7、p12→p11。例如,一些研究通过构建全局用户轨迹流图捕捉广泛的用户行为模式,尽管这些方法能提升推荐系统但也可能因包含大量偶发互动的数据而使噪声问题更加显著。同时,自监督学习作为一种新兴的机器深度学习范式,通过对比任务和生成任务增强模型的学习能力,尽管可以在无需大量标签数据的情况下进行训练,但这种方法可能同时引入额外的噪声。尽管已经有大量的研究表明对比式策略可以有效提取用户偏好,但随机的数据增强可能破坏用户序列结构或图结构核心的结构信息,如图1中对比策略中的随机裁剪掉高频签到的poi或对poi交互序列的重排序会严重导致结构信息的失真。生成式自监督学习如通过预测掩码节点或边的属性,虽然有助于模型理解序列或图结构的细节,但也面临由于随机性掩码误差累积导致的噪声增加的风险,如图1中生成式中将大量高签到poi进行掩码会破坏原本的结构信息。此外,用户驱动的轨迹数据集的不完整性和时空分布的不均匀性,常导致含有大量噪声。这些噪声直接影响了模型从复杂时空关系中提取有效信号的能力,尤其是特别是在数据稀疏的环境下。尽管一些研究尝试通过时间戳和地理标签来捕捉时空关系,这种方法主要依赖简单、线性的时空关联分析,往往不能深入挖掘数据中的复杂地理和时间依赖性。同时,这种简化的处理方式也未能有效区分信号与噪声,可能导致误将噪声解释为有效信号。
技术实现思路
1、针对现有技术存在的上述问题,本发明要解决的技术问题是:数据稀疏性对poi推荐准确性的影响。
2、为解决上述技术问题,本发明采用如下技术方案:一种基于图掩码和时空扩散的地点推荐方法,包括如下步骤:构建msdrec,msdrec包括全局轨迹流图掩码自监督学习模块,时空扩散去噪模块,全局poi表示融合层、嵌入层和transformer编码器;
3、s1:所述全局轨迹流图掩码自监督学习模块通过构建全局轨迹流图,通过节点重要性采样和多跳掩边采样,识别并遮掩关键连接得到全局转移掩码图之后,通过三个自监督解码任务重构关键连接。
4、s1-1:构建全局轨迹流图,给定全局用户的所有历史轨迹定义一个有向带权图为全局轨迹流图其中表示节点集合,即poi集合,em表示边集合,ωm表示边在中出现的次数。
5、s1-2:节点重要性采样,对于任意poi节点u∈vm,计算节点u及其k阶邻居的嵌入变化,以得到节点u的重要性得分取得分最高的前m个节点作为候选节点添加到锚节点集合va中,va=topm{v|v∈v},其中topm表示最高的前m个节点。
6、s1-3:多跳掩边采样,定义全局的采样过程,任意两个节点对之间的边采样概率p(e)表示为:
7、
8、其中pu,v表示节点u到节点v的路径采样概率,p0表示基础采样概率,λ表示控制信息衰减的衰减因子,0<λ≤1,ku,v表示节点u与节点v之间的跳数。
9、采样后得到一个全局转移掩码图其中表示去除掩边后的边集作为后续解码任务的目标,表示去除掩边后的边权重集。
10、s1-4:通过基于gcn的图编码器得到的掩码表示hm,设计度数解码器、边存在性解码器和边权重解码器三个解码器进行解码。
11、度数解码器用于预测中每个节点的连接数,边存在性解码器用于确定中任意两节点间是否存在边,边权重解码器用于预测中已存在边的权重。
12、s2:所述时空扩散去噪模块通过构建全局时间图和全局空间图,并使用扩散模型对时空表示去噪增强最终得到去噪后的全局时空数据
13、s2-1:构建全局时间图和全局空间图,全局时间图和全局空间图都是通过整合所有用户轨迹s得到的有向带权图。其中全局空间图反映了空间位置转换模式的全局视图,而全局时间图收集了时间位置转换模式,其中vs和vt均是poi签到节点集,es和et是包含所有连接两个不同节点的加权边集,ωs和ωt分别代表了和的权重。
14、s2-2:扩散模型的正向扩散和逆向扩散,利用图卷积网络gcn编码器分别对全局时间图和全局空间图进行处理,以独立地提取空间poi表示hs和时间poi表示ht,对hs和ht进行融合得到全局时空poi表示hst,
15、扩散过程:在正向过程中,高斯噪声逐渐增加到hst中,直到hst最终完全转变为高斯噪声et。相反,逆向扩散过程利用可训练的去噪器去除噪声,经过不断迭代的扩散过程得到训练好的扩散模型
16、s2-3:扩散的推理过程利用对全局时空信息hst去噪得到
17、s3:全局poi表示融合层,将得到hm和进行融合得到hf。
18、s4:嵌入层,每个poi都被分配了一个本发明前面通过掩码模块和扩散增强模块所得到的最终嵌入hp∈hf。任意的用户的历史访问序列的初始嵌入通过如下获得:
19、
20、其中,hl表示用户访问序列中签到地点的嵌入表示,pl表示中第,个签到地点的位置嵌入。
21、s5:使用transformer编码器推荐用户最终的序列偏好嵌入根据对下一个可能的poi进行打分,实现预测。
22、使用有自监督的方式对msdrec进行训练,当损失不再变化时,保留模型的当前参数。
23、s6:对于一个新用户z,获取z的历史轨迹并将输入训练完成后的最优msdrec中,最优msdrec会根据其历史轨迹计算出z的轨迹偏好以及所有n个poi的嵌入表示hf=(h1,h2,……,hn),之后通过计算得到所有poi的偏好得分之后对scoren进行排序,得分最高的poi即为新用户z推荐的poi。
24、进一步的,所述s1-2中,计算重要性得分的过程如下:
25、
26、其中subk(u)代表节点u的k阶子图,对于u子图的任意节点v,表示其在时间步t的嵌入表示,||·||2表示欧几里得范数。
27、进一步的,所述s1-4中,得到的掩码表示hm的过程如下:
28、对的邻接矩阵进行拉普拉斯标准化,n代表poi的个数,标准化的计算过程如下:
29、
30、其中,d为的度矩阵,i为单位矩阵。
31、采用多层图卷积网络gcn对标准化后的进行编码,gcn的每一层通过邻域聚合的方式更新节点嵌入,其公式为:
32、
33、其中,为第l层的节点特征矩阵,为第l层的权重矩阵。
34、对各层输出的节点嵌入进行累加,得到节点u的最终表示为:
35、
36、其中,表示节点u的最终掩码表示,是节点u在第l层图卷积后的表示,所以最终的掩码表示为hm,任意节点u∈vm,其嵌入表示
37、进一步的,所述s1-4中,三个解码器进行解码的过程为:
38、度数解码器:对于中的任意节点u∈vm,定义度数解码如下:
39、
40、其中,代表对节点u的度数预测结果,decoderd代表的是节点度数解码器,relu为激活函数,mlp为多层感知器。
41、边存在性解码器:对于中的掩边(u,v),其节点表示为和使用mlp处理节点对的嵌入,并通过sigmoid激活函数来预测边的存在概率:
42、
43、其中,代表对边(u,v)存在性的预测,decodere代表的是边存在性解码器,⊙是元素乘积,表达节点间相互作用的强度。
44、边权重解码器:对于中的掩边(u,v),其节点表示为和使用mlp处理节点对的嵌入,选择使用relu激活函数来预测边的权重:
45、
46、其中,代表对边(u,v)权重的预测,decodere代表的是边权重解码器,⊙代表元素乘积。
47、进一步的,所述s2-1中,构建ωs和ωt的过程如下:
48、遍历所有轨迹如果两个poi和在序列中连续出现,则表明发生了位置转换。收集所有用户轨迹中的位置转换,评估空间和时间间隔,根据公式(20)和(21)构建和
49、
50、其中表示任意一条边(u,v)的权重,表示任意一条边(u,v)的权重,δd表示空间间隔阈值,表示时间间隔阈值,分别表示用户从节点i转移到节点,的空间间隔和时间间隔。
51、进一步的,所述s2-2中,扩散模型的正向扩散和逆向扩散过程如下:
52、正向扩散过程中,迭代地应用了t个噪声步骤,其中t是一个超参数,在t步时的数据被记为et,第0步的数据是原始数据,即令e0=hst。
53、使用一个在smin到smax两个超参数之间的线性插值序列s生成βt:
54、βt=1-st/st-1,s=(1,smax,......,smin) (23)
55、et通过如下公式得到:
56、
57、其中,重新参数化
58、逆向扩散过程:使用可学习的神经网络来估计以下条件概率:
59、p(et-1|et)=n(et-1;μθ(et,t),∑θ(et,t)) (25)
60、其中,μθ(·),∑θ(·)表示带有可学习参数θ的神经网络,用于估计高斯分布的参数。将第t步的嵌入与特定时间步的嵌入拼接作为输入。该网络由两个全连接层组成:
61、μθ(et,t)=fc2(et|ht),fc(x)=δ(wx+b) (26)
62、其中,fc2代表两个连续的全连接层。表示在第t步扩散中的节点嵌入向量,而表示第t时间步的嵌入。δ(·),w和b分别指的是激活函数、线性变换的权重,以及全连接层的偏置向量。
63、进一步的,所述s2-3中,得到的过程如下:
64、时空信息增强器以hst作为输入,跳过前向噪声扩散过程,在去噪步骤中,通过更新来迭代进行扩散增强,其中定义如下:
65、
66、根据和t并且使用来预测使用对时空信息hst进行去噪得到去噪时空表示
67、进一步的,所述s3中,得到hf的过程如下:
68、
69、其中,w表示可学习的聚合矩阵,
70、进一步的,所述s5中,transformer编码器中的多头注意力机制如下:
71、多头自注意力模块公式如下表达:
72、
73、其中,l和h分别代表多头注意力模块和头的数量。headh代表第h个头的得分。表示用户在第l层的特征表示,是第h个头在注意力机制中对应于查询、键和值的投影矩阵。concat(·)拼接操作,代表用户第l层的最终表示。w1,w2,b1,b2构成了前馈神经网络。通过残差连接得到最终的序列嵌入
74、进一步的,所述s5中,损失的计算过程如下:
75、度数解码器通过均方误差损失函数来优化,度数解码损失为:
76、
77、其中,代表度数解码器对节点u的度数预测,du是该节点的实际度数,n是图中节点的总数。
78、边存在性解码器使用二元交叉熵损失函数,边存在性解码损失为:
79、
80、其中,eneg表示选取的不存在的边的负样本集,表示边(u,v)的实际存在的得分,是负样本得分。
81、边权重解码器采用均方误差损失函数来优化,的权重解码损失为:
82、
83、其中,是边权重解码器预测的边(u,v)的权重,是边的实际权重,|e|是中边的总数。
84、
85、其中,log p(e0)即elbo,为重构项,pθ(et|e0)为训练好的去噪器,q(et|e0)为真实分布,t为预先设置好的扩散步数超参数。
86、去噪匹配项的目的是最小化真实分布q(et-1|et,e0)和去噪器pθ(et-1|et)之间的kl散度。
87、第t个时间步长的去噪匹配项定义如下,表示为:
88、
89、其中,表示对初始嵌入e0的预测,重建项表示为预测值和真实嵌入向量e0之间的平方损失,即扩散损失定义如下:
90、
91、对于用户优化推荐任务的损失定义为:
92、
93、其中代表用户u轨迹序列的嵌入,代表真实签到的嵌入,并且是随机选取的用户没有访问过的负样本;
94、
95、相对于现有技术,本发明至少具有如下优点:
96、本发明提供了一种新颖的poi推荐方法msdrec,它结合了基于图掩码的自监督学习和时空扩散技术,来缓解用户驱动的轨迹数据集稀疏性以及精准提取其中复杂时空关系。该方法有效地整合了全局轨迹图中的核心结构信息与精炼的时空嵌入,确保在稀疏和噪声数据环境中能够提供稳健和精准的推荐。通过在真实世界的数据集上进行全面的实验,证明了msdrec超越了现有的先进模型。通过整合创新的组件——图掩码自监督学习和时空扩散技术,msdrec在处理稀疏数据和噪声问题时显示了特别的优势,能够提供更深层次和准确的推荐。
- 还没有人留言评论。精彩留言会获得点赞!