一种视觉语言结构化空间的规划方法、系统、设备及介质
本技术涉及视觉语言智能,尤其涉及一种视觉语言结构化空间的规划方法、系统、设备及介质。
背景技术:
1、具身问答(embodiedqa)任务的核心目标是使智能体能够在现实环境中理解并执行人类指令,动态决策并与环境互动。例如,智能体需要根据指令找到物品、整理物品或回答关于环境的问题。
2、近年来,基于llms的实体智能体得到了快速发展,llms的推理能力使智能体能够处理复杂指令并生成行动计划。然而,这些智能体在具身问答任务中仍面临环境理解不足、幻觉问题和可解释性等挑战。
技术实现思路
1、本技术提供一种视觉语言结构化空间的规划方法、系统、设备及介质,其解决了在具身问答任务中仍面临环境理解不足、幻觉问题和可解释性的技术问题,达到了更好地应对复杂任务,提升解决能力和可解释性的技术效果。
2、为了达到上述目的,本技术采用的主要技术方案包括:
3、第一方面,本技术实施例提供一种视觉语言结构化空间的规划方法,应用于具身智能体,所述方法包括:
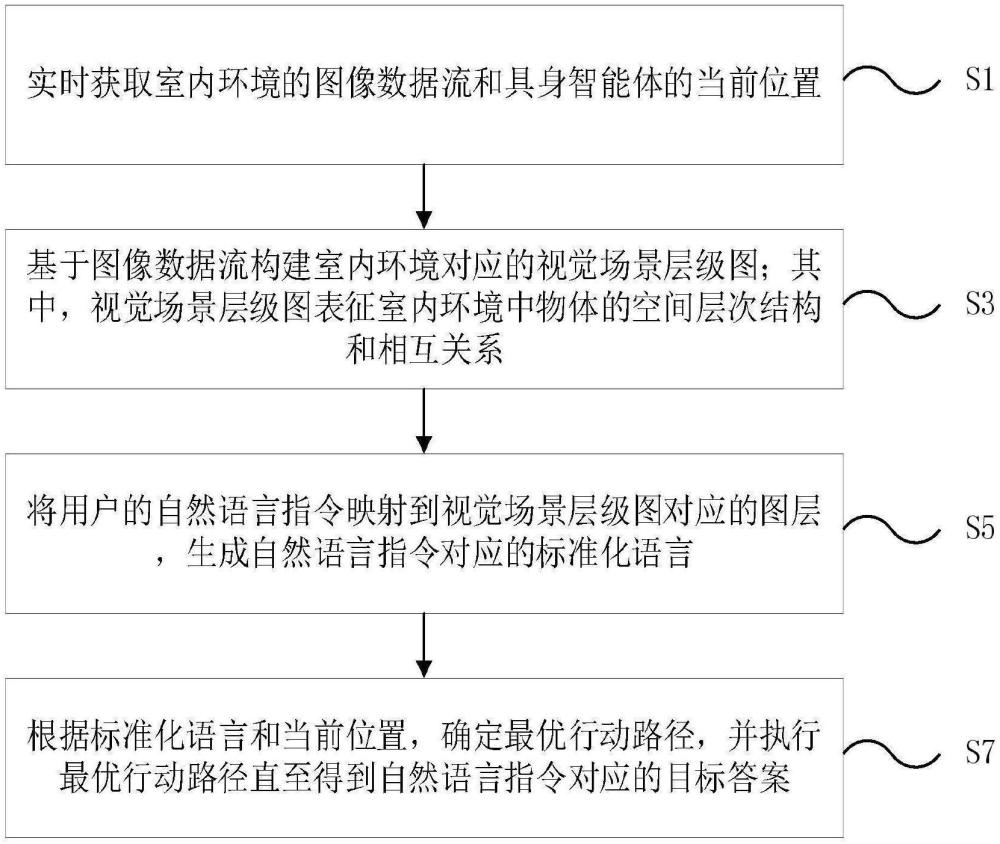
4、实时获取室内环境的图像数据流和所述具身智能体的当前位置;
5、基于所述图像数据流构建所述室内环境对应的视觉场景层级图;其中,所述视觉场景层级图表征所述室内环境中物体的空间层次结构和相互关系;
6、将用户的自然语言指令映射到所述视觉场景层级图对应的图层,生成所述自然语言指令对应的标准化语言;
7、根据所述标准化语言和所述当前位置,确定最优行动路径,并执行所述最优行动路径直至得到所述自然语言指令对应的目标答案。
8、本实施例提供的一种视觉语言结构化空间的规划方法,通过实时获取室内环境的图像数据流以及具身智能体的当前位置,实现了对室内环境的实时感知和定位。接着通过基于图像数据流构建室内环境的视觉场景层级图,该层级图表征了室内环境中物体的空间结构和相互关系。能够将环境信息从视觉层面上进行高度抽象和组织,有助于具身智能体理解环境的空间布局、物体的相对位置,以及它们之间的关系。然后将用户的自然语言指令映射到视觉场景层级图对应的图层,并生成标准化语言。能够将自然语言指令转化为机器可理解的标准化表达,并将其与空间层级图关联。这一过程使得人机交互更加自然,用户通过简单的语言即可指令具身智能体执行任务,同时避免了语言歧义和误解问题。最终根据标准化语言和当前位置确定最优行动路径,并执行该路径,直到目标答案获得。确保了具身智能体能够高效、准确地完成任务,避免了路径规划中的冗余或无效动作,提高了操作效率和任务执行的成功率。
9、可选地,所述基于所述图像数据流构建所述室内环境对应的视觉场景层级图,包括:根据所述图像数据流,确定所述室内环境中不同层级的物体以及物体之间的空间关系和层级关系;
10、将所述物体确定为节点,所述空间关系和所述层级关系确定为边;
11、根据所述节点和所述边,构建不同图层的所述视觉场景层级图。
12、本实施例通过图像数据流识别物体及其空间关系,为后续处理提供精准的环境感知基础;其次,通过将物体及其关系转化为图模型,使得能够高效存储和处理这些信息;最后,构建视觉场景层级图,通过分层表示提升对复杂场景的全面理解。从而显著提高了室内环境建模的精度和效率,为智能交互、导航等应用提供了强有力的支持。
13、可选地,所述视觉场景层级图包括地板层、房间层、非移动物体层和移动物体层;其中,
14、所述地板层为所述视觉场景层级图的最高层,所述地板层包括多个所述房间层;
15、所述房间层为所述室内环境中的各个房间,每个所述房间层包含所述非移动物体层和移动物体层;
16、所述非移动物体层为所述房间内不可移动的物体;
17、所述移动物体层为所述房间内可移动的物体。
18、可选地,所述将用户的自然语言指令映射到所述视觉场景层级图对应的图层,生成所述自然语言指令对应的标准化语言,包括:
19、获取用户的自然语言指令,并识别所述自然语言指令的关键词;
20、根据所述关键词,确定所述自然语言指令对应的询问对象和询问关系;
21、将所述询问对象和所述询问关系映射到所述视觉场景层级图对应的图层,生成所述自然语言指令对应的标准化语言。
22、本实施例通过获取用户的自然语言指令并识别其中的关键词,实现了对用户意图的初步识别和信息提取。能够自动识别用户输入中的关键信息,为后续处理提供基础。接着通过分析关键词来确定自然语言指令对应的询问对象和询问关系,将用户的需求转化为具体的图层和结构。能够将自然语言指令与视觉场景中的具体物体或关系建立联系,从而明确用户的具体查询内容。然后将询问对象和询问关系映射到视觉场景层级图中,并生成标准化语言。通过对视觉场景的图层结构的精确映射,能够将自然语言转化为计算机系统能理解和处理的标准化表达,增强了自然语言与视觉数据的融合,提升了交互的智能性和准确性,支持具身智能体在复杂视觉环境中进行精准查询和操作。
23、可选地,所述执行所述最优行动路径的过程中,所述方法还包括:
24、根据预设的视觉感知条件确定所述当前位置是否满足视野要求;
25、在不满足视野要求的情况下,调整视野角度直至满足所述视野要求。
26、本实施例通过根据预设的视觉感知条件判断当前位置是否满足视野要求,实现对当前视野的智能感知与评估。能够根据预设条件自动评估视野是否符合需求,从而判断是否需要进行视野调整。这增强了具身智能体的自适应能力,使其能够灵活应对不同的视觉感知需求。在当前视野不满足要求时,通过自动调整视野角度来确保视野条件得以满足。能够动态调整视野角度,确保观察区域的适应性和完整性。避免了用户手动调整视角的繁琐,提高了用户体验。
27、可选地,所述确定所述当前位置是否满足视野要求通过多模态大模型进行判断;其中,所述多模态大模型包括chatgpt、llm中的至少一种。
28、可选地,所述方法还包括:
29、在所述自然语言指令中包含指示目标物体的物体属性情况下,利用llms模型根据所述物体属性确定预判感知结果;其中,所述预判感知结果用于表征远程感知或近距感知;
30、基于所述预判感知结果,生成行动计划,以指导所述具身智能体接近所述目标物体。
31、本实施例利用llms模型根据自然语言指令中的物体属性来预判感知结果,能够通过自然语言中的物体属性信息提前预测感知结果,无论是远程感知还是近距感知。这种预判感知能够帮助具身智能体更高效地识别目标物体的位置、特征或状态,从而为接下来的行动做出智能决策,减少实时感知中的不确定性。基于预判感知结果生成行动计划,指导具身智能体接近目标物体。能够根据先前的感知预判来制定合适的行动路径,从而确保具身智能体能更精确地接近目标物体。这种行动计划不仅优化了行动过程,还使得具身智能体能更好地应对不同的环境与任务需求,提高任务完成的效率和准确性。
32、第二方面,本技术实施例提供一种视觉语言结构化空间的规划系统,应用于具身智能体,所述系统包括:
33、数据获取单元,用于实时获取室内环境的图像数据流和所述具身智能体的当前位置;
34、图构建单元,用于基于所述图像数据流构建所述室内环境对应的视觉场景层级图;其中,所述视觉场景层级图表征所述室内环境中物体的空间层次结构和相互关系;
35、指令映射单元,用于将用户的自然语言指令映射到所述视觉场景层级图对应的图层,生成所述自然语言指令对应的标准化语言;
36、路径确定单元,用于根据所述标准化语言和所述当前位置,确定最优行动路径,并执行所述最优行动路径直至得到所述自然语言指令对应的目标答案。
37、第三方面,本技术实施例提供一种计算机设备,包括:
38、存储器和处理器,所述存储器和所述处理器之间互相通信连接,所述存储器中存储有计算机指令,所述处理器通过执行所述计算机指令,从而执行上述所述的视觉语言结构化空间的规划方法。
39、第四方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机指令,所述计算机指令用于使计算机执行上述所述的视觉语言结构化空间的规划方法。
- 还没有人留言评论。精彩留言会获得点赞!