一种面向低质量数据场景的兴趣点推荐方法
本发明属于兴趣点推荐,主要涉及一种面向低质量数据场景的兴趣点推荐方法。
背景技术:
1、随着全球定位系统和web2.0技术的飞速发展,基于位置的社交网络(location-basedsocialnetworks,lbsns)相关研究逐渐兴起。lbsns通过用户之间的签到分享,为用户提供了一种独特的社交互动方式,结合智能手机的广泛普及,使这些lbsns平台的用户数量迅速增长,已达到数十亿规模。然而,这种信息过载现象给用户带来了挑战,使他们很难快速准确地找到符合自身兴趣和需求的信息。为了解决这一问题,兴趣点推荐成为了一个热门的研究方向。
2、然而,兴趣点推荐系统面临严峻的数据稀疏性问题,在lbsn平台提供的海量兴趣点中,用户实际能够访问的兴趣点数量极为有限,导致数据集异常稀疏。因此,许多研究提出使用数据增强的手段提高训练数据规模和质量,从而提升推荐系统的推荐性能。目前,传统的兴趣点签到序列数据增强方法往往忽略了数据在时空维度上的均匀性,这一问题可能会对兴趣点推荐任务的准确性产生影响。一方面,用户签到序列可能存在数据缺失或时间间隔过大的问题,或者两次签到记录之间的时间间隔过长。这种不均匀性可能导致模型对于某些时间间隔内的用户兴趣和行为模式理解不足,从而影响推荐结果的个性化和精确度。另一方面,用户签到序列中的地理位置数据常常呈现长尾分布,使得推荐系统倾向于推荐热门地区,而忽略了长尾地区的推荐,进而导致地理位置推荐缺乏多样性和个性化。
技术实现思路
1、针对上述现有技术存在的不足,本发明提出一种面向低质量数据场景的兴趣点推荐方法,使用时空数据增强手段,从时间均匀性和空间均匀性两个方面实现用户兴趣点签到序列增强,使模型能更好的提取用户签到序列之间的时空特性,强化个性化推荐效果。
2、本发明的技术方案为:
3、一种面向低质量数据场景的兴趣点推荐方法,该方法包括:
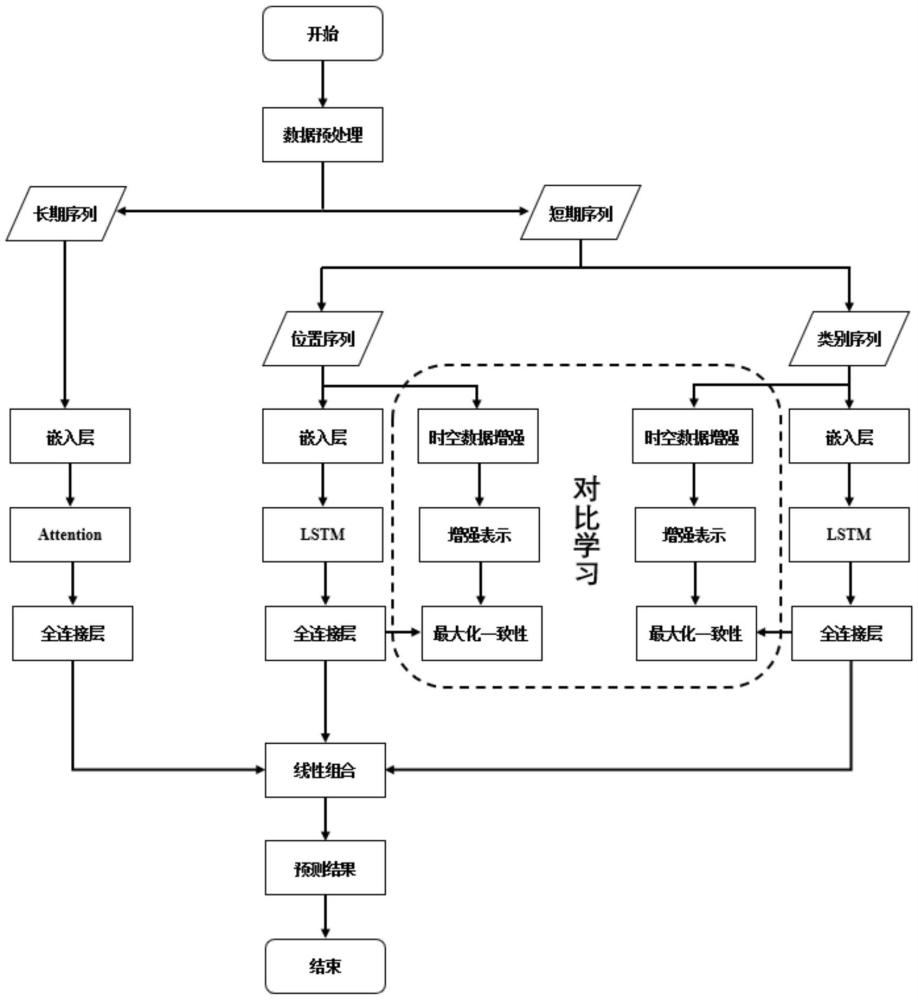
4、步骤i:预处理数据集,首先对用户的签到数据进行系统的预处理,以确保数据的质量和一致性,然后按时间序列对数据集进行划分,将用户签到数据划分为长期序列和短期序列;
5、所述数据集,是指某一基于位置的社交网络中用户的签到数据构成的集合,其中包含签到数据所涉及的用户id、兴趣点id、兴趣点类别id、兴趣点类别、兴趣点所在位置经度坐标、兴趣点所在位置纬度坐标、兴趣点所在位置时区、用户在兴趣点签到的时间。
6、所述签到,是指用户在某时刻与兴趣点交互的行为。
7、所述用户的签到序列,是指将用户的历史签到按签到时间的先后进行排序得到的序列其中,u表示用户,n表示用户u在数据集中的签到总数,q表示三元组(l,c,ts),其中,l表示兴趣点id,c表示兴趣点类别id,ts表示用户u在兴趣点签到的时间戳。
8、所述长期序列,是指数据集中该用户的完整签到数据
9、所述短期序列,是指将qu划分为一系列长度为k的子序列,每个子序列可以表示为
10、步骤ii:学习用户的长期偏好。首先,将用户的长期序列lu输入嵌入层,获得兴趣点的融合特征向量;其次,鉴于同一兴趣点对不同的用户的影响可能存在不同,本发明使用注意力机制(attention)计算兴趣点在长期序列中的特征权重,进而基于特征权重捕捉用户的长期爱好。
11、步骤iii:学习用户短期偏好。本发明使用用户的短期序列su来学习用户的短期偏好。由于位置和类别在特定时间段内对用户的偏好有不同的影响,本发明将位置和类别分别输入到两个不共享参数的长短期记忆网络(long short-term memory,lstm)来分别学习位置级和类别级偏好。
12、步骤iv:使用对比自监督学习增强模型表征能力。首先,计算兴趣点之间的相关性并利用项目相关性缓解对原始序列的扰动;其次,提出新的鲁棒序列增强方法,从时间和空间两个角度构建增强数据;最后,通过统一对比自监督学习任务和推荐任务,解决数据稀疏性和噪声交互问题。
13、所述对比自监督学习,是指通过未标记的数据生成增强样本,并通过使用对比损失增强编码器的识别能力。对比损失使正对之间的一致性最大化,其中正对是一个实例的增广视图与原视图的配对。
14、步骤v:结合用户的长短期偏好生成推荐结果。在输出层,将长期和短期的输出进行融合,同时,为了更好地学习个性化偏好,模型通过学习每个用户的加权向量,来平衡长期偏好、位置级偏好和类别级偏好的重要性,从而生成候选兴趣点的最终推荐概率。
15、进一步地,根据所述的面向低质量数据场景的兴趣点推荐方法,所述步骤i包括如下步骤:
16、步骤i-1:基于时间间隔均匀性对数据集重新编号排序。将原数据集中的一部分视为“时间间隔均匀”,无须构建增强,以便在对数据集进行时空数据增强的同时尽量减小对原数据集的扰动。对原数据集按用户id(userid)分组,计算每个userid对应的时间间隔标准差δt,对userid按其对应的δt排序并编号,编号越小的userid,其签到数据的时间间隔越均匀。将userid编号前α%的数据视为“均匀”。
17、步骤i-2:数据去重。首先,去除数据集中完全重复的签到记录;其次,考虑到同一个兴趣点id所属的兴趣点种类不一定相同,对兴趣点id对应的兴趣点种类进行类别归一化处理。
18、步骤i-3:划分数据集。将用户完整的签到数据lu视为长期序列并生成所需的数据,从中学习用户的长期偏好。将用户的签到数据划分为一组长度为k的su视为短期期序列并生成其他所需数据,从中学习用户的短期偏好。
19、进一步地,根据所述的面向低质量数据场景的兴趣点推荐方法,所述步骤ii包括如下步骤:
20、步骤ii-1:通过嵌入层获得兴趣点的融合特征向量。由于时间戳表示的信息是连续的,难以嵌入,因此,本发明将原始数据的时间戳映射为离散的小时,然后将每个小时表示为一个d维的向量。将用户id,兴趣点id,兴趣点类别id表示为独热向量,并分别嵌入为维度是du、dl、dc的向量。为了在每个用户的长期序列中学习兴趣点的高级表示,本发明利用非线性变换来捕获每个兴趣点的潜在向量。
21、步骤ii-2:利用注意力机制计算兴趣点在长期序列中的特征。本发明使用嵌入层学习到的用户嵌入向量来度量用户偏好和兴趣点的融合特征向量之间的相似度。首先计算每个用户的每个兴趣点的重要性,本发明中,每个兴趣点的重要性被定义为用户u的嵌入向量和兴趣点的融合特征向量之间的归一化相似度,然后,通过融合不同权重兴趣点的潜在向量来学习用户的长期偏好,最后将用户的长期偏好输入到一个全连接层中,计算下一个兴趣点的概率。
22、进一步地,根据所述的面向低质量数据场景的兴趣点推荐方法,所述步骤iv包括如下步骤:
23、步骤iv-1:计算兴趣点之间的相似度,构建时空数据增强时需要兴趣点之间的相似度以降低对原始序列的扰动,因此,有必要设计一种简单有效的方法来计算兴趣点之间的相似度。首先计算兴趣点之间的静态相似度,然后计算兴趣点之间的动态相似度,最后将二者相加得到兴趣点之间相似度的最终量化表示结果;
24、步骤iv-2:构建时空增强数据,通过对原始数据的时间和空间构建增强,得到时空均匀的新序列;
25、步骤iv-3:通过对比自监督学习优化编码器。
26、进一步地,根据所述的面向低质量数据场景的兴趣点推荐方法,所述步骤iv-1包括如下步骤:
27、步骤iv-1-1:计算兴趣点之间的静态相似度:
28、静态相似度是基于记忆的相似度,采用逆用户频率的基于项目的协同过滤(itemcf-iuf)来衡量兴趣点之间的相似度,即静态相似度认为如果两个兴趣点共享更高比例的公共用户,则这两个兴趣点之间的相似度更高。
29、步骤iv-1-2:计算兴趣点之间的动态相似度:
30、动态相似度是基于模型的相似度,通过计算兴趣点的表示之间的相似度推断出兴趣点之间的相似度。
31、步骤iv-1-3:计算兴趣点之间最终的相似度:
32、将兴趣点之间的静态相似度和动态相似度相加,结果定义为兴趣点之间最终的相似度。
33、进一步地,根据所述的面向低质量数据场景的兴趣点推荐方法,所述步骤iv-2包括如下步骤:
34、步骤iv-2-1:构建时间数据增强:
35、在用户签到序列的时间间隔最大的两个兴趣点之间插入目标兴趣点,使得原始序列中最大的时间间隔dt被新序列中的新时间间隔dt/2取代,新序列时间间隔的分布更加均匀。
36、步骤iv-2-2:将时间数据增强与空间数据增强结合:
37、本步骤的目标是在新序列的时间间隔更均匀的前提下,尽量使其空间间隔也均匀。由于步骤iv-2-1确定了插入位置,本步骤的目的在于目标兴趣点的选取。首先根据步骤iv-1所述相似度选择β个备选兴趣点,随后将这β个备选兴趣点分别插入原始序列得到β个备用新序列,计算这β个备用新序列的空间间隔均匀度,选择能使新序列的空间间隔最均匀的兴趣点作为目标兴趣点。最终,得到时空间隔分布都均匀的新序列。
38、步骤iv-3:通过对比自监督学习优化编码器:
39、对比自监督学习通过最大化实例的不同视图之间的一致性来训练编码器。首先定义模型的对比损失函数,最小化对比损失函数以进行参数学习。
40、进一步地,根据所述的面向低质量数据场景的兴趣点推荐方法,所述步骤v包括如下步骤:
41、步骤v-1:基于用户的线性组合单元:
42、首先在输出层使用基于用户的线性组合单元把用户的长期偏好和短期偏好结合起来计算下一个兴趣点的概率,最后,对概率归一化处理。
43、步骤v-2:利用联合学习策略辅助推荐任务:
44、将推荐下一个兴趣点的任务作为主任务,对比自监督学习任务作为辅助任务共同学习,通过反向传播更新模型参数训练模型。
45、本发明与现有技术相比,具有以下明显的优势和有益效果:
46、相比常规方法,对低质量数据集的推荐效果更准确。本发明针对时空数据增强在推荐模型中的应用进行了系统研究,显著提升了模型在实际推荐场景中的泛化能力,使其能够更好地适应和处理多样化的用户行为数据和场景信息。所提出的技术和方法在推荐系统中具有广泛的应用潜力,尤其在电商、社交媒体和内容推荐等领域。通过有效的时空数据增强策略,可以在用户行为预测、个性化推荐和用户体验优化等多个场景中,显著提升推荐系统的整体性能和用户满意度。同时,采用联合策略,在保证时空特征分布均匀的基础上,进一步提高了推荐结果的相关性和准确性。实验证实,本发明提出的模型可以在foursquare nyc数据集上实现20.84%的平均识别精度map@20(mean average precision,map)。因此,这种综合方法使得我们能够在应用于低质量数据集时获得更为优秀的推荐结果,为推荐系统的性能提升提供了有力支持。
- 还没有人留言评论。精彩留言会获得点赞!