基于可用性评估的自适应个人信息脱敏方法与系统
本发明属于个人信息脱敏,尤其是涉及基于可用性评估的自适应个人信息脱敏方法与系统。
背景技术:
1、现有的个人信息脱敏系统通常包含以下几个主要步骤:输入原数据、敏感信息识别、数据脱敏、脱敏数据输出。这些系统往往只关注对数据脱敏的有效性,即通过各种事先选定的脱敏算法对待脱敏数据进行脱敏,使得脱敏后的数据尽量不泄露原数据中包含的敏感个人信息。然而,脱敏后的数据还会用于后续的数据分析,若原数据经过脱敏后丢失了大量其中包含的有价值信息也是不合适的。因此,对于数据的脱敏,也应关注其脱敏后的数据包含的有价值信息量,即脱敏后的数据的可用性。现有的个人信息脱敏系统大多缺乏对脱敏后数据的可用性评估与反馈机制,因此无法很好地平衡数据隐私与数据可用性两方面。
技术实现思路
1、本发明的目的是针对上述问题,提出一种基于可用性评估的自适应个人信息脱敏方法与系统。
2、一种基于可用性评估的自适应个人信息脱敏方法,该方法包括:
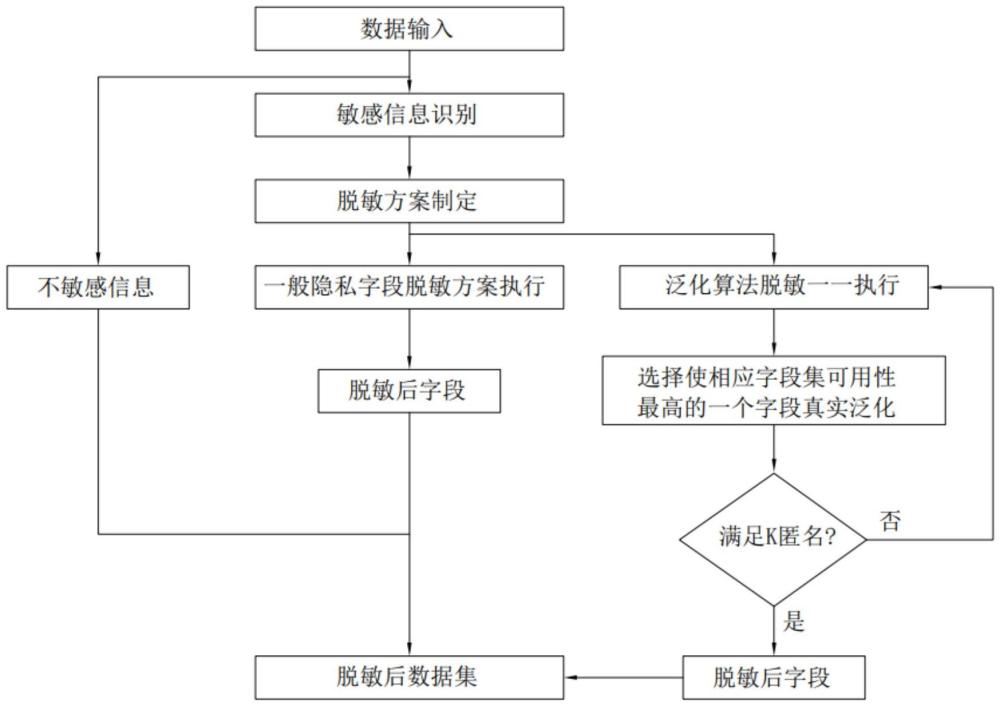
3、s1.敏感信息识别,接收待脱敏的原数据集并识别隐私字段;
4、s2.脱敏方案制定,为隐私字段制定相应的脱敏策略,且至少两个字段被指定使用泛化算法,通常对准标识符指定泛化算法的脱敏方法;
5、s3.脱敏方案执行,对于指定了泛化算法的隐私字段,循环选择其中使相应字段集可用性最高的一个字段进行泛化直至满足k匿名;
6、对于其余隐私字段,根据制定的脱敏策略对相应的隐私字段进行脱敏处理;
7、s4.合并其余隐私字段和指定泛化算法的隐私字段的脱敏结果得到脱敏后数据集。
8、在上述的基于可用性评估的自适应个人信息脱敏方法中,步骤s3中,每轮循环包括以下过程:
9、s31.分别对待泛化字段集[d]的各隐私字段d1、d2……dn进行一步泛化,[d]=d1、d2……dn,表示被指定泛化算法的原始字段集或被上一轮循环泛化处理后的字段集,n表示被指定泛化算法的隐私字段数量,如果当前是第一轮循环,那么[d]就是原始字段集,如果不是则是上一轮循环泛化处理后的字段;
10、s32.每个泛化后的隐私字段与其余未泛化的隐私字段组合成新字段集[di’],i=1、2…n;
11、[di’]表示[d]字段集中第i个隐私字段被泛化,其余隐私字段未被泛化的新字段集;
12、此过程将得到n个新的新字段集[di’];
13、s33.通过可用性计算方法计算每个新字段集[di’]的可用性指标;
14、s34.选择其中可用性指标最高的新字段集[di’],并确定该新字段集中的字段di为本轮泛化对象,该具有最高可用性指标的新字段集[di’]会是本轮泛化后的字段集[di’];
15、s35.若本轮泛化后的新字段集[di’]满足k匿名,则结束脱敏处理,否则,以本轮泛化后的新字段集[di’]为待泛化字段集[d],重复步骤s31-s35。
16、以上所说的字段针对的是指定了泛化算法的隐私字段。本方案主要针对泛化算法的脱敏进行自适应调整,使脱敏后数据既能够满足泛化算法的k匿名,又能够具有较高的可用性。其余字段脱敏策略与现有技术一致。此外,以上此处所说的泛化、未泛化均是指本轮循环泛化或未泛化。
17、在上述的基于可用性评估的自适应个人信息脱敏方法中,步骤s3中,若本轮泛化后的字段不满足k匿名,则保存各隐私字段的泛化结果以供后续循环使用;
18、在本轮循环中,对上一轮泛化对象di的泛化结果进行进一步泛化,其余字段使用已保存的泛化结果。如此,可避免在每一轮循环中重复对同一字段进行相同的泛化处理,从第二轮开始每轮循环只需计算一个字段的泛化即可。
19、在上述的基于可用性评估的自适应个人信息脱敏方法中,在每一轮循环中,通过评估每个新字段集[di’]对集成学习器在下游机器学习任务上的性能指标影响来计算其可用性指标。
20、在上述的基于可用性评估的自适应个人信息脱敏方法中,所述的可用性指标为由多个可用性片面指标加权而得的可用性综合指标;
21、且通过设定多个不同机器学习任务的方式来获得多个可用性片面性指标。
22、在上述的基于可用性评估的自适应个人信息脱敏方法中,步骤s3中,每轮循环中,通过如下方式选择使相应字段集可用性最高的字段进行泛化:
23、设定m个机器学习任务t1,t2,…,tm,m为大于2的自然数;
24、为每个任务tj指定相应的目标字段和特征字段,j=1、2…m;
25、为每个任务tj指定x个基学习器bj1,bj2,…,bjx,组成集成学习器cj;
26、步骤s3中,使用各新字段集[di’]通过多折交叉验证的方式分别为每个任务tj训练一个集成学习器实例cij,表示使用第i个隐私字段被泛化其余隐私字段未被泛化的新字段集基于第j个机器学习任务进行训练得到的实例,并测试所述集成学习器实例cij以得到相应新字段集[di’]对应的性能指标作为关于任务j的可用性片面指标;
27、根据设定加权参数,将m个可用性片面指标进行加权求和得到新字段集[di’]对应的可用性综合指标;
28、比较各新字段集[di’]的可用性综合指标,选择可用性综合指标最高的新字段集[di’]字段di为本轮泛化对象。
29、在上述的基于可用性评估的自适应个人信息脱敏方法中,步骤s1中,所述的待脱敏的原数据集为从数据源获取到的结构化数据表;
30、获取结构化数据表后,对其中的各字段进行分类,识别出包含个人信息的隐私字段。
31、在上述的基于可用性评估的自适应个人信息脱敏方法中,步骤s1中,通过标识符识别方式和字段含义识别方式识别隐私字段;
32、通过标识符识别方式识别直接标识符、准标识符和非标识符;
33、直接标识符和准标识符被识别为隐私字段;
34、对准标识符采用泛化算法,直接标识符可以根据需要使用相应的脱敏算法,不在此限制。
35、在上述的基于可用性评估的自适应个人信息脱敏方法中,步骤s2中,
36、机器学习任务数量m=准标识符字段数量,机器学习任务的设置方式为:
37、对于每个任务tj,将第j个字段作为任务的目标字段,其余字段作为该任务的特征字段。
38、一种基于所述方法的基于可用性评估的自适应个人信息脱敏系统,该系统包括:
39、数据输入模块,用于接收待脱敏的原数据集;
40、敏感信息识别模块,用于识别数据中的隐私字段;
41、脱敏方案制定模块,用于制定脱敏策略,且为至少两个字段指定使用泛化算法;
42、脱敏执行模块,用于对其余隐私字段执行脱敏策略;循环对指定了泛化算法的隐私字段根据可用性指标选择其中使相应字段集可用性最高的一个字段进行泛化直至k匿名检测满足条件;
43、可用性评估模块,用于计算可用性指标并向脱敏执行模块反馈;
44、数据输出模块,用于合并脱敏结果并输出脱敏后数据集。
45、本发明的优点在于:
46、1.本方案提出了使用可用性指标指导k匿名的过程,使得脱敏过程同时关注可用性和隐私性,能够在保证隐私性满足要求的情况下最大程度保证数据集的可用性,使最终输出的脱敏后数据集具有更高的可用性,为后续数据分析的效果提供了一定程度的保障;
47、2.本方案提出了一种刻画脱敏后的数据可用性的方法,该方法对脱敏后的数据集的可用性进行了量化评估,通过多个机器学习任务的性能指标计算得到综合可用性指标,以直观地反映脱敏后的数据集的可用性。
- 还没有人留言评论。精彩留言会获得点赞!