一种基于LLM的文档结构化自动处理方法及系统与流程
本发明涉及文档处理,尤其涉及一种基于llm的文档结构化自动处理方法及系统。
背景技术:
1、文档结构化是指将文档内容按照一定的逻辑和层次进行组织和安排,以便于信息的检索、理解和处理。结构化文档通常具有清晰的格式和组织方式,使得便于计算机理解和处理,可以有效地支持自动化流程和数据分析,也使得信息变得更加有序、可搜索和便于分析。文档结构化处理也可以使得读者能够快速找到所需的信息,方便用户直观阅读。
2、文档结构化涉及对文本的处理。传统的文本处理方法通常通过人为构建文档结构规则,利用规则匹配技术对文档进行分析和整理。例如,在某些特定领域文档中,通过预定义关键词或固定格式识别特定段落内容,从而确定文档的逻辑结构。如公告号为cn117093589b的专利文献提供的一种非结构化数据入库方法及装置,就需要采用特定的若干项入库规则对非结构化数据/文档进行匹配。然而,此类方法对规则的依赖性较强,扩展性较差,难以应对文档结构复杂或内容多样化的场景,特别是在无序、非标准化或跨领域的文档处理中,规则匹配方法容易失效。例如,当文档中存在隐含关系或非显性结构信息时,规则匹配无法准确捕捉。
3、基本的自然语言处理技术通过机器学习对大量文本数据进行建模,以实现文档结构化和语义理解。例如,通过训练词袋模型、或基于统计的方法进行语义分析,从而生成具备一定语义理解能力的文档分析结果。在此基础上,bert(bidirectional encoderrepresentation from transformers,由google ai研究院提出的一种预训练模型,专精于阅读理解。)等深度学习模型被广泛应用于文本的语义理解与抽取,其通过对上下文关系进行建模,能够生成连贯的摘要内容或提取关键信息。这类方法虽然在一定程度上改善了文档处理的效果,但其主要用于短文本的分析,对于具有层级关系或嵌套结构的长文本,现有技术难以有效地还原其语义逻辑。此外,现有技术中普遍缺乏对文档层级关系的动态管理能力,导致在复杂文档处理场景中,输出的结构化结果往往存在逻辑紊乱或不够直观的问题。另一方面,此类模型对数据质量的依赖性较高,当数据分布发生变化时,模型的适用性可能受到影响。
4、此外,在面对不同领域的文本进行文档结构化时,现有的基于规则或统计的技术方案对新场景或新需求的适应能力较差。规则匹配方法需要手动调整规则库,而基于机器学习的模型则需要重新训练,耗时耗力且成本较高。特别是,当需要处理动态变化的文档格式或需要快速扩展到新的领域时,现有技术难以满足实际需求。
5、在文档结构化过程中,现有方案往往无法有效过滤冗余信息,导致输出结果冗长且不够精炼,而在此后针对结构化数据进行信息提取时因为信息冗余也会产生一定问题。这是由于现有技术未能充分结合语义分析与冗余识别技术,对多余或重复的内容缺乏针对性的去冗措施,特别是在长文本或复杂报告类文档中,该问题尤为突出。同时,基于ocr扫描的文本往往存在着大量的错字,漏字以及排版问题,通过传统分词方法难以实现既获得语义,又纠正语法/语句错误的目的。
技术实现思路
1、针对现有技术存在的问题,本发明提供了一种基于llm的文档结构化自动处理方法及系统,可以实现对复杂无序文档的语义分析及抽取,动态追踪文档层级关系,实现对多层嵌套内容的有效处理,有效识别和去除冗余信息,且适用于多领域、多类型文档。
2、本发明的技术方案是这样实现的:
3、一种基于llm的文档结构化自动处理方法,包括如下步骤:
4、s1、文档输入和预处理:所述文档包括无序文本;输入的文档格式包括docx、txt等。所述预处理包括文本标准化处理和语义修复;所述文本标准化包括去除所述无序文本中的特殊字符和统一编码格式;所述语义修复为调整所述无序文本的语义密度,扩充或删减所述无序文本的段落,保证后续步骤中,无序文本的关键词与语义可以被正确识别;具体的,语义修复针对于删除无意义的、对于语句不通顺的、错误的字符或词语、或语气助词等。
5、s2、去冗余和关键词提取:去除所述无序文本中的重复信息;分析所述无序文本,提取所述无序文本的关键词,记为第一关键词,即利用自然语言处理技术,识别无序文本中的重要名词、动词和专有名词;用于后续辅助大模型理解文本进行语义抽取,最终以维持信息的精确性和紧凑性;
6、s3、语义抽取和结构化:利用预训练的大型语言模型,也即llm,largelanguagemodels,具体的模型如gpt3或bert等;根据所述第一关键词,逐句解析所述无序文本,并抽取所述文本中每一个句子对应的主要意义和相关语义信息,得到抽取结果;所述抽取结果包括同一个句子的若干个关键词,记为第二关键词,还包括句意;句意相当于大模型对句子的理解结果;
7、s4、语义栈构建和更新:根据所述抽取结果构建和更新语义栈;所述语义栈存储的数据为语义单元;一个所述语义单元对应同一个句子包含的所述第二关键词和所述句意;不同所述语义单元之间为父子或同级的层级关系,或无层级关系;
8、语义栈用于维护文档的信息层次,确保文档结构的逻辑性和连贯性;
9、语义单元是在语义分析中,构成语义信息的最小片段,也是语句中可以独立表达意义的最小部分,这些部分在语义上是完整的,不会因为后续文本的变化而改变。例如,在句子“上午10点我去了趟公园”中,可以抽取出“上午10点”、“我”、“去了趟”、“公园”这四个语义单元。每个语义单元都是独立的语义信息片段,其内容不会随着下文的变化而变化。
10、s5、结构化输出:将所述语义栈中的数据以预设格式输出。预设格式如xml、json等,进一步的,以思维导图等形式输出,可以很好的展示层级关系。
11、在上述各步骤中,文档的预处理、去冗余和关键词提取、语义抽取和结构化可以都有涉及大语言模型(llm)执行操作,也可以采用其它自定以的程序执行。如语义调整时,大模型前期根据用户要求检查文本是否需要调整,输出true or false,后期可以自主识别,形成用户自定义+模型检测,类似于思维链(cot)的结果。
12、通过大语言模型(llm)的深度语义分析能力,可以实现对复杂文档内容的全面理解和逻辑关系建模,通过实时追踪和调整文档层级关系,有效处理嵌套复杂的文档内容,确保结构化输出的层次分明、逻辑清晰,特别适用于多层次报告或法律文书。
13、作为以上方案的进一步优化,步骤s4中,更新所述语义栈前,还包括层级判断操作;所述层级判断操作包括,利用语义嵌入计算两个所述语义单元之间的相似度r:
14、
15、其中,a为所述语义栈已存储的语义单元,b对应于新的语义单元;sa和sb分别对应a和b的嵌入向量;
16、若所述相似度r处于预设阈值区间内,则b为a的子级。
17、每个语义单元包括若干个第二关键词,使用预训练模型(如bert或gpt)可以将第二关键词或语句/句意转化为数字编码表示,即为嵌入向量。
18、例如在m3e(moka massive mixed embedding的缩写,它是一个开源的中文文本嵌入模型。)中,将句子输出经过训练的embedding模型(嵌入模型(embedding model)是一种广泛应用于自然语言处理(nlp)和计算机视觉(cv)等领域的机器学习模型。它的工作原理是将高维度的数据转化为低维度的嵌入空间(embedding space),并保留原始数据的特征和语义信息,从而提高模型的效率和准确性。),会将文本转化成一个向量。
19、作为以上方案的进一步优化,步骤s4中,更新所述语义栈前,还包括层级判断操作;所述层级判断操作包括,计算所述语义单元的信息熵:
20、
21、其中,h(x)表示所述语义单元的信息熵;x表示所述语义单元;xi为第i个所述第二关键词;p(xi)表示x的分量包括xi的概率;也即在一个语句中,在特定位置的某个词汇出现的概率值;
22、对于a表示所述语义栈已存储的语义单元,b表示新的语义单元;
23、若h(b)<h(a)h(b)<h(a),则b为a的子级。
24、p(xi)可以通过bert模型,或自定义算法算出。
25、作为以上方案的进一步优化,所述信息熵的计算由bert模型完成,计算过程为:
26、
27、其中,|x|表示一个所述语义单元的所述第二关键词的数量;
28、v表示预设的词汇表;|v|表示所述词汇表中的词的数量;vj表示所述词汇表中的第j个词;p(xi=vj|x)表示xi和vj相同的概率。
29、p(xi=vj|x)还可以替换为其它模型或其它自定义算法计算的结果。
30、由于英文和中文在自然语言处理上的差异,即中文不像英文是以单词结构进行排序,因此模型处理中文时需要对中文进行分词,所参照的分词表就是词表,即大模型内置词表即为上述词汇表。
31、作为以上方案的进一步优化,步骤s4中,更新所述语义栈前,还包括层级判断操作;所述层级判断操作包括,构造语法树,结合利用句法分析确定两个所述语义单元之间的层级关系。
32、如:预定义语法树:章–节–条那么文本就可以按照章节条的顺序进行堆叠。
33、作为以上方案的进一步优化,所述语义栈的数据结构采用后进先出栈;所述语义栈的操作包括压栈、弹栈、替换和遍历;
34、所述压栈为将新的所述语义单元压入所述语义栈的栈顶;
35、所述弹栈为移除并返回所述栈顶的语义单元;
36、所述替换为用新的所述语义单元替换所述栈顶的语义单元;
37、所述遍历为自所述栈顶向下遍历,查找指定的所述语义单元;
38、所述语义栈的操作的触发包括:
39、a、同级替换:若新的所述语义单元current与所述栈顶的语义单元top为同一层级,则执行所述替换操作,即if lcurrent=ltop,then replace(top,current);其中,l表示所述语义单元的层级;
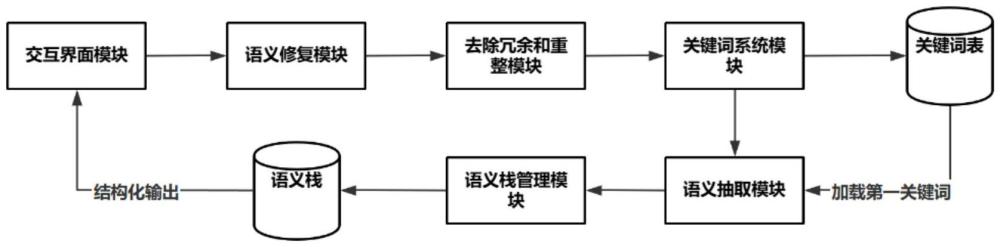
40、b、下级压栈:若current为top的子级,则执行所述压栈操作;即if lcurrent=ltop+1,then push(current);
41、c、高n级弹栈:若current的层级比top的层级高n,则执行n次所述弹栈操作,再执行所述替换操作;即
42、if lcurrent=ltop-n,then n times pop();pop();…pop()and replace(newtop,current);其中,new top表示弹栈n次后的所述栈顶的语义单元;层级越低,则越接近栈顶,层级越高,则越远离栈顶。
43、push()、pop()和replace()分别表示所述压栈操作、所述弹栈操作和所述替换操作。
44、作为以上方案的进一步优化,还包括语义栈的动态管理;所述动态管理包括深度控制和宽度调整;
45、所述语义栈的属性包括栈的深度和宽度,其中,最大栈深度为dmax,最大栈宽度为wmax;
46、所述深度控制为,若新的所述语义单元的层级大于dmax,则触发信息熵最计划策略,即弹出或替换所述语义栈中栈顶的语义单元;
47、所述宽度调整为,通过聚类方法或分类方法将相似的语义单元归并,使处于同一层的语义单元的数量小于或等于wmax。
48、本发明还提供了一种基于llm的文档结构化自动处理系统,应用了上述的一种基于llm的文档结构化自动处理方法;包括交互界面模块、语义修复模块、去除冗余和重整模块、语义抽取模块、语义栈管理模块;
49、所述去除冗余和重整模块还具有子模块,包括关键词系统模块;
50、用户通过所述交互界面模块上传所述文档、输入处理指令和接收输出结果;
51、所述语义修复模块用于执行步骤s1中的语义修复操作;
52、所述去除冗余和重整模块及其子模块用于执行步骤s2;
53、所述语义抽取模块用于执行步骤s3;进一步的,语义抽取模块的设置中,包括调整模型的敏感度。具体的,通过不同的提示词结合用户指令完成调整。如用户希望关注犯盗窃罪相关的,模型在抽取文本的时候就会特别留意相关词汇。
54、所述语义栈管理模块用于执行步骤s4;
55、所述交互界面模块、所述语义修复模块、所述去除冗余和重整模块、所述语义抽取模块和语义栈管理模块依次连接;所述语义栈管理模块还与所述交互界面模块连接。
56、作为以上方案的进一步优化,还包括关键词表;步骤s2中,生成的第一关键词存储至所述关键词表;
57、步骤s3中,所述语义抽取模块从所述关键词表中加载所述第一关键词。
58、作为以上方案的进一步优化,还包括关键词系统模块;所述关键词系统模块包括关键词表和管理组件;所述关键词表存储的数据还包括自定义关键词;所述管理组件的功能包括根据所述自定义关键词自动生成新的第一关键词。
59、与现有技术相比,本发明取得以下有益效果:
60、(1)深度语义理解与精准结构化:通过语义归纳模块与语义抽取模块协同工作,利用大语言模型(llm)的深度语义分析能力,实现对复杂文档内容的全面理解和逻辑关系建模,输出语义清晰、逻辑严谨的结构化结果。
61、(2)动态层级管理:语义栈管理模块能够实时追踪和调整文档层级关系,有效处理嵌套复杂的文档内容,确保结构化输出的层次分明、逻辑清晰,特别适用于多层次报告或法律文书。
62、(3)冗余信息过滤:通过去冗余处理模块,结合语义分析技术,准确识别并过滤文档中的冗余信息,生成的结构化文档更加简洁高效,提升信息质量和实用性。
63、(4)灵活扩展能力:本发明采用模块化设计,结合llm的泛化能力,无需重新定义规则或训练模型即可适配不同领域和新类型的文档,系统灵活性显著增强。
64、(5)高效计算与大规模处理:优化数据流和模块协作,结合llm的并行处理能力,实现了大规模文档的快速结构化处理,同时保持高质量和高准确性。
65、(6)自动化程度高:通过全流程自动化设计,减少人工干预需求,降低操作成本,提高了文档处理的效率和效果。
- 还没有人留言评论。精彩留言会获得点赞!