一种基于深度学习的施工人机安全智能检测与预警方法与流程
本发明涉及目标检测和深度估计双领域,尤其涉及一种基于深度学习的施工人机安全智能检测与预警方法。
背景技术:
1、目标检测与深度估计是计算机视觉的重要核心技术,旨在找出图像中所有指定目标的位置和类别,并根据二维图像推断出场景中物体的三维信息,施工人机安全智能预警方法通过实时检测施工场景中的人机实际距离,动态识别危险区域进行风险预警。
2、现有技术中曾提出一种基于计算机视觉和模糊理论的人机碰撞安全水平评估方法,通过两个模块工作:视觉提取和安全评估。视觉提取模块通过计算机视觉识别建筑设备与工人,提取质心像素坐标和拥挤度,并通过校准过程计算设备与工人之间的空间关系,安全评估模块通过评估每个工人的安全水平并基于模糊推理系统对收集到的信息进行分析处理,实现事故预防。
3、现有技术中曾提出基于cnn的自动可视化评估框架用于评估人机接近程度,该框架通过yolov3算法将检测到的人机对象在由同形异义词变换创建的平面图上重叠,获得人机之间的准确距离,设备体积由yolo估计的移动位置和方向分配。工人的姿态估计由基于cnn的openpose技术确定,根据每个工人的感知生成安全椭圆,使用闭路电视验证可视化。
4、然而,现有技术中的方法存在着以下缺陷:
5、(1)二维信息存在局限性:现有方法大多都是通过平面像素数据实现的,平面像素数据易受复杂施工场景中的多种施工要素影响,实际施工中的真实空间情况难以通过二维数据描绘,对危险区域的检测准确率较低;
6、(2)三维信息获取方式繁琐:获取图像中的三维信息可有效提升施工现场人机安全水平的检测准确率,大多数基于三维信息的距离估测,都是依靠采集高质量数据的方式,通过外接设备点云重建,比如激光雷达,这类外接设备与施工现场的便携安全管理理念相悖;
7、(3)目标检测精度不足:当施工场景中存在目标遮挡与重叠或多目标检测需求时,传统yolo算法表现不佳,往往会出现遮挡区域内特征信息无法有效提取、重叠区域内目标特征易混淆的情况,导致最终无法进行有效地安全预警;
8、(4)无法实时检测施工安全并及时预警:施工安全管理与实时性密不可分。在目标检测算法方面,大多数方法使用基于faster r-cnn的目标检测算法可以提供更高的图像检测精度,但计算复杂度和时间开销较大,不适合实时检测,在深度估计方面,现有的使用monodepth2深度估计模块获取深度信息的方法实时性较差,其他自监督的深度估计方法都对深度信息domain存在依赖,且使用合成的数据简单进行深度回归会存在domain-transfer的问题。
9、因此,亟需一种能解决上述施工人机安全智能检测与预警中存在的问题的检测与预警方法。
技术实现思路
1、本发明为解决传统施工环境中施工人员与机械设备之间的安全风险监测问题:施工现场通常存在许多潜在的安全隐患,尤其是人机交互的场景,施工人员与重型机械设备之间的碰撞、误操作等可能造成严重的安全事故;现有的安全监测方法多依赖于人工巡检或传统传感器,这些方法存在反应迟缓、定位不精确、数据分析不足,难以实时并准确地预警施工场景中出现的安全风险的技术问题,提出一种基于深度学习的施工人机安全智能检测与预警方法。
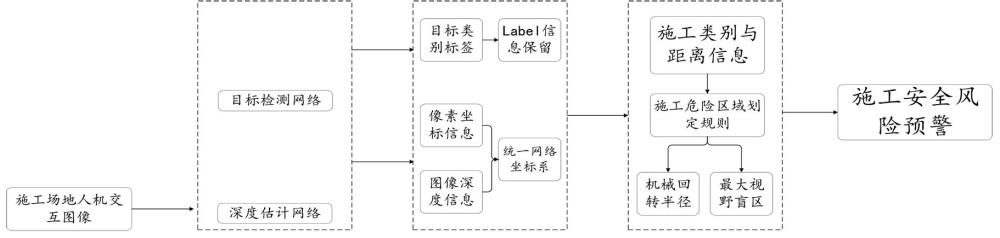
2、一种基于深度学习的施工人机安全智能检测与预警方法,包括以下步骤:
3、s1:将目标检测算法框架yolov11作为基础框架,利用小波变换与深度卷积相结合,捕捉到目标的不同尺度特征;
4、s2:使用目标检测算法框架yolov11中的small-seg模型作为预训练权重,在训练的同时加入迁移学习,通过冻结不分层权重训练的方式,释放训练资源,提升训练速度;
5、s3:在分割网络中引入全局上下文模块或注意力机制,利用上下文信息来辅助分割精细的模块进行工人和施工机械坐标的像素级别提取:
6、s4:通过可推广深度预测框架s2r-depthnet的结构提取模块ste分解分量,构建注意力图模块dsa过滤出用于深度估计的分量;
7、s5:训练结构提取模块ste中的编码器,在训练好编码器模块将编码器模块与结构提取模块ste的解码器深度估计模块dp进行深度估计,将构建注意力图模块dsa加入与深度估计模块dp进行深度估计一同进行深度估计;
8、s6:将目标检测模块中得到的类别和坐标信息传入深度网络,将label标签与像素坐标信息统一到深度网络坐标系中,进行从二维像素坐标系(u,v)到三维世界坐标系(x,y,zw)的转换,并输出人机之间的检测距离及对应的label标签。
9、进一步的,一种基于深度学习的施工人机安全智能检测与预警方法,所述步骤s1包括以下子步骤:
10、s11:在目标检测算法框架yolov11的主干网络backbone引入小波卷积wtconv,创建c3k2_wt模块替换c3k2模块;
11、s12:将小尺寸的深度卷积核分别应用在每个频率子带上,分解后每个子带的卷芯用3x或5x5的小卷芯操作;
12、s13:尺寸小的卷积核覆盖大的原始影像区域,波变换降低每个子带的空间分辨率,感受野增大;
13、s14:将施工现场在图像中占据较少的像素设为小目标,小波卷积wtconv在不同的尺度上进行多分辨率特征提取,通过小波变换从低频到高频捕捉到小目标的不同尺度特征,增强对小目标的识别能力。
14、进一步的,一种基于深度学习的施工人机安全智能检测与预警方法,其特征在于,所述步骤s2包括以下子步骤:
15、对于目标识别任务的评价,采用整体平均精度map作为评价指标,公式为:
16、
17、其中,map代表所有类别的平均精度取平均值,即整体平均精度,k代表类别个数,i=1、2、3...k,api代表第i类的平均精度值;
18、对于目标轮廓点的坐标精度评价,采用平均像素精度mpa作为评价指标,公式为:
19、
20、其中,mpa代表被正确标记的像素占所有像素中的比例,即平均像素精度,ncls代表目标类别个数,nij代表像素中类别i被预测为类别j的个数,nii代表像素中类别i被预测为真的个数。
21、进一步的,一种基于深度学习的施工人机安全智能检测与预警方法,所述s3包括以下子步骤:
22、s31:在识别建筑图像中的label类别信息后,不同建筑目标的外部轮廓被分别标注在各类别的目标像素上;
23、s32:对于小型机械设备或远离摄像头的部分,采用亚像素级别的坐标提取或基于轮廓的拟合方法,减少误差并提高坐标精度;
24、s33:计算加权坐标时,依据目标的尺度和重要性来调整权重,对难以捕捉的小型或远距离目标给予更大权重以强调重要性,公式为:
25、
26、其中,f(x,y)代表插值后的像素值,f(xi,yi)代表邻近的四个像素值,xi代表离散网格上点的横坐标,yi代表离散网格上点的纵坐标;
27、其中,clobal average pooling代表全局平均池化,h代表特征图的高度,w代表特征图的宽度,eature map(i,j)代表特征图上特定位置的特征强度或激活程度;
28、其中,代表加权坐标,n代表目标的数量,wi代表第i个目标的权重,(xi,yi)代表第i个目标的坐标。
29、进一步的,一种基于深度学习的施工人机安全智能检测与预警方法,所述s4包括以下子步骤:
30、s41:通过可推广深度预测框架s2r-depthnet的结构提取模块ste将将输入图像分解为stype-domain和structure-domain两个分量;
31、所述可推广深度预测框架s2r-depthnet包括结构提取模块ste、构建注意力图模块dsa、深度估计模块dp;
32、所述stype-domain用于后续的深度估计;
33、所述structure-domain包括depth-specific和depth-irrelevant两个分量;
34、s42:构建注意力图模块dsa产生attention map对结构信息进行抑制和过滤,确保structure-domain只剩下depth-specific的信息用于深度估计。
35、进一步的,一种基于深度学习的施工人机安全智能检测与预警方法,所述s5包括以下子步骤:
36、s51:实地采集施工场景人机交互图像作为数据来源,输入单幅rgb图像,在数据集vkitti上进行训练;
37、s52:在编码器的训练中,编码器利用pbn数据与合成数据通过迁移学习使编码器对不同风格的图片具有通用性;
38、s53:在结构提取模块ste和深度估计模块dp训练中,固化编码器中的部分参数,同时合成数据训练结构提取模块ste中的解码器和深度估计模块dp的部分参数,损失函数公式为:
39、
40、其中,代表损失函数,代表深度预测结果,p代表像素索引,d代表真实深度值,λ和β代表超参数,ms代表结构提取模块ste输出的结构图,代表求取水平方向时的梯度,代表求取垂直方向的梯度;
41、s54:在构建注意力图模块dsa和深度估计模块dp训练中,固定结构提取模块ste中的参数,使用构建注意力图模块dsa生成的注意力图对生成的结构图进行优化,公式为:
42、
43、其中,msa代表深度特定结构图,代表元素乘法,使用数据集更新参数,ma代表注意力图,代表训练构建注意力图模块dsa和深度估计模块dp的损失函数;
44、s55:输出单目深度估计网络,深度图和每个像素点对应的深度值z=z(u,v);
45、其中,(u,v)代表二维像素坐标系。
46、进一步的,一种基于深度学习的施工人机安全智能检测与预警方法,所述s6包括以下子步骤:
47、s61:获得深度值z后,获取相机的内参、外参矩阵,公式为:
48、
49、k2=[r|t]
50、其中,k1代表内参矩阵,fx和fy分别代表x和y方向上相机的焦距,cx和cy代表图像中心点的坐标,k2代表外参矩阵,r代表旋转矩阵,为相机坐标系相对于世界坐标系的旋转,t代表平移向量,为相机坐标系原点在世界坐标系中的位置;
51、s61:使用相机内参、外参和深度信息,通过透视投影模型将二维像素坐标(u,v)和对应的深度值z转换为三维世界坐标(x,y,zw),设相机的坐标为右手坐标系,相机在中心原点,zw轴方向为视线方向,公式为:
52、
53、z=z(u,v)
54、
55、本发明的有益效果为:
56、1、设计目标检测与深度估计领域,旨在获得工人与设备间的真实距离并进行实时安全预警;
57、2、利用目标检测与深度估计方法从施工场景图像中获取二维信息与深度信息,进而得到人机实际距离,通过将施工机械的角度信息与边缘轮廓检测相结合,判断机械的精确位置和姿态;
58、3、使用yolov11目标检测算法,通过对网络结构进行优化,实现在复杂施工场景中的目标检测;
59、4、当检测到小型机械或远离摄像头的设备时,自动启用亚像素级别的坐标提取方法或基于轮廓的拟合方法,以减少坐标误差,确保检测精度,同时将对小型机械和远距设备赋予更高的权重,并自动处理设备之间的遮挡和重叠情况,避免重复检测或漏检;
60、5、使用s2r-depthnet深度估计网络通过自监督学习方法对单幅rgb图像进行深度估计,简化三维信息获取过程,摆脱对昂贵硬件的依赖。
- 还没有人留言评论。精彩留言会获得点赞!