文本检测方法及装置与流程
本公开涉及计算机,尤其涉及一种文本检测方法及装置。
背景技术:
1、敏感词过滤是一种在网站、应用程序或平台中实现内容审查的技术,用于阻止网站及用户发布包含不适当、非法或不符合政策的内容。
2、传统的敏感词过滤方法包括以下步骤:
3、步骤一:敏感词库构建。敏感词库是敏感词过滤技术的核心,包含了各种可能引发争议或不适的词汇,如脏话、侮辱性语言、政治敏感词汇等。敏感词库的构建需要综合考虑地域文化、法律法规、社会道德等因素,确保既不过度限制言论自由,又能有效阻止不良信息的传播。敏感词库可以手动收集,也可以从网上下载或利用系统同步获取。
4、步骤二:在预设的过滤时机,调用匹配算法将文本与敏感词库中的敏感词进行匹配,得到匹配结果。其中,匹配算法一般包括以下几种:
5、1、简单匹配算法:逐个检查文本中的每个词或短语是否与敏感词相同。这种匹配算法虽然简单但效率低,且随着文本长度增大或敏感词库增大时,匹配效率随之进一步降低。
6、2、前缀树(prefix tree,trie树)算法:又称字典树,是一种树形结构,用于快速检索字符串。在进行敏感词匹配时,构建一个trie树来存储敏感词库,然后遍历文本,使用trie树来快速查找匹配项,得到匹配结果。由于trie树可以在遍历文本的同时检查多个前缀,因此,这种方式比简单匹配更高效,可以提高查询效率。
7、但是,一方面,trie树需要为每个节点存储大量的指针,在最坏的情况下,存储空间的需求可能等于字符数,这导致trie树在存储大量字符串时需要大量的内存。
8、另一方面,相比哈希表,trie树的查找效率较低。一个有效构造的哈希表(即使用好的哈希函数和合理的负载因子)进行查找的查找时间复杂度为o(1),而trie树的查找时间复杂度为o(l),其中l是字符串的长度。
9、又一方面,trie树在处理没有公共前缀的字符串时,由于每个字符串都需要从根节点开始存储,因此,会消耗更多的内存空间,此外,trie树的实现复杂度较高,需要处理各种边界条件和特殊情况。
10、3、确定有穷自动机(deterministic finite automaton,dfa)算法:是一种非递归自动机,通过事件(event)和当前状态(state)来确定下一个状态(next state),即event+state=next state,是一种基于有限状态机的模式匹配算法,常用于敏感词过滤、字符串搜索等应用场景。这种方式具有高效且固定的时间复杂度。
11、但是,当敏感词库非常大时,dfa算法的性能会显著下降,单纯匹配的效率较低。同时,dfa算法缺少必要的灵活性,且只能进行最大匹配,例如,在敏感词过滤中,如果设置两个敏感词“你好”和“你好世界”,dfa算法只能判断出“你好世界”是敏感词,而无法判断出“你好”是敏感词。
12、4、aho-corasick(ac)自动机算法:ac自动机是trie树的一个扩展,用于在输入文本中快速查找多个模式串(即字符串)。它支持同时搜索多个敏感词。ac自动机通过构建一个失败指针(fail pointer)数组来优化搜索过程,使得在搜索一个敏感词时,可以跳转到其他敏感词的搜索中。
13、但是,一方面,构建ac自动机需要较多的内存,尤其是当模式串非常多或非常长时;同时,中文的字符集比英文大,导致trie树的节点数增加,进一步增加了内存消耗。另一方面,构建有限状态自动机的预处理过程比较复杂,需要额外的时间和空间开销。再一方面,构建trie树和失效指针的过程需要一定的时间,这在词表经常变动的场景下会导致初始化时间长的问题。
14、5、正则表达式算法:可以匹配复杂的模式,包括敏感词的变形或变体。但是,正则表达式可能会因为过于复杂而降低匹配效率。
15、综上,如何在文本检测过程中降低算法占用的内存、并提高文本检测效率是亟待解决的问题。
技术实现思路
1、有鉴于此,本公开提出了一种文本检测方法及装置,可以解决传统的敏感词匹配算法的算法效率低、且占用内存高的问题。
2、根据本公开的一方面,提供了一种文本检测方法,所述方法包括:
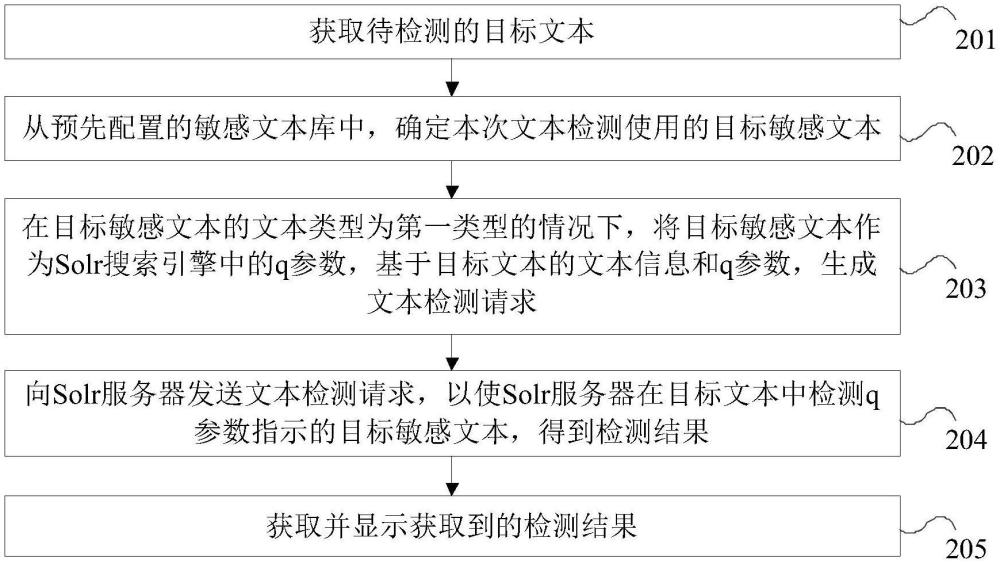
3、获取待检测的目标文本;
4、从预先配置的敏感文本库中,确定本次文本检测使用的目标敏感文本;其中,所述敏感文本库包括至少一个敏感文本;
5、在所述目标敏感文本的文本类型为第一类型的情况下,将所述目标敏感文本作为solr搜索引擎中的q参数,基于所述目标文本的文本信息和所述q参数,生成文本检测请求;其中,所述q参数为所述solr搜索引擎中的查询参数;
6、向solr服务器发送所述文本检测请求,以使所述solr服务器在所述目标文本中检测所述q参数指示的目标敏感文本,得到检测结果;
7、获取并显示获取到的检测结果。
8、在一种可能的实现方式中,所述第一类型包括邻近敏感词类型;所述邻近敏感词类型的目标敏感文本包括两个敏感词、以及两个敏感词之间的距离指示信息和顺序指示信息;
9、相应地,
10、所述向solr服务器发送所述文本检测请求,包括:
11、向所述solr服务器的围绕查询解析器发送所述文本检测请求,以供所述围绕查询解析器在所述目标文本中,检测符合所述距离指示信息和顺序指示信息的两个敏感词,得到所述检测结果。
12、在一种可能的实现方式中,所述第一类型包括长敏感词类型;所述长敏感词类型的目标敏感文本为字符数量大于或等于预设字符数量的敏感词;相应地,
13、所述向solr服务器发送所述文本检测请求,包括:
14、向所述solr服务器的预设查询解析器发送所述文本检测请求,以供所述预设查询解析器基于所述文本检测请求对所述目标文本进行分词,并检测分词得到的各个词是否与所述目标敏感文本匹配,得到所述检测结果;
15、其中,所述预设查询解析器与围绕查询解析器相同或不同。
16、在一种可能的实现方式中,所述方法还包括:
17、在所述目标敏感文本的文本类型为第二类型的情况下,调用本地文本匹配算法在所述目标文本中检测所述目标敏感文本,得到所述检测结果。
18、在一种可能的实现方式中,所述第二类型包括敏感语句类型;所述敏感语句类型的目标敏感文本为预设的语句;相应地,
19、所述在所述目标敏感文本的文本类型为第二类型的情况下,调用本地文本匹配算法在所述目标文本中检测所述目标敏感文本,得到所述检测结果,包括:
20、对于所述目标文本中的每个语句,将所述语句与所述目标敏感文本分别作为矩阵的行信息和列信息;
21、将所述矩阵中第i行的行信息和第j列的列信息进行比较,得到第i行第j列的元素值;所述i和所述j均为正整数;
22、基于所述矩阵的各个元素值,确定所述检测结果。
23、在一种可能的实现方式中,所述基于所述矩阵的各个元素值,确定所述检测结果,包括:
24、确定所述矩阵的每组斜线元素中元素值为1的元素数量;在元素数量最大的斜线元素中,确定元素值为1对应的行信息或列信息构成的字符串,得到所述检测结果;其中,在所述第i行的行信息和第j列的列信息相同时,所述第i行第j列的元素值为1;在所述第i行的行信息和第j列的列信息不同时,所述第i行第j列的元素值为0;
25、或者,
26、确定所述矩阵的最大元素值;将所述最大元素值所在的一组斜线元素中,确定元素值大于0的行信息或列信息构成的字符串,得到所述检测结果;其中,在所述第i行的行信息和第j列的列信息相同时,所述第i行第j列的元素值为1与第i-1行第j-1列的元素值之和;在所述第i行的行信息和第j列的列信息不同时,所述第i行第j列的元素值为0;
27、其中,一组斜线元素是指位于所述矩阵从左上方向右下方倾斜的同一斜线上元素。
28、在一种可能的实现方式中,所述方法还包括:
29、对于所述目标文本中的每个语句,确定所述语句是否满足预设的语句过滤条件;
30、在所述语句满足所述语句过滤条件的情况下,将所述语句滤除,并对下一个语句执行所述确定所述语句是否满足预设的语句过滤条件的步骤及之后的步骤;
31、在所述语句不满足所述语句过滤条件的情况下,若所述语句与至少两个目标敏感文本匹配,则对至少两个目标敏感文本进行去重处理后,触发执行所述获取并显示检测结果的步骤;
32、其中,所述语句过滤条件包括以下几种中的至少一种:
33、语句的字符长度小于第一字符阈值;
34、语句中除标点符号之外的其它字符与所述目标敏感文本完全相同;
35、所述本地文本匹配算法的输出结果指示语句中与目标敏感文本相同的字符长度小于第二字符阈值。
36、在一种可能的实现方式中,所述第二类型包括短敏感词类型;所述短敏感词类型的目标敏感文本为字符数量小于预设字符数量的敏感词;相应地,
37、所述在所述目标敏感文本的文本类型为第二类型的情况下,调用本地文本匹配算法在所述目标文本中检测所述目标敏感文本,得到所述检测结果,包括:
38、调用string.contains函数检测所述目标文本是否包含所述目标敏感文本,得到所述检测结果。
39、在一种可能的实现方式中,所述从预先配置的敏感文本库中,确定本次文本检测使用的目标敏感文本之前,还包括:
40、加载配置在excel词表中的敏感文本库;
41、对所述敏感文本库中的敏感文本进行验证;
42、在验证通过后,将加载到的敏感文本库存储至缓存,以在文本检测时调用缓存中存储的目标敏感文本。
43、根据本公开的另一方面,提供了一种文本检测装置,包括:处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为在执行所述存储器存储的指令时,实现上述方法。
44、根据本公开的另一方面,提供了一种非易失性计算机可读存储介质,其上存储有计算机程序指令,其中,所述计算机程序指令被处理器执行时实现上述方法。
45、根据本公开的另一方面,提供了一种计算机程序产品,包括计算机可读代码,或者承载有计算机可读代码的非易失性计算机可读存储介质,当所述计算机可读代码在电子设备的处理器中运行时,所述电子设备中的处理器执行上述方法。
46、通过获取待检测的目标文本;从预先配置的敏感文本库中,确定本次文本检测使用的目标敏感文本;在目标敏感文本的文本类型为第一类型的情况下,将目标敏感文本作为solr搜索引擎中的q参数,基于目标文本的文本信息和q参数,生成文本检测请求;向solr服务器发送文本检测请求,以使solr服务器在目标文本中检测q参数指示的目标敏感文本,得到检测结果;获取并显示获取到的检测结果;可以解决传统的敏感词匹配算法的算法效率低、且占用内存高的问题,由于solr服务器具有高效地处理和查找大量数据的特点,因此,通过solr服务器查询待检测的目标文本中是否包括目标敏感文本,可以提高敏感词检测的效率。同时,在检测过程中还不会占用较多用户端的内存。
47、另外,本实施例支持用户自定义的敏感文本库,从而满足用户多样化、个性化的文本检测需求。
48、根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
- 还没有人留言评论。精彩留言会获得点赞!