基于语义解耦和动态参数生成的跨语言跨模态检索方法
本发明涉及跨语言跨模态检索领域,尤其涉及一种基于语义解耦和动态参数生成的跨语言跨模态检索方法。
背景技术:
1、随着互联网上图像和视频的快速出现,世界各地的用户对通过自然语言检索感兴趣的视觉内容即跨模态检索,有着巨大的需求。跨模态检索是至少两种模态的数据之间互相检索,通常是以一种模态作为查询来检索另一种模态的相关数据。通过找出不同模态数据之间的潜在关联,实现相对准确的交叉匹配。通过跨模态检索可以让用户在庞大的信息海洋中迅速找到所需内容。深度学习技术的迅猛发展,尤其是近年来,极大地推进了跨模态检索技术的研究和应用。最近基于神经网络的跨模态检索模型倾向于需要大量人类标记的文本图像对数据进行训练,而这些数据仅适用于世界上少数语言。因此,为不同语言背景的用户构建跨模态检索系统极具挑战性,特别是对于低资源语言(例如捷克语)。所以跨语言跨模态检索就显得非常重要,它利用高资源语言中的视觉文本对数据为新的目标语言构建检索模型,用来应对目标语言缺乏大量人工标注数据的情况。
2、一种简单且成本低廉的解决方案是利用机器翻译工具将源语言标记的数据转换为目标语言。 有了这些由机器翻译生成的资源,现有的工作倾向于通过跨语言对齐将视觉语言模型的跨模态对齐能力转移到目标语言上从而能训练出多模态和多语言的模型。但是在跨语言迁移时,经常会导致模型产生知识遗忘现象,在高资源语言上的性能产生了下降。为了缓解这个问题,基于适配器的方法就应运而生。这些方法冻结视觉语言模型的参数,使用轻量级的适配器来进行跨语言迁移。然而,由于语言数量众多,不同的语言表达方式不一样,即使是同一种语言,对于同一张图片的描述也很有可能会有很大的差别,从而使模型无法高效准确地扩展到新的语言,这对于训练和改进跨模态检索系统构成了重大挑战。现有的适配器方法很难适应具有不同表达方式的目标语言句子,考虑到低资源语言的数量庞大,如何捕获这些低资源语言的独特表达以及相应的语义信息是一件非常有挑战性的工作。
技术实现思路
1、本发明目的在于针对现有技术的不足,提出一种基于语义解耦和动态参数生成的跨语言跨模态检索方法。
2、本发明的目的是通过以下技术方案来实现的:一种基于语义解耦和动态参数生成的跨语言跨模态检索方法,该方法包括如下步骤:
3、s1、对源语言和目标语言句子进行分词后编码,得到对应语言文本的嵌入向量;
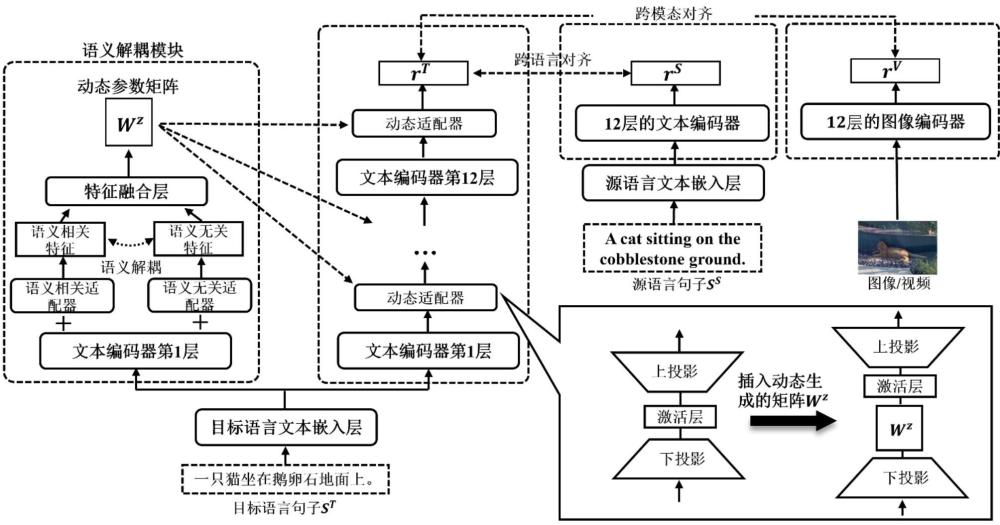
4、s2、将嵌入向量输入到源语言分支、目标语言分支和语义解耦分支的文本编码器得到其对应的特征向量,所述源语言分支和目标语言分支文本编码器为12层,语义解耦分支的文本编码器为1层;
5、所述语义解耦分支为:使用预训练的文本编码层输出至2个多层感知机中分别得到语义相关和语义无关的特征输出;将得到的两个特征拼接后再经过一个多层感知机得到动态适配器的参数;
6、所述目标语言分支为在预训练的文本编码器层输出至动态适配器得到最终的文本信息,作为目标语言文本输出或下一层的目标语言输入,其中动态适配器的参数由语义解耦得到;
7、s3、对语义无关特征与源语言文本信息的输出进行对抗学习并构建约束;
8、s4、根据文本编码器输出的目标语言文本特征和源语言文本特征,使用mse损失来训练目标语言分支的动态适配器的参数实现跨语言迁移;
9、s5、将目标语言文本输入到跨语言对齐阶段训练好的文本编码器中,得到跨模态对齐的目标语言分支文本特征;
10、s6、使用预训练的图像编码器获取图像特征,使用infonce损失计算实现文本特征和图像特征的跨模态对齐的检索模型;
11、s7、将文本输入到训练好的检索模型中,实现跨语言跨模态的检索。
12、进一步地,所述对源语言和目标语言句子进行分词后编码具体为:
13、加载预训练的mbert和clip的分词器,对源语言文本和目标语言文本进行分词操作得到分词后固定长度的tokenid向量;
14、用一个多语言词嵌入矩阵和clip的词嵌入矩阵对之前获得的tokenid向量进行词嵌入操作,得到源语言文本和目标语言文本的词嵌入编码向量,并对两个文本次嵌入向量加上位置编码。
15、进一步地,所述文本编码器层具体为:
16、利用得到的源语言文本和目标语言文本的嵌入向量通过预训练模型clip的每层的文本编码器得到对应的特征向量,其中i代表encoder的第i层;
17、
18、
19、这里 是token级别的,可以表示成。
20、进一步地,所述语义解耦分支具体为:
21、只需要将经过一层文本编码器的特征分别经过语义相关适配器和语义无关适配器得到语义相关和语义无关特征之后再经过一个特征融合层融合获得动态适配器的参数:;
22、其中,,其中h代表隐藏层的大小,i代表语义相关适配器和语义无关适配器的中间层的大小,代表直接拼接操作,和分别代表语义相关适配器和语义无关适配器的上投影层,和分别代表语义相关适配器和语义无关适配器的下投影层,和代表特征融合层的上下投影层,和通过根据tokenid的值来选取向量得到和,代表语义相关特征,代表语义无关特征,将两者拼接之后经过一个特征融合层得到句子级别的特征向量z,维度为(b, i),再经过reshape操作将特征z向量的维度从i变成,并且,从而获取动态适配器的参数矩阵。
23、进一步地,所述目标语言分支动态适配器模块具体为:将文本特征向量输入到动态适配器模块得到目标语言文本特征:
24、
25、=
26、其中i代表encoder的层数, ,, 其中h代表隐藏层大小,代表特征融合层中间层大小并且,所以在参数量上做到了一定程度的减少, 代表经过适配器后的矩阵;经过12层encoder之后对得到的特征向量根据的值来选取[eos]向量,获得目标语言句子级别的特征向量。
27、进一步地,所述s3中具体步骤为:对语义解耦模块的语义相关和语义无关特征需要进行约束;具体地,让语义解耦模块中语义无关分支的特征远离源语言语义特征,所述语义无关特征约束为:
28、)
29、其中f为鉴别器,由一个简单的线性层构成,在变小的时候,模型会无法判别的正样本对所对应的源语言特征;
30、在语义相关特征约束为:
31、
32、其中b为批大小,为源语言特征,为语义相关特征;代表源语言句子级别的特征向量。
33、进一步地,所述使用mse损失来训练目标语言分支的动态适配器的参数和语义解耦分支的参数实现跨语言迁移具体为:
34、+
35、其中b为批大小,为源语言特征,为目标语言特征。最终对进行约束即可实现跨语言对齐。
36、进一步地,所述使用infonce损失计算实现文本特征和图像特征的跨模态对齐的检索模型具体为:
37、对图像特征和文本特征进行nce损失计算来训练语义解耦分支和动态适配器部分:
38、,
39、,
40、;
41、其中为温度系数,b为批大小,代表图像特征到文本特征的相似度损失,代表文本特征到图像特征的相似度损失,代表余弦相似度;在这个损失的约束下模型会使得相关的文本特征和图像特征彼此接近,而不相关的则相互远离。
42、根据说明书的另一方面,本发明说明书还提供了一种基于语义解耦和动态参数生成的跨语言跨模态检索装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现所述的一种基于语义解耦和动态参数生成的跨语言跨模态检索方法。
43、根据说明书的另一方面,本发明说明书还提供了一种计算机可读存储介质,其上存储有程序,所述程序被处理器执行时,实现所述的一种基于语义解耦和动态参数生成的跨语言跨模态检索方法。
44、本发明的有益效果:
45、1、本发明冻结原本文本编码器的所有参数, 引入语义解耦模块和动态适配器模块,语义解耦模块将一个句子解耦成语义相关特征和语义无关特征,简单来说就是一个句子的具体含义和表达形式,根据这两个信息,能让模型对处理同个语义但是有不同表述方式的句子也能有较好的表现。
46、2、本发明的动态适配器模块将语义解耦模块的输出通过低秩分解的方式融合到适配器中, 将语义相关信息和语义无关信息进行融合,来提高跨语言跨模态检索能力。
- 还没有人留言评论。精彩留言会获得点赞!