基于大语言模型和多Prompt的深度学习智能人岗匹配方法及系统与流程
本发明涉及大数据,具体是基于大语言模型和多prompt的深度学习智能人岗匹配方法及系统。
背景技术:
1、随着全球经济的快速增长和技术的不断进步,人力资源市场也在迅速发展,企业对于高效、准确的人岗匹配需求日益增加。传统的招聘流程往往依赖于人工筛选和面试,这种方式不仅耗时费力,而且难以在短时间内处理大量的简历和岗位需求。因此,如何利用先进的技术手段提高人岗匹配的效率和准确性成为了一个重要的研究课题。
2、传统匹配方法存在如下的局限性:
3、传统的匹配方法主要依赖于关键词匹配或简单的文本相似度计算,这些方法虽然简单易用,但存在以下显著的局限性:
4、缺乏语义理解:传统的关键词匹配方法无法捕捉文本中的深层语义信息,导致匹配结果不够精准。
5、信息处理能力有限:简历和岗位要求通常包含大量信息,传统的匹配方法难以有效地处理这些复杂的信息,并进行高效的匹配。
6、授权公告号为cn111144723b的中国专利公开一种人岗匹配推荐方法及系统、存储介质,其中方法包括如下步骤:获取用人单位录入的职位文本信息和求职人员录入的简历文本信息,职位文本信息为针对待招聘职位的相关信息,简历文本信息为求职人员的简历;基于文本解析算法对职位文本信息和简历文本信息进行文本解析,得到标签信息;结合职位相似度算法和职位简历匹配算法对标签信息进行处理,为当前职位推荐最匹配的简历。然而该方法未能利用到多个提示的技术,从而难以把握简历和岗位两者之间的关联性;
7、为此,本发明提出基于大语言模型和多prompt的深度学习智能人岗匹配方法及系统。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出基于大语言模型和多prompt的深度学习智能人岗匹配方法及系统,通过两个模型的协同工作,实现了高效且精准的人岗匹配。
2、为实现上述目的,提出基于大语言模型和多prompt的深度学习智能人岗匹配方法,包括以下步骤:
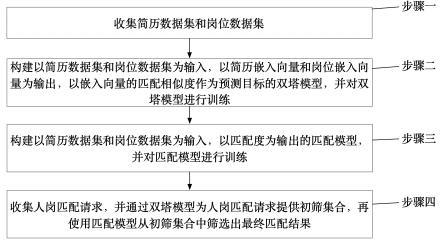
3、步骤一:收集简历数据集和岗位数据集;
4、步骤二:构建以简历数据集和岗位数据集为输入,以简历嵌入向量和岗位嵌入向量为输出,以嵌入向量的匹配相似度作为预测目标的双塔模型,并对双塔模型进行训练;
5、步骤三:构建以简历数据集和岗位数据集为输入,以匹配度为输出的匹配模型,并对匹配模型进行训练;
6、步骤四:收集人岗匹配请求,并通过双塔模型为人岗匹配请求提供初筛集合,再使用匹配模型从初筛集合中筛选出最终匹配结果;
7、所述收集简历数据集和岗位数据集的方式为:
8、从招聘站点后台数据库中读取所有求职者上传的简历数据,组成简历数据集、以及所有企业上传的岗位数据组成岗位数据集;
9、所述构建以简历数据集和岗位数据集为输入,以简历嵌入向量和岗位嵌入向量为输出的双塔模型的方式为:
10、所述双塔模型包括岗位塔和简历塔;
11、所述岗位塔包括输入层、切片层、嵌入模型、全连接层、注意力池化层以及输出层;
12、所述简历塔包括输入层、切片层、嵌入模型、transformer编码层、注意力池化层以及输出层;
13、所述岗位塔的输入层以岗位数据集中每个岗位的岗位描述作为输入;
14、所述岗位塔的切片层和嵌入模型分别用于将岗位描述进行文本切分和向量化,获得岗位初始嵌入向量;
15、所述岗位塔的全连接层和注意力池化层为本领域常规技术手段,通过全连接层、注意力池化层将岗位初始嵌入向量转化为长度为d的岗位嵌入向量;d为预设的嵌入向量长度;
16、而所述简历塔的输入层以简历数据集中每个求职者的简历文本作为输入;
17、所述简历塔的切片层和嵌入模型分别用于将简历文本进行文本切分及向量化,获得简历初始嵌入向量;
18、所述对双塔模型进行训练的方式为:
19、人工对岗位和简历进行匹配,并为每个匹配对进行标注;
20、使用标注好的匹配对来训练双塔模型;
21、所述构建以简历数据集和岗位数据集为输入,以匹配度为输出的匹配模型的方式为:
22、所述匹配模型包括岗位描述处理部分、简历文本处理部分以及合并匹配部分;
23、所述岗位描述处理部分的处理过程包括:
24、将岗位数据集中的每个岗位的岗位描述输入切分层,获得m项核心内容;
25、将每项核心内容分别输入至嵌入模型,获得核心内容对应的嵌入向量;
26、分别将每项核心内容的嵌入向量输入全连接层,获得对应核心内容的提示嵌入向量;
27、将各项核心内容的提示嵌入进行堆叠,获得岗位提示嵌入;
28、所述简历文本处理部分的处理过程包括:
29、将简历数据集中每个求职者的简历文本依次输入切分层和嵌入模型,获得嵌入模型输出的简历初始嵌入向量;
30、再将简历初始嵌入向量依次输入transformer编码层、注意力池化层,获得简历嵌入向量;
31、所述合并匹配部分的处理过程包括:
32、将岗位提示嵌入和简历嵌入向量输入多头注意力层,获得合并嵌入向量;
33、将合并嵌入向量输入全连接层,获得中间结果向量;
34、将中间结果向量输入至sigmoid函数层,输出范围是[0, 1]的实数值,即分类概率值,作为分类结果的置信度,亦作为匹配度;
35、设置分类阈值,输出大于或等于分类阈值的样本被归类为正类,即简历和岗位匹配;小于分类阈值的样本被归类为负类,即简历和岗位不匹配;
36、所述对匹配模型进行训练的方式为:
37、使用标注好的匹配对来训练匹配模型;
38、因为样本类别不均衡问题,使用focal loss计算训练损失并更新匹配模型的参数权重;
39、所述收集人岗匹配请求为通过招聘站点的后台收集求职者的简历,并为求职者生成岗位匹配请求,以及收集企业的岗位描述,并为企业生成简历匹配请求;
40、所述通过双塔模型为人岗匹配请求提供初筛集合的方式为:
41、对于岗位匹配请求,通过双塔模型获得求职者的简历对应的简历嵌入向量,以及所有岗位的岗位嵌入向量,再计算简历嵌入向量与各个岗位嵌入向量的余弦相似度,将余弦相似度大于预设的相似度阈值的岗位组成初筛集合;
42、对于简历匹配请求,通过双塔模型获得企业的岗位描述对应的岗位嵌入向量,以及所有简历的简历嵌入向量,再计算岗位嵌入向量与各份简历嵌入向量的余弦相似度,将余弦相似度大于预设的相似度阈值的简历组成初筛集合;
43、所述使用匹配模型从初筛集合中筛选出最终匹配结果的方式为:
44、对于岗位匹配请求,将求职者的简历和初筛集合中的各个岗位描述输入匹配模型,获得简历和初筛集合中的各个岗位的匹配度,匹配度最大的岗位即为最终匹配结果;
45、对于简历匹配请求,将企业的岗位描述和初筛集合中的各份简历输入匹配模型,获得岗位描述和初筛集合中的各份简历的匹配度,匹配度最大的简历即为最终匹配结果。
46、提出基于大语言模型和多prompt的深度学习智能人岗匹配系统,包括数据集收集模块、双塔模型训练模块、匹配模型训练模块以及匹配模块;其中,各个模块之间通过电性方式连接;
47、数据集收集模块,收集简历数据集和岗位数据集,并将简历数据集和岗位数据集发送至双塔模型训练模块和匹配模型训练模块;
48、双塔模型训练模块,构建以简历数据集和岗位数据集为输入,以简历嵌入向量和岗位嵌入向量为输出,以嵌入向量的匹配相似度作为预测目标的双塔模型,并对双塔模型进行训练,并将训练完成的双塔模型发送至匹配模块;
49、匹配模型训练模块,构建以简历数据集和岗位数据集为输入,以匹配度为输出的匹配模型,并对匹配模型进行训练,并将训练完成的匹配模型发送至匹配模块;
50、匹配模块,收集人岗匹配请求,并通过双塔模型为人岗匹配请求提供初筛集合,再使用匹配模型从初筛集合中筛选出最终匹配结果。
51、提出一种电子设备,包括:处理器和存储器,其中,所述存储器中存储有可供处理器调用的计算机程序;
52、所述处理器通过调用所述存储器中存储的计算机程序,执行上述的基于大语言模型和多prompt的深度学习智能人岗匹配方法。
53、提出一种计算机可读存储介质,其上存储有可擦写的计算机程序;
54、当所述计算机程序在计算机设备上运行时,使得所述计算机设备执行上述的基于大语言模型和多prompt的深度学习智能人岗匹配方法。
55、与现有技术相比,本发明的有益效果是:
56、本发明通过收集简历数据集和岗位数据集,构建以简历数据集和岗位数据集为输入,以简历嵌入向量和岗位嵌入向量为输出,以嵌入向量的匹配相似度作为预测目标的双塔模型,并对双塔模型进行训练,构建以简历数据集和岗位数据集为输入,以匹配度为输出的匹配模型,并对匹配模型进行训练,收集人岗匹配请求,并通过双塔模型为人岗匹配请求提供初筛集合,再使用匹配模型从初筛集合中筛选出最终匹配结果;通过训练双塔模型和匹配模型,其中,双塔模型用于生成岗位和简历的上下文向量,并存储到数据库中以支持简历和岗位的快速检索,可以灵活地进行各种不同方式的召回,比如“简历vs岗位”、“简历vs简历”、“岗位vs岗位”,
57、匹配模型用来预测岗位和简历的匹配情况,简历和岗位文本的分片处理,确保即使在简历文本较长的情况下也能保持岗位和简历的细节信息,而将岗位以prompt的方式与简历融合进行匹配预测,则有助于增强模型的语义理解、提升模型的预测性能,更适合复杂、多样化的岗位和简历匹配场景。通过两个模型的协同工作,实现了高效且精准的人岗匹配。
- 还没有人留言评论。精彩留言会获得点赞!