基于深度学习的古籍纸张纤维图像分类方法和电子设备
本发明涉及图像分类,尤其涉及一种基于深度学习的古籍纸张纤维图像分类方法和电子设备。
背景技术:
1、纸张作为古籍的主要承载物,会随着时间的推移不可避免地老化。此外,自然灾害和不当保管常导致古籍纸张损坏,出现字迹模糊、页面脱落等问题。这些损坏不仅影响古籍的可读性和完整性,还导致宝贵的历史信息面临难以挽回的流失。因此,古籍修复工作尤为重要,它不仅有助于恢复古籍的原始外观,而且能延续其文化价值。古籍修复过程中,纸张类型的分类至关重要,通过精确地分类古籍纸张类型,修复专家选择合适的材料和技术,确保修复工作的成功,最大限度地保留古籍的原始特性和价值,提高修复后古籍纸张的保存质量。
2、现有的古籍纸张分类方法存在以下问题:专家通常通过观察纸张的颜色和质感来进行分类,但纸张的老化过程会改变其特性,导致该方法的准确性不高;质谱法能提供纸张的详细化学成分,从而提高分类的准确性,但这种方法会对古籍纸张造成物理损害;尽管光谱分析法具有较高的分类精度,但设备成本高昂,无法实现广泛应用。在这种背景下,采用深度学习技术对古籍纸张纤维自动化分类提供了一种高效且低成本的解决方案。使用纤维图像分析仪采集图像,对采集到的图像特征统计分析。结果显示,不同纤维类型具有显著的区分特征,为深度学习在纸张纤维分类中的应用奠定了基础。
3、然而,将深度学习技术应用到古籍纸张纤维识别存在以下问题:由于深度学习技术首次应用于古籍纸张纤维识别领域,导致缺乏高质量的纸张纤维数据集;纸张纤维试片制作过程中常伴有噪声,且纤维形态多样、易重叠,导致模型在提取关键特征时存在困难;不同类别的纤维之间差异微小,通常仅体现在局部细节上,模型难以捕捉这些细微的类别的差异。
技术实现思路
1、有鉴于此,本发明提供了一种基于深度学习的古籍纸张纤维图像分类方法和电子设备,用以实现对纸张纤维的快速、准确的分类,确保修复工作的成功,以提高修复后纸张的保存质量。
2、第一方面,本发明提供了一种基于深度学习的古籍纸张纤维图像分类方法,所述方法包括:
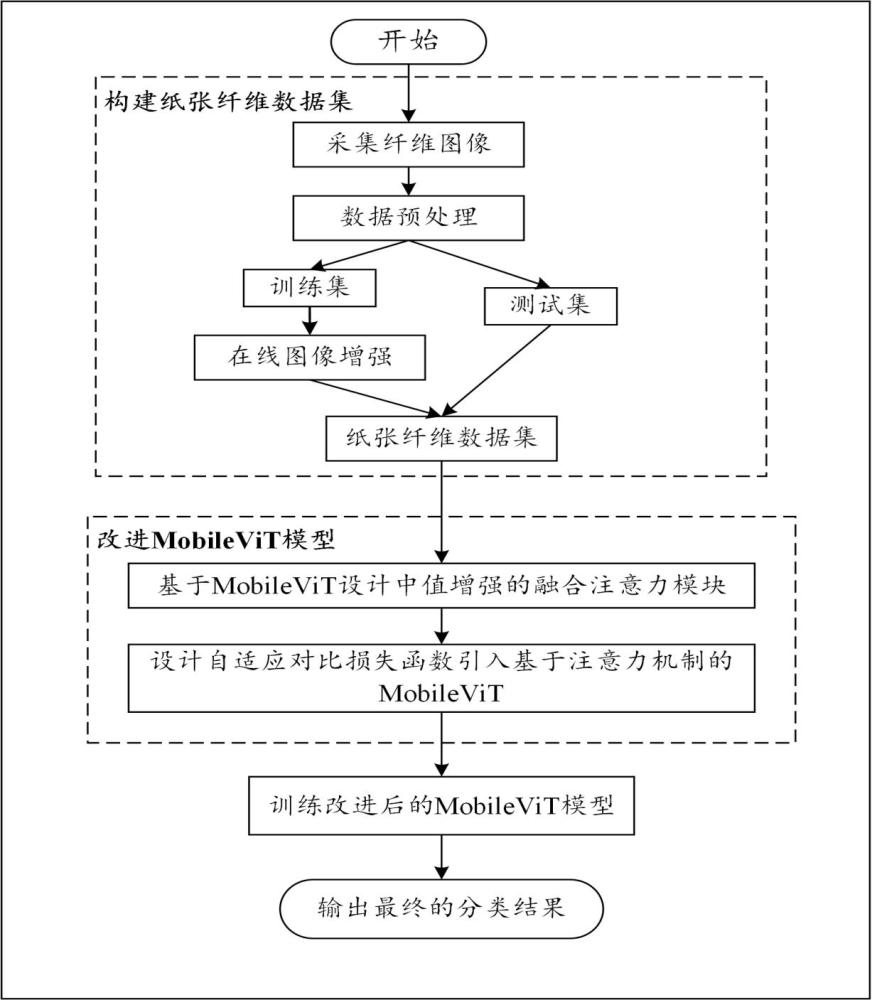
3、步骤1、采集纤维图像,对纤维图像进行数据预处理,将其划分为训练集和测试集,并对训练集进行在线数据增强,根据测试集和数据增强后的训练集获得纸张纤维数据集;
4、步骤2、使用mobilevit模型作为基础模型,从纸张纤维数据集中提取纤维的特征信息,获得最终的输出特征;
5、步骤3、根据最终的输出特征,对mobilevit模型的结构进行改进,设计中值增强的融合注意力模块,获得改进后的模型;
6、步骤4、设计自适应对比损失函数,对改进后的模型进行训练,输出最终的分类结果。
7、可选地,所述步骤1包括:
8、步骤11、通过纤维图像分析仪观察纤维玻片,确认每种纤维的特征;经过筛选后,纤维图像数据集中包括3350张分辨率为4088×3072的古籍纸张纤维图像以及23种不同类别的纸张纤维;
9、步骤12、对采集到的纤维图像进行数据预处理,将所有图像统一调整至224×224分辨率;
10、步骤13、使用在线图像增强策略,通过将图像水平翻转、随机裁剪、垂直翻转、30度内随机旋转以及亮度、对比度、饱和度、色调的调整,模拟不同显微成像条件。
11、可选地,所述步骤2包括:
12、步骤21、给定输入特征图,其中,h、w分别代表特征图的高度、宽度,为输入通道数;使用3×3卷积层提取初始局部信息,步长为2,空间尺寸减半,初始局部信息的表达式为:
13、;
14、其中,表示3×3卷积操作;
15、步骤22、输入通过若干个 mv2 模块进行轻量化局部特征提取,首先通过1×1逐点卷积将通道扩展到,应用 relu6激活函数进行非线性映射;随后通过3×3深度可分离卷积提取空间特征,保持通道数不变;再次应用relu6激活函数进行非线性映射,其表达式为:
16、;
17、其中,表示1×1逐点卷积操作,表示3×3深度可分离卷积操作;
18、步骤23、通过1×1卷积将通道从压缩回,通过线性层linear输出,其表达式为:
19、;
20、步骤24、若输入和输出通道一致,且步长为1,则加入残差连接:
21、;
22、当步长为2时,直接输出;
23、输出特征,;
24、步骤25、输入特征通过3×3卷积提取更细粒度的局部特征,其表达式为:
25、;
26、其中,c表示提取局部特征后的通道;
27、步骤26、为了处理局部特征并捕捉更丰富的空间关系,将局部特征分割为n个不重叠的图像块,形成输入序列,其表达式为:
28、;
29、其中,d表示每个图像块的特征维度;unfold表示展开操作,将特征图转换为一系列小块,每个图像块在展开后转化为向量序列,为全局特征学习提供输入;
30、步骤27、通过transformer编码器处理图像块序列,捕捉全局关系,通过l层transformer后,模型能学习图像的全局上下文信息,得到编码特征,其表达式为:
31、;
32、其中,l表示transformer编码器堆叠的层数;
33、步骤28、将编码后的特征重新折叠成与输入特征图相同的空间维度h×w,以确保信息的完整性,其表达式为:
34、;
35、其中,是全局特征通道数,fold操作将编码后的特征还原为于输入特征图相同的空间结构;
36、步骤29、通过融合模块将局部特征和全局特征结合,获得增强的特征表示,其表达式为:
37、;
38、其中,表示融合后特征的输出通道数;
39、步骤30、通过33卷积对融合后的特征通道进行调整,得到最终的输出特征y,其表达式为:
40、。
41、可选地,所述步骤3包括:
42、针对最终输出特征,设计中值增强的融合注意力模块,并将其融入mobilevit模型中;融合注意力模块通过中值池化操作,去除图像噪声,同时结合注意力机制提取纤维图像的重要特征;
43、步骤31、对于通道注意力机制,给定特征图,首先分别对其进行全局最大池化、全局平均池化和全局中值池化操作,全局最大池化用于捕捉特征图中最具代表性的激活区域,提取显著特征;全局平均池化用于捕捉通道的整体信息,反映全局特征分布;全局中值池化用于去除图像中的噪声;每个池化结果的尺寸均为;其次将三个池化结果输入共享多层感知器,生成对应的三个注意力图,其中共享多层感知器包括两个卷积层、一个leaky relu激活函数以及一个sigmoid函数;将这三个注意力图进行元素级相加,得到最终的通道注意力图;最后,将通道注意力图与原始输入特征图f逐元素相乘,得到输出特征图,其过程计算表达式为:
44、;
45、;
46、其中,表示共享的多层感知器操作,和分别为全局最大池化、全局平均池化和全局中值池化,表示元素相乘;
47、步骤32、在空间注意力机制中,首先将特征图通过一个5×5的卷积层,捕捉空间信息,生成初步的空间特征图;随后,针对纸张纤维呈长条状且长度不一的特性,设计多尺度卷积层,以细化特征表达;通过逐元素相加不同深度卷积层的输出,整合多尺度特征信息,生成融合后的特征图;最后,通过一个1×1卷积层将转换为最终的空间注意力图;空间注意力图与通道加权后的特征图逐元素相乘,得到最终的输出特征图,即最终的分类结果,其计算过程表达式为:
48、;
49、;
50、;
51、其中,表示不同尺寸的深度卷积操作,n表示深度卷积的数量,和分别表示5×5和1×1卷积操作。
52、可选地,所述步骤4中自适应对比损失函数,其表达式为:
53、;
54、;
55、;
56、;
57、其中,n表示批次大小,和通过l2正则化进行预处理,是和的相似性度量,是动态阈值,是固定阈值,是权重参数,表示自适应阈值;表示自适应对比损失值;z表示样本;表示交叉熵损失值;y表示样本的真实标签,表示样本的预测标签;表示总体损失值。
58、第二方面,本发明实施例提供一种电子设备,包括:一个或多个处理器;存储器;以及一个或多个计算机程序,其中所述一个或多个计算机程序被存储在所述存储器中,所述一个或多个计算机程序包括指令,当所述指令被所述设备执行时,使得所述设备执行第一方面或第一方面任一可能的实现方式中的基于深度学习的古籍纸张纤维图像分类方法。
59、本发明提供的技术方案中,该方法包括构建纸张纤维图像数据集,并对纸张纤维图像数据集进行预处理和数据增强,获得处理后的数据集;使用mobilevit模型作为基础模型,从处理后的数据集中提取纤维的特征信息;根据提取纤维的特征信息,对mobilevit模型的结构进行改进,设计中值增强的融合注意力模块,获得改进后的模型;设计自适应对比损失函数,对改进后的模型进行训练,以增强模型对不同类别纤维之间特征差异的识别能力,该方法实现了对纸张纤维的快速、准确的分类,确保了修复工作的成功,提高了修复后纸张的保存质量。
- 还没有人留言评论。精彩留言会获得点赞!