提升特定行业知识检索精度的方法及设备与流程
本发明涉及自然语言处理,具体涉及一种提升特定行业知识检索精度的方法及设备。
背景技术:
1、在信息爆炸的时代,各行各业都面临着海量数据的处理与利用问题,特别是在特定行业中,知识检索的精度直接关系到企业的竞争力和创新能力。
2、传统的搜索引擎主要基于关键词匹配和全文检索技术,这些方法在处理通用信息检索时表现良好,但在特定行业中,由于专业术语的复杂性,简单的关键词匹配往往会导致大量无关信息的出现,而真正相关的信息却可能被遗漏,使得检索结果有时不能满足用户的需求。
技术实现思路
1、为了解决现有技术中的上述问题,本发明提出了一种提升特定行业知识检索精度的方法及设备,提高了检索答案的精度。
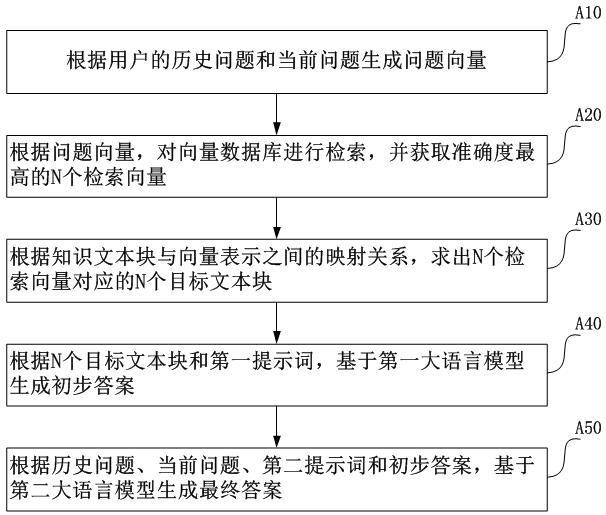
2、本发明的第一方面,提出一种提升特定行业知识检索精度的方法,所述方法包括:
3、根据用户的历史问题和当前问题生成问题向量;
4、根据所述问题向量,对向量数据库进行检索,并获取准确度最高的n个检索向量;其中,所述向量数据库中存储有若干个由所述特定行业的知识文本块生成的向量表示;
5、根据所述知识文本块与所述向量表示之间的映射关系,求出所述n个检索向量对应的n个目标文本块;
6、根据所述n个目标文本块和第一提示词,基于第一大语言模型生成初步答案;
7、根据所述历史问题、所述当前问题、第二提示词和所述初步答案,基于第二大语言模型生成最终答案;
8、其中,n为预设值。
9、优选地,“根据用户的历史问题和当前问题生成问题向量”的步骤包括:
10、根据所述历史问题、所述当前问题和第三提示词,基于第三大语言模型生成待解答问题;
11、将所述待解答问题转换为所述问题向量。
12、优选地,“根据所述问题向量,对向量数据库进行检索,并获取准确度最高的n个检索向量”的步骤包括:
13、根据所述问题向量,利用余弦相似度算法对所述向量数据库进行检索,得到m个检索向量,进而组成第一向量集;
14、根据所述问题向量,利用mmr(maximal marginal relevance)算法对所述向量数据库进行检索,得到m个检索向量,进而组成第二向量集;
15、求取所述第一向量集与所述第二向量集的交集;
16、对所述交集中的检索向量进行过滤和重排,选取准确度最高的所述n个检索向量;
17、其中,m为预设值。
18、优选地,所述方法还包括:
19、根据所述特定行业的文件数据库生成若干个所述知识文本块,并将所述知识文本块转换为向量表示存入所述向量数据库。
20、优选地,“根据所述特定行业的文件数据库生成若干个所述知识文本块,并将所述知识文本块转换为向量表示存入所述向量数据库”的步骤包括:
21、对所述特定行业的文件数据库中每个文件,读取该文件中的文字并对该文件中的图片进行解释,生成文本文件;
22、对每个所述文本文件进行切分,得到若干个不超过预设长度的原始文本块;
23、基于第四大语言模型对所述原始文本块进行文本清洗,得到所述知识文本块;
24、将每个所述知识文本块转换为对应的所述向量表示;
25、保存所述知识文本块与所述向量表示之间的映射关系,并将所述向量表示存入所述向量数据库中。
26、优选地,“对每个所述文本文件进行切分,得到若干个不超过预设长度的原始文本块”的步骤包括:
27、将每个所述文本文件按照一级标题进行切分,得到若干个第一文本块;
28、判断每个所述第一文本块的长度,若某个所述第一文本块的长度超过所述预设长度,则将该第一文本块按照二级标题进行切分,得到若干个第二文本块;
29、判断每个所述第二文本块的长度,若某个所述第二文本块的长度超过所述预设长度,则将该第二文本块按照三级标题进行切分,得到若干个第三文本块;
30、判断每个所述第三文本块的长度,若某个所述第三文本块的长度超过所述预设长度,则将该第三文本块按照段落进行切分,得到若干个第四文本块;
31、判断每个所述第四文本块的长度,若某个所述第四文本块的长度超过所述预设长度,则将该第四文本块按照句号进行切分,得到若干个第五文本块;
32、将来源于同一个所述第四文本块,且相邻的所述第五文本块按照先后顺序进行合并,得到若干个第六文本块;每个所述第六文本块中包含一个或多个所述第五文本块,且长度不超过所述预设长度;
33、构建所述原始文本块的集合;
34、其中,所述原始文本块包括:所有长度不超过所述预设长度的所述第一文本块、所述第二文本块、所述第三文本块、所述第四文本块、未经合并的所述第五文本块和所述第六文本块。
35、优选地,所述方法还包括:
36、构建所述特定行业的数据集,所述数据集中包括第一预设数量的问题样本和对应的标准答案;
37、将所述数据集按照预设的比例划分为训练集和测试集;
38、利用所述训练集采用lora(low-rank adaptation)技术对第二预设数量的大语言模型分别进行微调;
39、根据管理员的输入,从所述第二预设数量的微调后的大语言模型中分别选定所述第一大语言模型、所述第二大语言模型、所述第三大语言模型和所述第四大语言模型,且所述第一大语言模型、所述第二大语言模型、所述第三大语言模型和所述第四大语言模型相同或不同。
40、优选地,所述第一提示词为预设提示词,所述第二提示词和所述第三提示词为预设提示词或所述管理员设置的提示词;
41、所述方法还包括:
42、利用所述测试集基于ragas(retrieval augmented generation assessment)标准对检索与生成的效果进行评分,得到评分结果;
43、其中,所述评分结果包括:答案相关性、忠实度和上下文相关性。
44、本发明的第二方面,提出一种电子设备,包括存储器和处理器,所述存储器上存储有能够被所述处理器加载并执行如上面所述方法的计算机程序。
45、本发明的第三方面,提出一种计算机可读存储设备,存储有能够被处理器加载并执行如上面所述方法的计算机程序。
46、本发明具有如下有益效果:
47、本发明提出的提升特定行业知识检索精度的方法,根据问题向量对向量数据库进行检索并获取准确度最高的n个检索向量,然后根据映射关系求出对应的n个目标文本块,再利用第一大语言模型对目标文本块进行提炼和总结得到初步答案,最后用第二大语言模型对初步答案进行优化,从而得到最终答案。通过上述检索、获取准确度最高的n个检索向量、对文本块进行提炼、总结以及优化的过程,本发明一步一步地提高了检索结果的精度,使得最终答案能够很好地契合用户提出的问题。
48、余弦相似度算法通过计算向量之间的夹角余弦值来衡量相似度,适用于衡量向量方向上的相似性;而mmr算法则综合考虑了结果的相关性和多样性,有助于避免冗余和重复。将两者结合,可以充分利用各自的优势,提高检索结果的准确性。通过对两种检索结果求交集,可以进一步筛选掉那些只符合单一算法标准但不够全面的向量,留下那些同时满足两种算法标准的向量,这些向量在相似性和多样性方面往往更具代表性。将交集中的向量进行过滤、重排,再选取准确度最高的n个检索向量,使得获取的n个检索向量在相似性和多样性方面往往更加均衡。
49、本发明的文本块切分方法,保证了生成的原始文本块集合中既包含了文本文件中的所有句子,又不会出现重复现象。
50、在构建向量数据库时、生成待解答问题时、生成初步答案时,以及生成最终答案时均采用了大语言模型,而且这些大语言模型均利用特定行业的数据集进行了微调,使得大语言模型在工作过程中能够更加适应该特定行业中相关知识的特点,进一步提高了最终答案的精度。
51、总之,本发明从数据库构建、问题生成、数据库检索、结果筛选、文本提炼、总结和优化等多个环节进行了改进,能够有效提升特定行业的知识检索及增强生成的精度。
- 还没有人留言评论。精彩留言会获得点赞!