一种基于多源数据的多维度融合找矿预测方法与流程
本发明涉及地质勘探,特别涉及一种基于多源数据的多维度融合找矿预测方法。
背景技术:
1、目前,随着地质勘探技术的发展,利用地球物理、地球化学、遥感数据和传统地质调查的融合分析已成为现代找矿的趋势,特别利用是深度学习处理地质数据、挖掘地质信息方面展现出巨大潜力。这些技术能够处理多源地质数据,包括地球物理、地球化学和遥感数据,以及传统地质调查结果,通过智能分析揭示地质数据之间复杂的网络关系。机器学习和深度学习通过模拟人类的学习活动和深层神经网络提取关键特征,提高预测效果。在地质勘探领域,机器学习技术不仅提高了找矿预测的准确性和效率,还为找矿预测方法提供了新的研究方向。
2、现有技术中,基于机器学习和深度学习的找矿预测模型在实际应用中取得了一定成效,针对于多源的地质数据,使用随机森林(random forest)等模型处理像元级别的数据,使用卷积神经网络(convolutional neural network, cnn)分析空间级别的特征,使用图神经网络(graph convolutional network, gcn)处理矿区结构的关联性。
3、但是,机器学习找矿预测是寻找多源数据与成矿目标之间的非线性关系,由于地质数据其空间的多样性和复杂性,现有的深度网络模型不能有效综合各维度的地质数据信息,导致预测精度低下。同时,专家知识的缺乏往往使得结果并不能使地质专家信服,缺乏地质解释的可靠性。
4、因此,如何更好地利用多源数据不同维度的地质数据信息并进行多维度信息融合和预测,提高预测精度和地质解释的可靠性,成为了亟待解决的技术问题。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种基于多源数据的多维度融合找矿预测方法。
2、本发明采用下述技术方案:
3、本发明提供了一种基于多源数据的多维度融合找矿预测方法,包括:
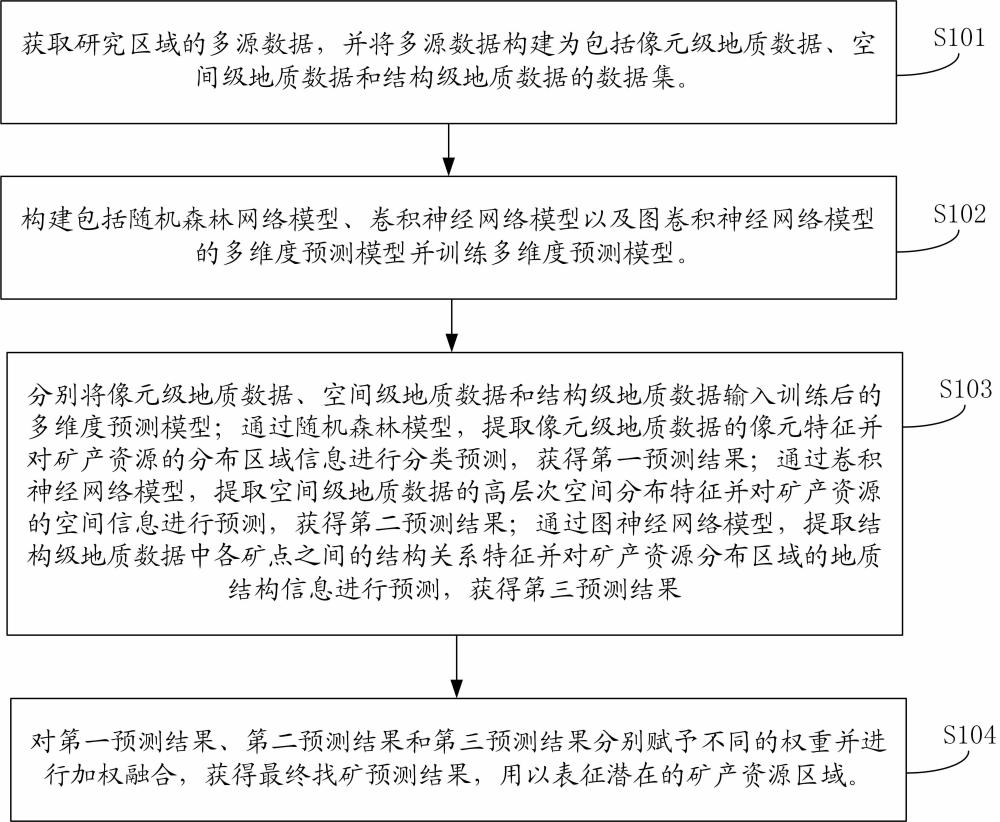
4、获取研究区域的多源数据,并将多源数据构建为包括像元级地质数据、空间级地质数据和结构级地质数据的数据集;
5、构建包括随机森林网络模型、卷积神经网络模型以及图神经网络模型的多维度预测模型并训练多维度预测模型;
6、分别将像元级地质数据、空间级地质数据和结构级地质数据输入训练后的多维度预测模型;通过随机森林模型,提取像元级地质数据的像元特征并对矿产资源的分布区域信息进行分类预测,获得第一预测结果;通过卷积神经网络模型,提取空间级地质数据的高层次空间分布特征并对矿产资源的空间信息进行预测,获得第二预测结果;通过图神经网络模型,提取结构级地质数据中各矿点之间的结构关系特征并对矿产资源分布区域的地质结构信息进行预测,获得第三预测结果;
7、对第一预测结果、第二预测结果和第三预测结果分别赋予不同的权重并进行加权融合,获得最终找矿预测结果,用以表征潜在的矿产资源区域。
8、优选地,所述将多源数据构建为包括像元级地质数据、空间级地质数据和结构级地质数据的数据集,包括以下步骤:
9、从地球物理、地球化学、遥感数据中提取多源数据;
10、基于多源数据构建规则网格,采用克里金插值方法对规则网格内的多源数据进行插值,得到多源数据浓度图;
11、将多源数据浓度图中的多要素特征图层叠加并进行数据融合,提取具有目标标签像元的多通道信息,构建像元级数据集;采用固定窗口大小,通过平移、旋转、缩放的方法进行数据样本裁剪,构建空间级数据集;利用分形理论确定结构阈值,并通过结构阈值分别构建节点特征矩阵和邻接矩阵,获得结构级数据集。
12、优选地,所述训练后的多维度预测模型的确定,包括以下步骤:
13、选取数据集的部分数据作为训练集样本;
14、将随机森林网络模型、卷积神经网络模型和图神经网络模型通过投票的方式进行集成,获得多维度网络模型;其中,所述投票的方式,具体为:将随机森林网络模型、卷积神经网络模型和图神经网络模型的输出结果进行平均;
15、将训练集样本输入多维度网络模型,通过对多维度网络模型进行训练,获得训练后的多维度预测模型;
16、优选地,所述通过随机森林模型,提取像元级地质数据的像元特征并对矿产资源的分布区域信息进行分类预测,包括:
17、采用自助采样法无放回的随机抽取部分像元级地质数据,获得多个子数据集;
18、针对于每个子数据集,构建一个决策树模型,并在每个决策树的节点随机选择一部分特征进行分裂;
19、针对于单个决策树模型,设定子数据集为,单个决策树模型输出为,表达式为:
20、;
21、其中,为子数据集的个数,为所有子数据集中的任一子数据集,是指示函数,是决策树的叶节点区域,是区域的输出值;
22、所述随机森林网络模型通过集成 n个决策树模型获得,并通过对 n个决策树模型的输出进行平均,获得第一预测结果,公式为:
23、;
24、其中,为第一预测结果,是第 i棵决策树的输出。
25、优选地,所述通过卷积神经网络模型,提取空间级地质数据的高层次空间分布特征并对矿产资源的空间信息进行预测,包括:
26、将空间级的地质数据作为卷积神经网络模型的输入;
27、采用卷积层对空间级的地质数据进行卷积操作,并通过非线性激活函数提取地质数据的高层次分布分布特征,公式为:
28、;
29、其中,是第层的输入,是第层的卷积核,是偏置项,表示卷积操作,是非线性激活函数;
30、采用池化层平均池化地质数据的高层次分布分布特征,获得池化特征,公式为:
31、;
32、其中,表示池化特征,表示平均池化操作;
33、采用全连接层将提取的池化特征转化为卷积神经网络模型的输出,获得第二预测结果。
34、优选地,所述通过图神经网络模型,提取结构级地质数据中各矿点之间的结构关系特征并对矿产资源分布区域的地质结构信息进行预测,包括:
35、提取结构级的地质数据的邻居节点信息和边信息;
36、通过迭代更新节点的嵌入表示,公式为:
37、;
38、其中,为经过 l层更新后节点的嵌入表示,为经过 l-1层更新后节点的嵌入表示,是节点的邻居节点集,为节点的邻居节点,和分别是当前层的权重矩阵,是激活函数,为经过 l-1层更新后邻居节点的嵌入表示;
39、通过全局聚合函数,将所有节点的嵌入表示聚合为结构图的表示,获得图神经网络模型的输出,获得第三预测结果,公式为:
40、;
41、其中,为结构的表示,为聚合函数,为经过 l层更新后节点的嵌入表示,表示节点,为节点集合。
42、优选地,所述最终找矿预测结果的获得,包括以下步骤:
43、获取第一预测结果、第二预测结果和第三预测结果的成对比较矩阵;
44、通过成对比较矩阵计算第一预测结果、第二预测结果和第三预测结果相对应的权重向量;
45、通过成对比较矩阵对第一预测结果、第二预测结果和第三预测结果相对应的权重向量进行合理性判断;
46、通过对第一预测结果、第二预测结果和第三预测结果及其对应的权重向量进行加权融合,获得最终找矿预测结果。
47、优选地,所述通过成对比较矩阵对第一预测结果、第二预测结果和第三预测结果相对应的权重向量进行合理性判断,包括:
48、通过公式计算成对比较矩阵的最大特征值;其中, a是成对比较矩阵, i是单位矩阵,为最大特征值;
49、通过最大特征值计算一致性指标;其中 n是成对比较矩阵 a的阶数;
50、通过成对比较矩阵阶数在随机一致性指数参考表中查找随机一致性指数;
51、通过一致性指标和一致性指数的比值获得一致性比率,并根据一致性比率判断相应权重的一致性;
52、若一致性比率大于0.1,认为各预测结果的权重判断不合理,则通过yaahp软件对权重向量进行自动修正,直至一致性比率小于等于0.1。
53、本发明采用的上述至少一个技术方案能够达到以下有益效果:
54、本发明通过集成包括随机森林网络模型、卷积神经网络模型以及图神经网络模型的多维度预测模型,对包括像元级、空间级以及结构级的不同维度的多源地质数据进行矿产资源的预测,有效综合了不同维度的多源地质数据信息,更全面和准确的捕捉了多源地质数据的多样性和复杂性。同时,通过加权融合多维度的预测结果并进行合理性的判断,使得预测结果具备了更好的解释性和可追溯性,提高了找矿预测的预测精度和地质解释的可靠性,从而为进一步的矿产评估和勘探决策提供了有力的科学指导。
- 还没有人留言评论。精彩留言会获得点赞!