一种获取使用者精确prompt的方法、介质及系统与流程
本发明属于大语言模型,具体而言,涉及一种获取使用者精确prompt的方法、介质及系统。
背景技术:
1、随着大语言模型在自然语言处理领域的广泛应用,用户能够通过提出各种开放性问题来获取模型的知识和推理能力。然而,用户提出的基础问题往往过于简单或模糊,无法很好地反映其实际需求。为了准确获取用户的真实意图,并生成针对性更强的回答,需要对用户的基础问题进行深入的语义分析和扩展。
2、当前,一些研究者尝试通过语义特征提取、知识图谱构建、基于路径的prompt生成等方法,来增强用户prompt的针对性和丰富性。例如,可以从问题中提取关键词、命名实体、关键短语等语义特征,并利用词典、知识库进行扩展,构建起反映语义概念及其关联的知识图谱。在此基础上,通过探索知识图谱上的路径,生成贴近用户需求的prompt。这些方法在一定程度上提高了prompt的质量,增强了用户体验。
3、但是,现有技术中prompt生成偏重于短语级别的模板填充,缺乏对prompt整体连贯性和差异性的考虑。这一问题限制了大语言模型在实际应用中的效果。
技术实现思路
1、有鉴于此,本发明提供一种获取使用者精确prompt的方法、介质及系统,能够解决现有技术中prompt生成偏重于短语级别的模板填充,缺乏对prompt整体连贯性和差异性的考虑的技术问题。
2、本发明是这样实现的:
3、本发明的第一方面提供一种获取使用者精确prompt的方法,其中,包括以下步骤:
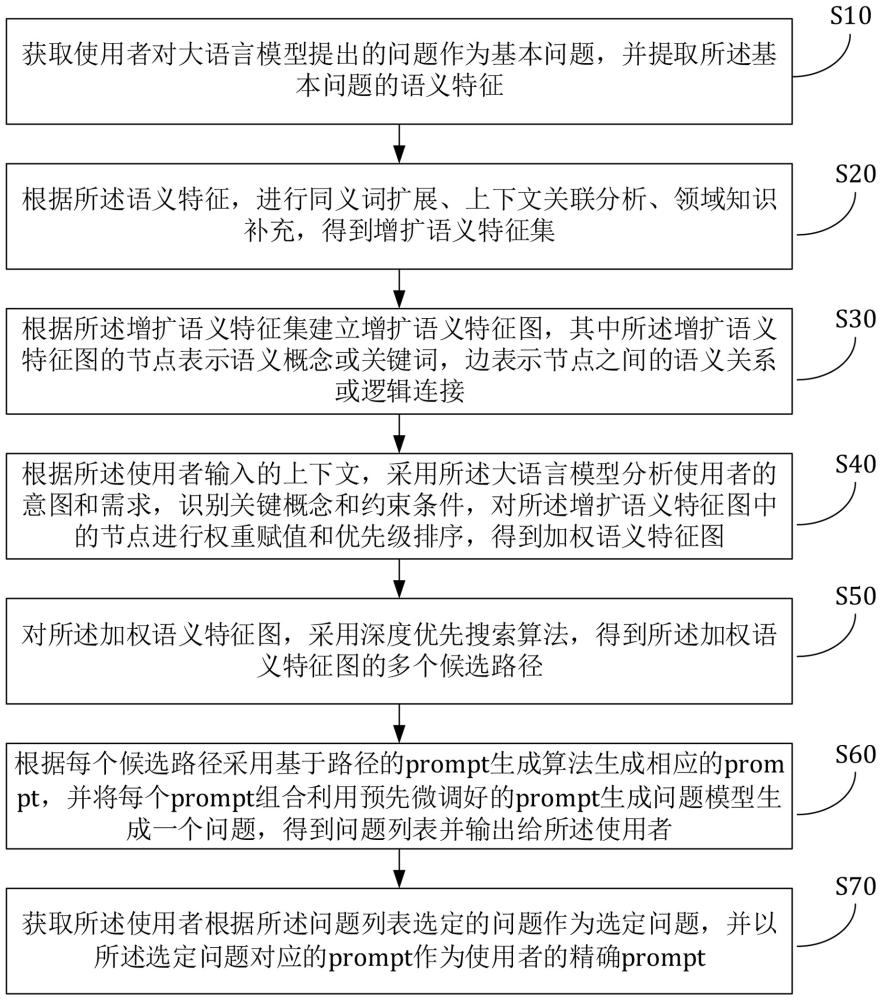
4、s10、获取使用者对大语言模型提出的问题作为基本问题,并提取所述基本问题的语义特征;
5、s20、根据所述语义特征,进行同义词扩展、上下文关联分析、领域知识补充,得到增扩语义特征集;
6、s30、根据所述增扩语义特征集建立增扩语义特征图,其中所述增扩语义特征图的节点表示语义概念或关键词,边表示节点之间的语义关系或逻辑连接;
7、s40、根据所述使用者输入的上下文,采用所述大语言模型分析使用者的意图和需求,识别关键概念和约束条件,对所述增扩语义特征图中的节点进行权重赋值和优先级排序,得到加权语义特征图;
8、s50、对所述加权语义特征图,采用深度优先搜索算法,得到所述加权语义特征图的多个候选路径;
9、s60、根据每个候选路径采用基于路径的prompt生成算法生成相应的prompt,并将每个prompt组合利用预先微调好的prompt生成问题模型生成一个问题,得到问题列表并输出给所述使用者;
10、s70、获取所述使用者根据所述问题列表选定的问题作为选定问题,并以所述选定问题对应的prompt作为使用者的精确prompt。
11、在上述技术方案的基础上,本发明的一种获取使用者精确prompt的方法还可以做如下改进:
12、其中,所述prompt生成问题模型以所述大语言模型为基础模型,通过预设的大量高质量的prompt-问题对进行微调训练得到。
13、具体而言,所述步骤s10为语义特征提取步骤,具体包括:将用户提出的基本问题进行分词和词性标注,获得问题中各个词语的基本信息;计算每个词的tf-idf值,以反映词语在问题中的重要程度;识别问题中的命名实体,发现人名、地名、组织名等重要概念;提取问题中的关键短语,能够更好地捕捉问题的语义信息。将上述三类特征综合起来,形成问题的语义特征向量,为后续的语义特征扩展和增扩语义特征图构建奠定基础。
14、其中,所述步骤s20为语义特征扩展步骤,具体包括:对提取的语义特征向量中的每个特征,在同义词词典或词嵌入模型中查找其同义词,进行同义词扩展;定义一个上下文窗口,分析每个特征的前后邻词,提取高频共现词作为上下文相关词;将特征映射到知识图谱或领域本体库中,提取与这些实体直接相连的节点作为补充知识。通过上述三种扩展方式,丰富原有的语义特征,为后续的增扩语义特征图构建提供更全面的信息。
15、其中,所述步骤s30为增扩语义特征图构建步骤,具体包括:将扩展后的语义特征作为图的节点,根据节点之间的相似度大于一定阈值的条件,在图中添加边,表示节点之间的语义关联;为每条边赋予权重,表示节点之间的关联强度。通过这种方式,构建出一个反映语义概念及其关系的增扩语义特征图,为后续的加权语义特征图生成提供基础。
16、其中,所述步骤s40为加权语义特征图生成步骤,具体包括:根据用户输入的上下文信息,计算每个节点的相关性得分,反映节点与用户需求的相关程度;采用pagerank算法或中心度计算,得到每个节点的重要性得分,反映节点在整个语义体系中的地位和影响力。将相关性得分和重要性得分共同作用于增扩语义特征图的边权重,得到加权语义特征图,突出与用户需求相关且重要的语义概念。
17、其中,所述步骤s50为候选路径生成步骤,具体包括:确定加权语义特征图中权重最高的节点作为起始节点,选择与用户意图最相关的节点作为终止节点;采用深度优先搜索算法,在加权语义特征图上探索从起始节点到终止节点的多条候选路径,为后续的prompt生成提供基础。通过这种方式,可以获得反映语义概念之间逻辑关系和推理过程的多个候选路径。
18、其中,所述步骤s60为prompt生成步骤,具体包括:定义一个prompt模板函数,将候选路径中的节点填充到预定义的模板中,生成初步的prompt;考虑prompt的连贯性,计算路径中相邻节点的语义相似度,确保prompt内部语义的连续性和流畅性;考虑prompt的多样性,计算当前prompt与其他prompt的jaccard距离,确保不同prompt之间的差异性。将这些因素综合考虑,生成多个候选prompt供用户选择。
19、其中,所述步骤s70为精确prompt获取步骤,具体包括:将步骤s60生成的多个候选prompt呈现给用户,让用户根据自身需求进行选择;用户选择的prompt作为最终的精确prompt,作为大语言模型后续处理的输入。通过这种交互式的方式,确保最终获得的prompt能够精确满足用户的实际需求。
20、可选的,在步骤s10中,所述语义特征提取算法还可以包括利用深度学习模型对问题进行语义表示学习,得到问题的嵌入表示,作为语义特征向量的一部分。这种基于深度学习的语义特征提取方式,能够更好地捕捉问题中隐含的语义信息。
21、可选的,在步骤s20中,所述同义词扩展还可以结合上下文信息,选择与当前问题更加相关的同义词,进一步提高语义特征的针对性。同时,在领域知识补充时,还可以考虑利用问题中出现的关键词,对知识图谱或本体库进行更精准的查找和关联,获取更加贴近问题的补充知识。
22、可选的,在步骤s40中,所述节点重要性得分的计算除了使用pagerank算法,还可以采用其他中心度指标,如度中心性、接近中心性等,根据具体应用场景选择合适的算法。
23、可选的,在步骤s50中,所述深度优先搜索算法还可以结合启发式搜索策略,如a*算法,以提高路径探索的效率和质量。同时,还可以设置多个终止节点,生成面向不同用户意图的多组候选路径。
24、其中,提取所述基本问题的语义特征,具体表示为:
25、所述语义特征提取算法具体表示如下:
26、;
27、式中,为提取的语义特征向量;为基本问题;为第个特征提取函数;为第个特征的权重;为特征提取函数的数量;为问题的嵌入表示;为嵌入表示的权重系数。
28、参数获取方法:
29、可以通过不同的自然语言处理技术实现,如tf-idf、词性标注、命名实体识别等。具体步骤如下:
30、步骤1:对问题进行分词和词性标注;
31、步骤2:计算每个词的tf-idf值;
32、步骤3:识别命名实体;
33、步骤4:提取关键短语。
34、和默认,每个相等,取的均值;或者,和通过机器学习模型训练得到,训练数据为大量标注好的问题-特征对。
35、通过预训练的语言模型(如chatglm6b、通义千问)获得。
36、根据所述语义特征,进行同义词扩展、上下文关联分析、领域知识补充,得到增扩语义特征集,具体表示如下:
37、;
38、式中,为扩展后的语义特征集;为原始语义特征向量;为同义词扩展函数;为上下文关联分析函数;为领域知识补充函数;为各扩展方式的权重系数。
39、参数获取方法:
40、通过同义词词典或词嵌入模型计算得到,具体步骤如下:
41、步骤1:对于中的每个特征,在同义词词典中查找其同义词;
42、步骤2:使用词嵌入模型计算相似度,选择相似度高于阈值的词作为同义词。
43、通过上下文窗口分析或主题模型得到,具体步骤如下:
44、步骤1:定义上下文窗口大小;
45、步骤2:对于中的每个特征,分析其前后个词,提取高频共现词。
46、通过知识图谱或领域本体库获得,具体步骤如下:
47、步骤1:将中的特征映射到知识图谱中的实体;
48、步骤2:提取与这些实体直接相连的节点作为补充知识。
49、默认均为1/3,或者优选通过交叉验证方法确定最优值。
50、所述增扩语义特征图构建算法具体表示如下:
51、;
52、;
53、;
54、;
55、式中,为增扩语义特征图;为节点集合,对应扩展后的语义特征;为边集合;为边权重矩阵;为节点和之间的相似度函数;为相似度阈值。
56、参数获取方法:
57、可以通过余弦相似度或jaccard相似度计算:
58、;
59、;
60、默认为0.75,或者通过实验确定,可以从0.5开始,逐步调整以获得最佳性能。
61、所述加权语义特征图生成算法具体表示如下:
62、;
63、;
64、;
65、式中,为加权语义特征图;为新的边权重矩阵;为矩阵元素wise乘法;为调整矩阵;为sigmoid函数;为节点的相关性得分;为节点的重要性得分。
66、参数获取方法:
67、通过与用户输入上下文的相关性计算得到:
68、;
69、其中,为用户输入上下文中的词集合。
70、通过pagerank算法或中心度计算得到:
71、;
72、其中,为阻尼因子,通常取0.85;为节点的邻居节点集合。
73、所述深度优先搜索算法具体表示如下:
74、;
75、;
76、式中,为候选路径集合;为起始节点;为终止节点;为最大路径长度;为节点的邻居节点集合。
77、参数获取方法:
78、选择为加权语义特征图中权重最高的节点;
79、选择为与用户意图最相关的节点;
80、通过实验确定,通常取值范围为3-7。
81、所述基于路径的prompt生成算法具体表示如下:
82、;
83、式中,为第个候选路径生成的prompt;为第个候选路径;为模板填充函数;为连贯性评分函数;为多样性评分函数;为权重系数。
84、参数获取方法:
85、通过预定义的prompt模板实现,将路径中的节点填入模板中的占位符。
86、通过计算路径中相邻节点的语义相似度得到:
87、;
88、通过计算当前路径与其他路径的平均jaccard距离得到:
89、;
90、默认的均为0.5,另外的,也可以通过网格搜索和交叉验证确定最优值。
91、本发明的第二方面提供一种计算机可读存储介质,其中,所述计算机可读存储介质中存储有程序指令,所述程序指令在计算机中运行时,用于执行上述的一种获取使用者精确prompt的方法。
92、本发明的第三方面提供一种获取使用者精确prompt的系统,其中,包含上述的计算机可读存储介质。
93、与现有技术相比较,本发明提供的一种获取使用者精确prompt的方法、介质及系统的有益效果是:
94、1.语义特征的提取和扩展更加全面和动态。除了利用静态的词典和知识库,本方法还结合预训练的语言模型,对问题进行深层次的语义表示学习,捕捉隐含的语义信息。同时,在同义词扩展、上下文关联分析、领域知识补充等方面,充分利用了上下文信息和先验知识,使得语义特征更加贴近问题的实际语义。
95、2.增扩语义特征图的构建和加权更加智能。本方法不仅考虑节点之间的相似度关系,还引入了节点的相关性和重要性信息,通过加权调整,使得与用户需求更加相关且在整个语义体系中地位更重要的概念受到更多关注。这种基于语义特征图的建模和分析方式,能够更好地反映问题涉及的语义结构和内在逻辑。
96、3.prompt生成不仅考虑短语级别的模板填充,还针对prompt的整体连贯性和差异性进行了优化。通过计算候选路径中相邻节点的语义相似度,确保生成prompt的内部语义流畅;同时,通过分析不同prompt之间的jaccard距离,提高了prompt选择的多样性,满足了用户对差异化选择的需求。
97、总的来说,本发明提出的方法充分利用了语义分析、知识图谱、图算法等技术手段,综合考虑了用户需求、语义关联、概念重要性等多方面因素,能够较好地从用户的基本问题中提取并生成满足用户实际需求的精确prompt。解决了现有技术中prompt生成偏重于短语级别的模板填充,缺乏对prompt整体连贯性和差异性的考虑的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!