一种视觉语言模型部署优化方法及装置与流程
本发明涉及图像处理,特别是涉及一种视觉语言模型部署优化方法及装置。
背景技术:
1、对象检测能够识别出图像或视频中的特定对象,随着深度学习技术的不断发展,通常是利用视觉语言模型对图像进行对象检测。
2、相关技术中,通常是利用视觉语言模型,串行对图像进行对象检测,即先对一图像进行对象检测,待对该图像进行对象检测完毕之后,再对下一图像进行对象检测。
3、在对大量图像进行对象检测场景下,现有的视觉语言模型串行对图像进行对象检测的方式无法满足高效对象检测的需求。
4、因此,亟需一种视觉语言模型部署优化方法,以满足高效对象检测的需求。
技术实现思路
1、本发明实施例的目的在于提供一种视觉语言模型部署优化方法及装置,以满足高效对象检测的需求。具体技术方案如下:
2、第一方面,本发明实施例提供了一种视觉语言模型部署优化方法,所述方法包括:
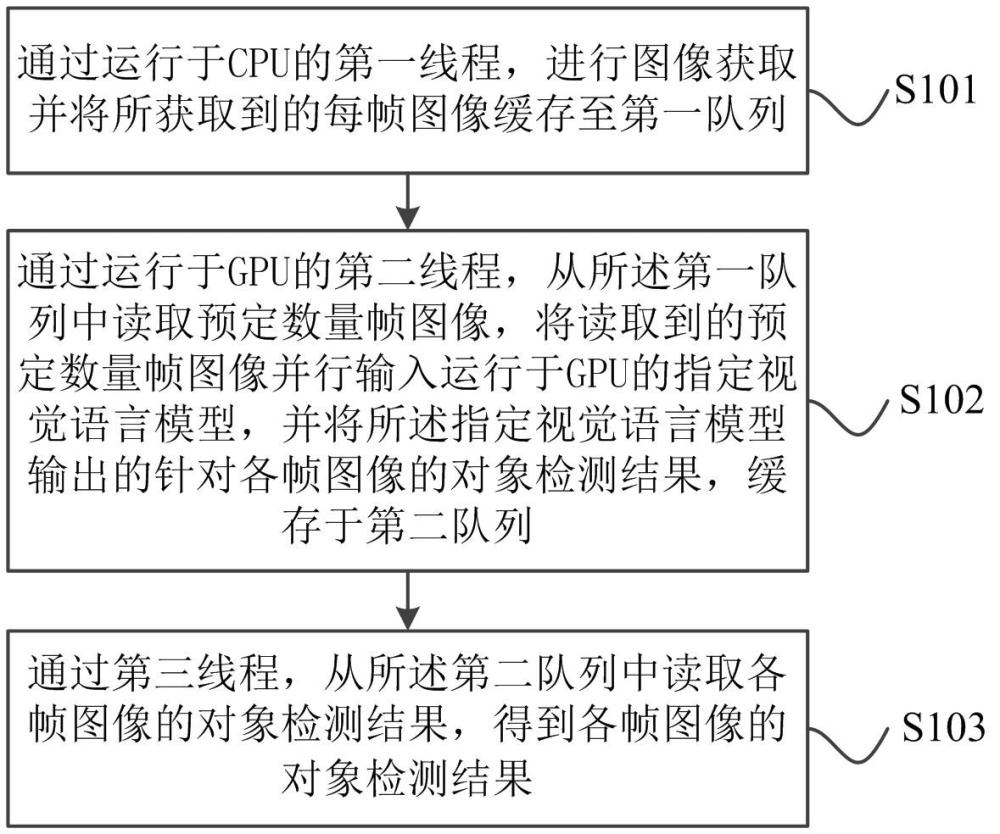
3、通过运行于cpu的第一线程,进行图像获取并将所获取到的每帧图像缓存至第一队列;
4、通过运行于gpu的第二线程,从所述第一队列中读取预定数量帧图像,将读取到的预定数量帧图像并行输入运行于gpu的指定视觉语言模型,并将所述指定视觉语言模型输出的针对各帧图像的对象检测结果,缓存于第二队列;其中,所述指定视觉语言模型为针对目标视觉语言模型进行预定加速处理后所得到的视觉语言模型,且所述指定视觉语言模型的对于图像的并行输入数量设置为所述预定数量;
5、通过第三线程,从所述第二队列中读取各帧图像的对象检测结果,得到各帧图像的对象检测结果。
6、可选地,所述将读取到的预定数量帧图像并行输入运行于gpu的指定视觉语言模型,包括:
7、调用gpu以对于所述预定数量帧图像进行图像预处理;
8、将图像预处理后的所述预定数量帧图像并行地输入所述指定视觉语言模型。
9、可选地,所述目标视觉语言模型包括图像处理网络和文本处理网络,所述图像处理网络包括特征提取模块、特征融合模块以及对象检测模块;
10、其中,所述文本处理网络用于对目标文本进行特征提取,得到文本特征,并将所述文本特征输入所述特征融合模块,所述目标文本为表征对象检测需求的文本;
11、所述特征提取模块用于针对所输入的、所述预定数量帧图像中的每一帧图像进行特征提取,得到该帧图像的图像特征,并输入至所述特征融合模块;
12、所述特征融合模块用于针对所接收到的每帧图像的图像特征,将该帧图像的图像特征以及所述文本特征进行融合,得到该帧图像对应的融合特征,并输入所述对象检测模块;
13、所述对象检测模块用于针对所接收到的每帧图像对应的融合特征,根据该帧图像对应的融合特征进行对象检测,得到该帧图像对应的对象检测结果。
14、可选地,所述指定视觉语言模型的图像处理网络的指定输入参数为动态参数;其中,所述指定输入参数为用于指示图像并行输入数量的参数;
15、所述指定视觉语言模型的对于图像的并行输入数量设置为所述预定数量的设置方式包括:
16、将所述图像处理网络的指定输入参数的数量设置为所述预定数量;
17、所述文本处理网络的特征维度参数为动态参数;所述方法还包括:
18、将所述文本处理网络的特征维度参数设置为与所述预定数量相匹配的数量;其中,所述特征维度参数为用于指示所提取的文本特征的维度数量的参数。
19、可选地,所述从所述第二队列中读取各帧图像的对象检测结果,得到各帧图像的对象检测结果,包括:
20、从所述第二队列中读取各帧图像的对象检测结果;
21、通过音视频处理模块对各帧图像的对象检测结果进行处理,得到包含各帧图像的对象检测结果的推流结果。
22、第二方面,本发明实施例提供了一种视觉语言模型部署优化装置,所述装置包括:
23、获取模块,用于通过运行于cpu的第一线程,进行图像获取并将所获取到的每帧图像缓存至第一队列;
24、输入模块,用于通过运行于gpu的第二线程,从所述第一队列中读取预定数量帧图像,将读取到的预定数量帧图像并行输入运行于gpu的指定视觉语言模型,并将所述指定视觉语言模型输出的针对各帧图像的对象检测结果,缓存于第二队列;其中,所述指定视觉语言模型为针对目标视觉语言模型进行预定加速处理后所得到的视觉语言模型,且所述指定视觉语言模型的对于图像的并行输入数量设置为所述预定数量;
25、读取模块,用于通过第三线程,从所述第二队列中读取各帧图像的对象检测结果,得到各帧图像的对象检测结果。
26、可选地,所述输入模块,具体用于:
27、调用gpu以对于所述预定数量帧图像进行图像预处理;
28、将图像预处理后的所述预定数量帧图像并行地输入所述指定视觉语言模型。
29、可选地,所述目标视觉语言模型包括图像处理网络和文本处理网络,所述图像处理网络包括特征提取模块、特征融合模块以及对象检测模块;
30、其中,所述文本处理网络用于对目标文本进行特征提取,得到文本特征,并将所述文本特征输入所述特征融合模块,所述目标文本为表征对象检测需求的文本;
31、所述特征提取模块用于针对所输入的、所述预定数量帧图像中的每一帧图像进行特征提取,得到该帧图像的图像特征,并输入至所述特征融合模块;
32、所述特征融合模块用于针对所接收到的每帧图像的图像特征,将该帧图像的图像特征以及所述文本特征进行融合,得到该帧图像对应的融合特征,并输入所述对象检测模块;
33、所述对象检测模块用于针对所接收到的每帧图像对应的融合特征,根据该帧图像对应的融合特征进行对象检测,得到该帧图像对应的对象检测结果。
34、可选地,所述指定视觉语言模型的图像处理网络的指定输入参数为动态参数;其中,所述指定输入参数为用于指示图像并行输入数量的参数;
35、所述指定视觉语言模型的对于图像的并行输入数量设置为所述预定数量的设置方式包括:
36、将所述图像处理网络的指定输入参数的数量设置为所述预定数量;
37、所述文本处理网络的特征维度参数为动态参数;所述装置还包括:
38、设置模块,用于将所述文本处理网络的特征维度参数设置为与所述预定数量相匹配的数量;其中,所述特征维度参数为用于指示所提取的文本特征的维度数量的参数。
39、可选地,所述读取模块,具体用于:
40、从所述第二队列中读取各帧图像的对象检测结果;
41、通过音视频处理模块对各帧图像的对象检测结果进行处理,得到包含各帧图像的对象检测结果的推流结果。
42、本发明实施例有益效果:
43、本发明实施例提供的视觉语言模型部署优化方法,通过运行于cpu的第一线程进行图像获取,并将所获取到的每帧图像缓存至第一队列;通过运行于gpu的第二线程,从第一队列中读取预定数量帧图像,并行输入至运行于gpu的指定视觉语言模型,并将指定视觉语言模型输出的针对各帧图像的对象检测结果,缓存于第二队列;再通过第三线程,从第二队列中读取各帧图像的对象检测结果,得到各帧图像的对象检测结果。其中,本发明实施例中的指定视觉语言模型为针对目标视觉语言模型进行预定加速处理后所得到的视觉语言模型,即指定对象检测模型为部署优化的视觉语言模型,指定视觉语言模型的对于图像并行输入数量设置为预定数量,从而,指定视觉语言模型可以对预定数量帧图像并行进行高效率的对象检测。本发明第一线程运行于cpu,第二线程运行于gpu,使得cpu和gpu的资源得到最大化利用,通过多个线程、多个队列,以及加速处理的指定视觉语言模型,可以并行对预定数量帧图像进行对象检测,达到提高对象检测的效率的目的,满足高效对象检测的需求。
44、当然,实施本发明的任一产品或方法并不一定需要同时达到以上所述的所有优点。
- 还没有人留言评论。精彩留言会获得点赞!