基于多粒度解码约束的缅甸语图像文本识别方法及装置
本发明基于多粒度解码约束的缅甸语图像文本识别方法及装置,属于自然语言处理。
背景技术:
1、缅甸语具有独特的编码顺序和字符组合规则。除了基本的辅音字符外,还包括左拼元音字符、上拼元音字符和右拼元音字符,下拼音调字符等修饰符。这些修饰符可以嵌套在基本字符的不同位置,形成复杂的字符组合;
2、缅甸语的一个音节可能由多个独立unicode编码的字符组成,这种组合嵌套的特性使得缅甸语的字符识别任务比中英等线性的字符识别方法更加复杂,在识别过程中往往会忽略其字符的边缘特征,导致解码时部分字符误识或丢失,使识别结果出现乱码。此外部分缅甸语字符之间的高度相似性同样给缅甸文识别任务带了很大的干扰,相似的字符往往会导致识别结果出现字符混淆的现象,因此识别模型只有捕捉更为细粒度的特征才能缓解这一现象。
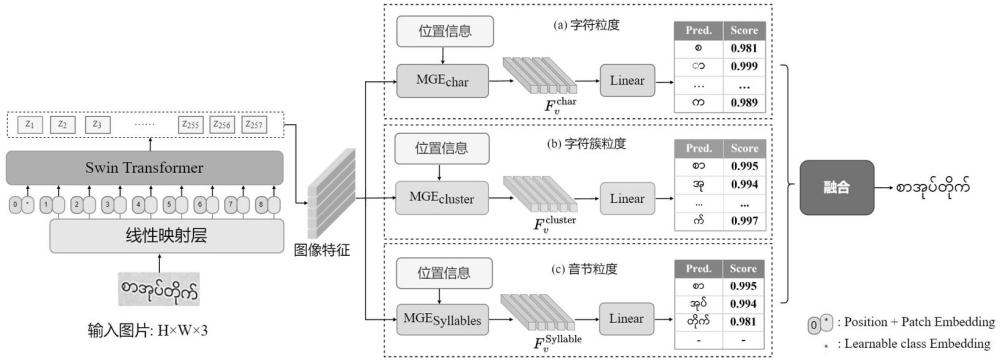
3、针对上述问题,本发明提出了基于多粒度解码约束的缅甸语图像文本识别方法及装置。在原有字符序列解码的基础上,引入具有语言知识的字符簇序列和音节序列,建立解码约束,将语言知识隐式的融入到解码过程中,增强形似组合字符的区分能力。同时通过语言特性驱动的多粒度特征抽取模块,自适应捕捉字不同粒度的视觉特征,并将其于位置信息更好的对齐。最后,在推理阶段将三种粒度的预测进行融合,得到最终的识别结果。
技术实现思路
1、本发明提出基于多粒度解码约束的缅甸语图像文本识别方法及装置,用于解决缅甸语图像中形似字符识别不佳的问题及因图像质量不佳而导致的缅甸语形似字符识别困难问题,本发明识别准确率高。
2、本发明的技术方案是:基于多粒度解码约束的缅甸语图像文本识别方法,所述方法的具体步骤如下:
3、step1、缅甸语文本图像数据集构建及预处理;
4、step2、构建基于多粒度解码约束的缅甸语文本图像识别模型,包括:
5、step2.1、设计基于滑动窗口的transformer提取缅甸语的文本图像特征,获取原始视觉特征;
6、step2.2、设计语言特性驱动的多粒度特征抽取模块:用于从原始视觉特征中自适应地提取不同粒度的视觉特征,并将这些特征与相应粒度的字符位置对齐,用于支持后续的多粒度解码过程;其中,使用语言特性驱动的多粒度特征抽取模块分别捕捉字符级、字符簇级以及音节级不同粒度的视觉特征;
7、step2.3、设计多粒度特征融合模块对捕捉到的不同粒度的视觉特征,采用置信度融合策略进行解码约束,得到最终的预测文本结果;这一过程显著增强了模型对于缅甸语中易混淆形似字符的识别准确率;
8、step3、用构建好的基于多粒度解码约束的缅甸语文本图像识别模型进行缅甸语文本图像识别。
9、进一步地,所述step1的具体步骤为:
10、step1.1、从互联网中收集缅甸语文本数据,然后进行去重、切分、过滤特殊字符预处理步骤,构建一个缅甸语的文本标签数据集,用于后续缅甸语文本图像的生成;通过互联网获取真实场景的缅甸语文本图像;
11、step1.2、利用文本编辑网络,在不破坏原始图像真实感的前提下,替换或修改自然图像中的文本,从而生成文本图像;具体通过文本转换模块、背景修复模块和融合模块生成文本图像;
12、文本转换模块用于将目标文本的语义与源图像中文本的风格相结合,包括字体、颜色、位置和尺度;该模块引入了骨架引导学习机制,通过预测文本骨架图来指导文本风格的迁移;
13、背景修复模块用于负责擦除原始文本并填充适当的纹理,采用u-net的结构,通过编码器-解码器架构实现背景的重建;
14、融合模块用于将文本转换模块和背景修复模块的输出信息进行有效融合,生成最终的编辑文本图像,并根据最终的图像切分训练集、测试集以及验证集。
15、进一步地,所述step2.1包括:
16、构建基于滑动窗口的transformer作为主干网络,利用其对输入的缅甸语文本图像进行特征提取,并将图像转化为token序列;具体包括:首先通过patch切分模块将原始图像分成尺寸为p×p的图像块,然后使用一个线性嵌入层将这个原始值的特征投影到维度,并展平为二维的向量,其中是每个小块的分辨率,是的通道数,表示图片块序列的长度,h、w、c分别为图片的高度、宽度以及通道数;token序列然后被送入窗口内自注意力w-msa和窗口间自注意力sw-msa进行建模,w-msa和sw-msa能够对图像进行自注意力建模,同时保持局部感知和全局感知的能力,具体计算过程如下:
17、;
18、;
19、式中,和分别表示w-msa模块和sw-msa模块的输出;表示归一化层,滑动窗口的transformer中基于自注意力的表示学习计算公式为:
20、;
21、其中,表示查询矩阵;表示键矩阵;表示值矩阵;表示偏置矩阵,d1表示图片特征矩阵的维度,s表示当前网络模块的层数,编码器将缅甸语图片送入到堆叠的滑动窗口的transformer中,经过多阶段的网络学习最终得到原始视觉特征用于后续的文本识别。
22、进一步地,所述step2.2中,设计语言特性驱动的多粒度特征抽取模块包括位置信息增强和多粒度视觉信息抽取两个部分,用于从原始视觉特征中自适应地提取不同粒度的特征,并将这些特征与相应粒度的字符位置对齐;同时鉴于在不同粒度解码时同一时刻关注的位置信息不同,设计了一个多分支的视觉信息抽取模块,用以分别关注字符、字符簇以及音节粒度的视觉特征,用于后续的多粒度解码。
23、进一步地,所述step2.2包括:
24、step2.2.1、针对不同粒度字符的位置编码,利用了一种位置增强并行注意力机制,旨在强化字符的位置信息;具体而言,首先构造一个特征序列,其中每个特征在其对应的位置索引维度上被赋予一个固定的常数1/l,而在其他维度上则置为零,这里的l代表输入文本的总长度;随后,采用了正弦与余弦函数对位置进行编码,具体公式如下:
25、;
26、;
27、其中,表示位置信息,为字符的位置,表示向量的维度,引入基于自注意力的位置强化策略,通过模型反向传播实现对不同粒度解码时更有针对性的位置嵌入,将位置信息与视觉信息动态融合,用于达到更好的识别精度;同时,使用上三角掩码mask应用于查询向量;最后,通过两个mlp层位置线索注入到查询向量q中;相关性信息计算方式如下:
28、;
29、;
30、其中,为多头注意力机制计算的函数名,为函数的形参,, , 分别表示q、k和v的权重矩阵, 函数表示将不同注意力头的输出组合起来, 为可训练的权重矩阵,代表自注意力网络,ffn 代表前馈网络;最终,通过多层感知器和残差连接和层归一化得到位置信息增强的特征;表示多头自注意力机制中的第n个注意力头;
31、step2.2.2、使用位置信息增强的特征作为查询与初始视觉特征进行交叉注意力;旨在利用先前不同粒度解码的字符位置来搜索文本图像中的待识别字符区域;具体来说,查询q是经过位置增强模块增强的位置特征,k和v采用的是使用滑动窗口的transformer提取的初始视觉特征,初始视觉特征经过交叉注意力模块、多层感知器、残差连接和层归一化处理得到不同粒度的视觉特征,其中交叉注意力模块为:
32、<msubsup><mi>f</mi><mi>v</mi><mi> i1</mi></msubsup><mi>=atten</mi><mrow><msub><mi>[f</mi><mi>pos</mi></msub><mi>,</mi><msub><mi>z</mi><mi>m</mi></msub><mi>]</mi></mrow></mfenced><mi>+ffn</mi><mi>(i1=char,cluster,syllable)</mi>;
33、其中,ffn 代表前馈网络,是交叉注意力机制计算的函数名,分别表示提取的字符、字符簇以及音节的视觉特征,交叉注意力模块提取并整合的多种粒度视觉特征用于后续的多粒度解码。
34、进一步地,所述step2.3包括:
35、step2.3.1、经过语言特性驱动的多粒度特征抽取模块后得到的字符级、字符簇级以及音节级不同粒度的视觉特征定义为[],其中,用于后续的多粒度特征解码;
36、step2.3.2、通过线形层网络将不同粒度的视觉特征[]转录为各自粒度的字符及其置信度,置信度的计算方式如下公式所示:
37、 ()
38、其中,表示不同粒度解码的置信度,为线性层网络函数,最终得到的是不同粒度的置信度合集 = {...};
39、step2.3.3、多粒度预测的分类结果由不同的分类头生成,采用基于置信度融合的策略来合并预测最终的文字结果;具体而言,每个字符、字符簇和音节的识别置信度通过融合函数生成最终的识别分数,识别分数具体公式如下:
40、 ();
41、其中, 表示不同粒度解码的置信度,通过每个字符的置信度累积得到文本图像的三个分类头的三个识别分数,选择识别分数最高的文本结果作为最终的预测结果。
42、进一步地,所述step2.3中,通过不同粒度的分类头得到预测结果,模型训练时采用交叉熵损失函数作为缅甸语文本识别模型的目标优化函数,计算方式如下公式所示:
43、;
44、;
45、其中, 为输入的缅甸语文本图像,为当前识别网络的模型参数, 为缅甸语文本图像的第 个特征序列对应的标签, 是用于平衡损失的超参数,、和表示用于平衡损失的超参数。
46、进一步地,所述step3包括:
47、对构建好的基于多粒度解码约束的缅甸语文本图像识别模型输入的参数进行了优化,实现图像数据的批量处理,并将训练收敛的模型进行了封装处理,以便在服务器上部署,在此基础上,构建了一套api接口,用于实现对缅甸语文本图像的高效识别。
48、本发明还提供基于多粒度解码约束的缅甸语图像文本识别装置,包括用于执行所述基于多粒度解码约束的缅甸语图像文本识别方法的模块。
49、本发明的有益效果是:
50、1. 本发明首先使用基于滑动窗口的transformer的图像特征提取网络获取缅甸语文本图像特征,然后通过语言特性驱动的多粒度特征抽取模块分别抽取字符、字符簇以及音节粒度的视觉特征,然后将不同粒度的特征输入到多粒度特征融合模块中进行解码,最后通过置信度融合策略对解码的结果进行约束,从而对语言信息进行隐式建模,提高识别的准确率。
51、2.本发明提供了语言特性驱动的多粒度特征抽取方法,在原有字符特征的基础上,引入具有语言知识的字符簇序列和音节序列特征的视觉特征,在保证字符级别的基本识别精度的基础上,将字符簇级或音节级粒度的预测作为对噪声图像预测结果的补充,从而对增强形似组合字符的区分能力。
52、3.本发明利用一个基于视觉tranformer结构代替传统的cnn结构,该结构能够通过对视觉特征进行全局的注意力计算,以建模整张图像的全局信息。同时,基于置信度融合策略对识别结果进行解码约束,极大地提升了识别效率。
- 还没有人留言评论。精彩留言会获得点赞!