一种基于多智能体强化学习的供应链自动化合约代理方法
本发明涉及博弈论和人工智能双领域,尤其涉及一种基于多智能体强化学习的供应链自动化合约代理方法。
背景技术:
1、1、多智能体强化学习marl专注于优化多个决策实体在动态环境中的交互,通过整合博弈论和机器学习原理,marl 使智能体能够学习和探索的社会交互场景,从而提升决策质量和战略规划的效率。
2、2、供应链交易中,博弈理论及其互利合作对社会有着重大影响,这种合作关系不仅稳定了市场价格,也为经济增长提供了动力。
3、3、多智能体系统mas中,智能体具备独立的谈判能力,能够在快速变化的环境中就目标或行动计划达成共识,对于需要迅速做出决策的场景至关重要。
技术实现思路
1、本发明为解决上述的技术问题,提出一种基于多智能体强化学习的供应链自动化合约代理方法。
2、一种基于多智能体强化学习的供应链自动化合约代理方法,包括以下步骤:
3、s1:根据斯塔克尔伯格模型和鲁宾斯坦模型具体建模供应链交易的两种典型场景;
4、s2:通过斯塔克尔伯格模型和鲁宾斯坦模型获取专家经验,对智能体行为员网络进行基于专家经验的预训练;
5、s3:根据博弈特性引入基于对手策略的价值预测、应用时序模型进行历史交易序列的特征提取、优先级经验回放机制,通过不断地从经验池中获取信息,进行网络优化,集成对手策略模型的架构算法,逐步优化智能体的策略。
6、进一步的,一种基于多智能体强化学习的供应链自动化合约代理方法,包括以下步骤:
7、s1:根据斯塔克尔伯格模型和鲁宾斯坦模型具体建模供应链交易的两种典型场景;
8、s2:通过斯塔克尔伯格模型和鲁宾斯坦模型获取专家经验,对智能体行为员网络进行基于专家经验的预训练;
9、s3:根据博弈特性引入基于对手策略的价值预测、应用时序模型进行历史交易序列的特征提取、优先级经验回放机制,通过不断地从经验池中获取信息,进行网络优化,集成对手策略模型的架构算法,逐步优化智能体的策略。
10、进一步的,一种基于多智能体强化学习的供应链自动化合约代理方法,所述步骤s1包括以下子步骤:
11、s11:在构建的斯塔克尔伯格模型博弈环境中,设定供应商和零售商两种角色,每次交易回合时,供应商设定商品批发价格,零售商则根据商品批发价格决定订货数量,共同完成合同的制定;
12、s12:完成合同后,双方角色与市场进行交互,供应商基于批发价格、零售商的订货量、市场的货物成本计算利润,零售商则根据市场需求量、自身的订货量、批发和零售价格差异计算利润,公式为:
13、;
14、其中,代表供应商的利润,代表零售商的利润,代表供应商设定的批发价格,代表零售商的订货量,代表供应商的商品成本,代表市场的总需求量;
15、s13:通过双方角色交易完成后所获得的利润,计算双方的状态转移方程、状态、动作,公式为:
16、;
17、其中,代表时间步发生的状态,代表供应商时间步发生的动作,代表供应商时间步发生的动作,代表交易内容,代表交易的时间步,代表空集,代表即时奖励;
18、s14:在构建的鲁宾斯坦模型博弈环境中,代理分别扮演供应商和零售商角色,环境模拟交替提供报价的关键特性,引入衰减因子,模拟随着谈判的拖延,报价的效用逐渐减少的情况,在每一轮中,供应商提出批发价格,零售商则回应一个订单量,是否达成交易取决于该轮的谈判动态;
19、s15:根据销售结果和成本计算双方角色的奖励,调整因协议延迟而降低的价值,进行多轮的不完全信息条件谈判游戏,直到交易达成或达到预设的最大回合数,未来收益的价值通过衰减因子进行贴现;
20、s16:当双方未达成交易,则继续谈判,双方的预期效用将按照衰减因子衰减,两个角色将交替进行合同制定和合同决策两个行为,若供应商进行合同的制定,决定合同中的批发价格和订货数量,在这个回合中由零售商决定是否接受这份合同,在下一个回合中双方的角色互换,由零售商决定合同中的批发价格和订货数量而供应商决定是否接受,直到双方达成一致;
21、s17:通过回合数和合同本身的内容,判断双方利润:
22、若双方决策的回合数为超过游戏回合数上限n,两个智能体的利润公式为:
23、;
24、其中,代表智能体供应商的利润,代表智能体零售商的利润,代表衰减因子,反映了随时间推移潜在机会的损失,范围为,代表需求量,代表取最小值,代表零售商的零售价格,由市场决定,代表时间步;
25、若双方决策的回合数超过游戏回合数上限n则双方利润为0;
26、s18:因双方智能体的状态转移方程仅在不同轮次中有差异,通过合同提议方和合同决策方计算智能体的状态转移方程,公式为:
27、;
28、其中,代表状态转移方程,代表成交情况,为,包括批发价格和订货数量,代表本轮次中所有的历史报价信息合同提议方给出的合同内容是否被接受,代表除本轮之外的所有历史交易报价信息,代表供应商或零售商智能体所获得的利润。
29、进一步的,一种基于多智能体强化学习的供应链自动化合约代理方法,所述步骤s2包括以下子步骤:
30、s21:根据基于斯塔克尔伯格模型中的专家经验计算方式,计算供应商和零售商双方的动作与来生成专家数据w(t)与q(w),供应商给出的批发价格由当前交易的时间步决定,而零售商的订货量由当前交易中的批发价格决定;
31、s22:在鲁宾斯坦模型中则双方根据人类设定好的固执-软弱策略,基于时间步生成对应的专家经验;
32、s23:得到专家经验后,使用专家经验对智能体进行预训练:
33、基于专家经验的智能体模仿学习:通过引入大边距分类损失j_e(q)拟合双方的行为员网络动作与专家经验中的对应动作;
34、基于专家经验的智能体示范学习:通过将专家数据提前放入长期优先级回放经验池中,使得行为员网络与评论员网络基于专家经验进行优化集成对手策略模型的架构算法。
35、进一步的,一种基于多智能体强化学习的供应链自动化合约代理方法,所述s21包括以下子步骤:
36、s211:通过斯塔克尔伯格模型使用预训练专家经验,公式为:
37、;
38、其中,代表针对供应商给出的批发价格,零售商决策中占优的订货数量,代表供应商的商品成本,代表市场的总需求量;
39、其中,v 代表温度系数,用于控制针对批发价升高零售商反应的剧烈程度,温度系数v 越高,随着批发价格的增高订货量将以更快的速度下降,代表高斯分布,用于平衡专家经验和探索动作之间的决策;
40、s212:计算专家经验中供应商基于时间给出的批发价,公式为:
41、;
42、其中,代表以时间步为变量的供应商给出的批发价格,为以为时间步的动作取值,n代表游戏回合数上限;
43、s213:模仿学习拟和智能体的策略与专家策略, iql的模仿学习过程,大边距分类损失被引入改善初始策略的效率,使智能体快速探索到有效策略,公式为:
44、;
45、其中,代表大边距分类损失,代表动作的集合,代表专家经验在状态s中采取的行动,代表网络,代表当前状态-动作对的价值;
46、其中,代表当a = 时为 0,否则为正的边距函数,迫使其他动作的价值至少比示范动作的价值低一个边距。
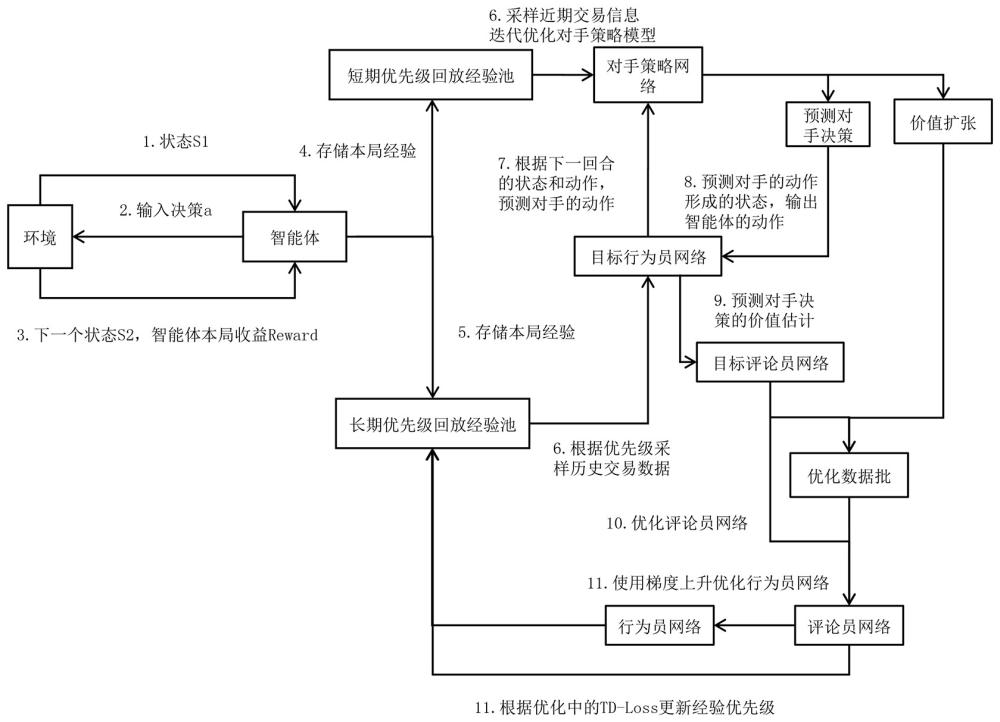
47、进一步的,一种基于多智能体强化学习的供应链自动化合约代理方法,所述s22包括以下子步骤:
48、s221:假设游戏回合数上限为n 个回合,最终达成的协议为 contract∗,固执谈判协议为contractb,软弱谈判协议为contract;
49、则固执谈判策略会在最终回合附近修改自己的协议contractb,快速变为contract∗,在整轮博弈任务中表现为坚持自己的最初决策;
50、则软弱谈判策略下,智能体在开始的几个回合内就修改自己的协议contract快速变为 contract∗,在整轮博弈任务中表现为容易向另一方妥协;
51、s222:鲁宾斯坦环境中采用的专家策略在不同回合内达成交易的固执谈判策略与软弱谈判策略两两组合,作为人类交易者在供应链交易中形成协议的常见经验给予智能体进行学习。
52、进一步的,一种基于多智能体强化学习的供应链自动化合约代理方法,所述s3包括以下子步骤:
53、s31:环境发送状态给智能体,智能体从环境中获取输入信息并做出决策,智能体根据当前的状态输入决策反馈下一个状态,在智能体做出决策后,环境根据决策提供反馈,进入下一个状态,并给智能体提供一个即时奖励;
54、s32:存储短期经验当前的决策和环境反馈被存储到短期优先级回放经验池中,供后续优化使用,存储长期经验时,当前的决策和反馈也会被存储到长期优先级回放经验池中,用于更长时间尺度的优化;
55、s33:从经验池采样数据从短期和长期的优先级经验池中抽取样本进行训练,进行策略的优化,使用优先级经验回放机制更新并决定需要采样的数据;
56、s34:对手策略网络优化针对对手的策略网络进行优化,根据预期策略的损失函数训练对手策略网络模型,预测对手行为根据目标行为网络预测下一回合的对手策略,智能体使用优化后的策略预测对手的行为;
57、s35:目标行为网络优化对目标行为网络进行优化,基于对手策略的反馈修正行动,基于优化过的经验样本优化评论员网络;
58、s36:使用从评论员网络获得的反馈,最终优化行为网络,根据td-loss时间差分损失对模型的性能进行调整和优化,使用优先级经验回放机制更新数据的优先级。
59、进一步的,一种基于多智能体强化学习的供应链自动化合约代理方法,所述优先级经验回放机制包括以下子步骤:
60、i1:计算每个经验的误差,公式为:
61、;
62、其中,代表奖励,代表折扣因子,代表当前状态-动作对的价值,代表下一状态的最大预期价值,代表每个经验的误差;
63、i2:通过累加的绝对值加上常数获得评估经验学习的重要指标优先级,公式为:
64、;
65、其中,z代表优先级,代表常数,设置为,确保每个样本都有被选择的机会;
66、i3:每个样本的采样概率与优先级成正比,公式为:
67、;
68、其中,代表样本的采样概率,代表样本i的采样优先级,代表对所有样本k的优先级进行求和,代表非负参数,用于调整优先级对采样概率的影响,当时,所有样本的采样概率相等,退化为均匀采样。
69、进一步的,一种基于多智能体强化学习的供应链自动化合约代理方法,所述s34包括以下子步骤:
70、s341:最小化模型预测的下一个状态与环境中观察到的实际下一个状态之间的均方误差,公式为:
71、;
72、其中,代表损失函数,代表状态采取动作后实际观察到的下一个状态,代表使用参数的模型,输入 ,后生成的下一个状态,代表模型参数;
73、s342:使用梯度下降更新模型参数,最小化损失函数,公式为:
74、;
75、其中,β代表学习率,代表更新的模型参数,代表损失函数关于模型参数的梯度;
76、s343:通过模型预测未来的状态计算状态的价值,完成价值展开。
77、进一步的,一种基于多智能体强化学习的供应链自动化合约代理方法,所述s343包括以下子步骤:
78、s3431:轨迹采样:从当前状态开始,根据策略选择动作,通过对手策略模型m预测对手的策略;
79、s3432:多步展开:预测下一个状态,连续预测多个步骤,得到一个状态序列 、…;
80、其中,t代表预测的时间范围;
81、s3433:计算累积回报:对于每个预测的状态 ,使用训练好的价值网络v来评估价值,计算从时间t到 t + t 的累积回报,公式为:
82、;
83、其中,代表积累回报,代表折扣因子,r 代表从模型中获得的预测奖励,代表从0…到t的变量,代表预测得到的时刻的状态;
84、s3434:优化:利用扩展的价值视角,通过最小化真实回报与预测回报之间的差异或者最大化预测回报更新策略或价值函数。
85、进一步的,一种基于多智能体强化学习的供应链自动化合约代理方法,所述s13包括以下子步骤:
86、s131:鲁宾斯坦议价博弈框架的供应链交易环境中,展示智能体的可观测状态,矩阵为:
87、;
88、其中,每行包含一个交易回合的数据,包括但不限于合约细节、成交情况及相关双方利润,代表供应商supplier在时间步的利润,代表零售商retailer在时间步的利润;
89、s132:采用lstm 和transformer 模型进行序列决策建模,lstm 模型通过门控单元能有效处理长期和短期的依赖关系,transformer 模型利用位置嵌入来处理序列中的时序信息;
90、s133:transformer 模型的位置嵌入组件通过为每个序列元素添加独特的位置依赖信号,使模型能够捕捉输入序列中元素的相对或绝对位置关系,结合这两种模型,状态矩阵被输入到交易序列特征学习网络。
91、本发明的有益效果为:通过一种基于多智能体强化学习的供应链自动化合约代理方法,在供应链的应用背景中引入了谈判博弈模型,基于斯塔克尔伯格模型和鲁宾斯坦议价博弈框架的两种供应链交易环境,设计多智能体强化学习算法,通过集成蒙特卡洛方法、模仿学习、优先级回放经验池和利用 transformer 进行交易序列建模,显著提升了算法性能,处理复杂和动态的谈判任务,应用对手策略预测与价值展开技术增强了智能体的前瞻性决策能力,基于模仿学习的预训练方法加速了在训练初期的学习过程,引入优先级回放经验池使学习过程更专注于重要的经验,提升了整体的学习效率和策略成熟度。
- 还没有人留言评论。精彩留言会获得点赞!