一种基于大数据的语言翻译方法、电子设备及系统与流程
本发明涉及自然语言处理,具体涉及一种基于大数据的语言翻译方法、电子设备及系统。
背景技术:
1、全球化推进和跨国交流的日益增多使得语言翻译已经成为人们日常生活和商业活动中不可或缺的一部分。且全球范围内的数据量呈现出爆炸式增长,大数据技术的出现为语言翻译系统的改进提供了新的机遇。通过利用大数据,翻译系统可以更加精准地捕捉语言之间的关系,分析语境、识别词汇搭配和常见表达方式,从而提升翻译的准确度和自然度。
2、目前基于nmt(neural machine translation,神经机器翻译)算法的语言翻译技术逐渐成为主流,相较于传统的统计翻译方法,神经网络翻译不仅能更好地捕捉句子层面的语法信息,还能够通过上下文信息进行更自然、流畅的翻译。然而,虽然基于神经网络的翻译方法在准确性和流畅度方面已经取得了显著进展,但是翻译结果仍然存在语序、语境上的问题,使得nmt算法仍然存在一定的局限性。
技术实现思路
1、本发明提供一种基于大数据的语言翻译方法、电子设备及系统,以解决现有的问题。
2、本发明的一种基于大数据的语言翻译方法、电子设备及系统采用如下技术方案:
3、本发明一个实施例提供了一种基于大数据的语言翻译方法,该方法包括以下步骤:
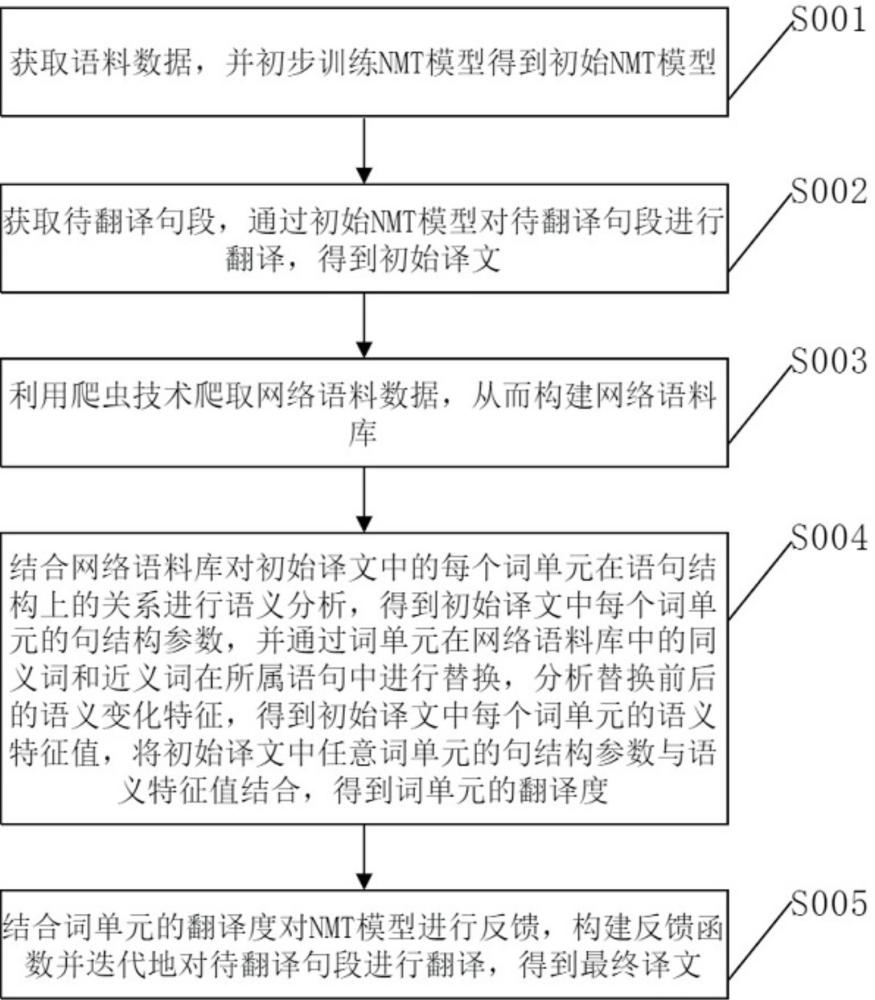
4、获取语料数据,并初步训练nmt模型得到初始nmt模型;
5、获取待翻译句段,通过初始nmt模型对待翻译句段进行翻译,得到初始译文;
6、利用爬虫技术爬取网络语料数据,从而构建网络语料库;
7、结合网络语料库对初始译文中的每个词单元在语句结构上的关系进行语义分析,得到初始译文中每个词单元的句结构参数,并通过词单元在网络语料库中的同义词和近义词在所属语句中进行替换,分析替换前后的语义变化特征,得到初始译文中每个词单元的语义特征值,将初始译文中任意词单元的句结构参数与语义特征值结合,得到词单元的翻译度;
8、结合词单元的翻译度对nmt模型进行反馈,构建反馈函数并迭代地对待翻译句段进行翻译,得到最终译文。
9、进一步地,所述结合网络语料库对初始译文中的每个词单元在语句结构上的关系进行语义分析,得到初始译文中每个词单元的句结构参数,包括的具体方法为:
10、利用jieba分词对初始译文进行分词处理,得到的分词结果中每一个词组作为一个词单元;对于任意词单元,获取在网络语料库中包含所述任意词单元的若干句段,记为所述任意词单元的语料句段;
11、对任意词单元的初始译文以及语料句段进行文本结构分析,获取初始译文和每个语料句段的余弦结构序列;
12、根据初始译文分别与初始译文中每个词单元对应的所有语料句段之间对应的余弦结构序列的相似性,并结合每个词单元对应语料句段的结构特征,获取任意词单元的句结构参数。
13、进一步地,所述对任意词单元的初始译文以及语料句段进行文本结构分析,获取初始译文和每个语料句段的余弦结构序列,包括的具体方法为:
14、首先,对语料句段进行分词得到任意语料句段中的若干词组,称为语料词单元,利用word2vec算法对初始译文中的词单元和所有语料句段中的语料词单元分别进行词向量转换,得到词单元和语料词单元的词向量;
15、然后,在初始译文中获取任意相邻词单元对应词向量的余弦值,得到初始译文中所有相邻词单元的词向量之间余弦值形成的序列,记为初始译文的余弦结构序列;以此类推,获取任意语料句段的余弦结构序列。
16、进一步地,所述任意词单元的句结构参数的具体获取方法为:
17、获取初始译文与语料句段之间的结构因子;
18、所述词单元的句结构参数的具体计算方法为:
19、
20、其中,为初始译文中第个词单元的句结构参数;为初始译文与初始译文中第个词单元的第个语料句段分别对应的余弦结构序列之间的dtw距离;为初始译文中第个词单元的语料句段的数量;为初始译文与初始译文中第个词单元的第个语料句段之间的结构因子;为初始译文中第个词单元的第个语料句段中所有分词与初始译文中词单元相同的数量;为初始译文中第个词单元的第个语料句段中所有分词的数量;为标准差函数。
21、进一步地,所述初始译文与语料句段之间的结构因子的具体获取方法为:
22、获取初始译文与语料句段中相同的分词;将一个分词作为一个节点,按照分词在对应文本中的先后顺序进行连接,并将向后顺序作为对应的连接方向;
23、将相邻分词在对应的文本中之间的间隔作为对应连接边的边权,分别构成初始译文与语料句段对应的链式的分词图结构;
24、通过图编辑距离获取初始译文与语料句段对应的分词图结构之间的图相似度,作为所述初始译文与语料句段之间的结构因子。
25、进一步地,所述词单元的语义特征值的具体获取方法为:
26、获取任意词单元的同义词、近义词,统称为对应词单元的近似词,并获取网络语料库中包含所述词单元的近似词的语料句段,称为所述词单元的近似语料句段;
27、结合初始译文和每个词单元的近似语料句段对词单元进行语义特征分析,获取词单元的语义特征值。
28、进一步地,所述词单元的语义特征值的具体获取方法为:
29、对于任意一个词单元,获取所述词单元对应的所有近似语料句段,获取近似语料句段中所述词单元对应的近似词以及与所述近似词左右相邻的个分词作为所述近似词的邻近分词,获取所述近似词与对应的每个邻近分词关于词向量的余弦值所形成的词组,记为所述近似词的语义特征组,其中为预设的数量参数;
30、对于任意一个词单元,利用所述词单元的所有近似词对所述词单元进行替换,得到新初始译文,获取所述词单元的所有近似词在新初始译文中的语义特征组;以此类推,获取所述词单元对应的语义特征组;
31、基于所述词单元以及对应近似词在不同文本中得到的语义特征组之间的余弦值,计算所述词单元的语义特征值。
32、进一步地,所述词单元的语义特征值的具体计算方法为:
33、
34、其中,表示初始译文中第个词单元的语义特征值;为初始译文中第个词单元的语义特征组;为初始译文中第个词单元被对应的第个近似词替换后,近似词的语义特征组;为初始译文中第个词单元对应的第个近似词在所属第个近似语料句段中的语义特征组;为含有第个近似词的近似语料句段的数量;为初始译文中第个词单元的近似词的数量;为标准差函数;为余弦函数;为以自然常数为底数的指数函数。
35、本发明的实施例提供了一种基于大数据的语言翻译电子设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述的一种基于大数据的语言翻译方法的步骤。
36、本发明的实施例提供了一种基于大数据的语言翻译系统,该系统包括以下模块:
37、初始模型模块,用于获取语料数据,并初步训练nmt模型得到初始nmt模型;
38、初步翻译模块,用于获取待翻译句段,通过初始nmt模型对待翻译句段进行翻译,得到初始译文;
39、语料采集模块,用于利用爬虫技术爬取网络语料数据,从而构建网络语料库;
40、翻译分析模块,用于结合网络语料库对初始译文中的每个词单元在语句结构上的关系进行语义分析,得到初始译文中每个词单元的句结构参数,并通过词单元在网络语料库中的同义词和近义词在所属语句中进行替换,分析替换前后的语义变化特征,得到初始译文中每个词单元的语义特征值,将初始译文中任意词单元的句结构参数与语义特征值结合,得到词单元的翻译度;
41、反馈翻译模块,用于结合词单元的翻译度对nmt模型进行反馈,构建反馈函数并迭代地对待翻译句段进行翻译,得到最终译文。
42、本发明的技术方案的有益效果是:在构建了初始nmt模型以及网络语料库后,通过对初始译文中词单元与网络语料库中的同义词和近义词在句法结构与同义词替换方面进行语义对比分析后,进一步量化生成翻译度指标,有效识别初始译文中的翻译模糊点,通过迭代优化机制将翻译度参数融入nmt模型权重调整,实现翻译质量的渐进式提升,该方法通过结合大数据技术能够显著提高翻译质量,从而优化译文的语义表达,提升翻译的准确性和语境适应性。
- 还没有人留言评论。精彩留言会获得点赞!