一种基于文本描述的行人检索任务数据集构建方法
本发明涉及数据生成,尤其是指一种基于文本描述的行人检索任务数据集构建方法。
背景技术:
1、基于文本描述的行人检索(text based person retrieval,简称tbpr)任务,指的是从摄像头下大量的行人图像中找出与给定文本描述相匹配的特定行人的图像的检索任务。
2、目前这个任务的主流的数据集主要有3个,分别为cuhk-pedes,icfg-pedes,rstpreid;这些数据集分别由不同数量的图像-文本对构成。为了提高tbpr任务模型的性能,现有技术希望通过构建新的数据集,提供训练数据来提升其提高模型性能。在构建数据集的时候,如果选择采用现实摄像头采样,会引发人们对个人隐私的持续担忧,以及采集到的图像进行人工注释需要高额的人力成本;所以现有技术利用生成式模型进行数据集的构建。
3、现有的数据生成方法大都是基于原始数据集的。例如:基于原始数据集的图像和文本注释,修改文本注释中的特定词元,如将“white shirt”修改为“blue shirt”,再使用微调后的扩散模型针对修改后的词元,在原有图像的基础上生成新的图像。基于原始数据集的图像和文本注释,针对文本注释中人物的特定属性,如“hair”,“skirt”,使用图像分割模型在对应的原图中进行检测,分割出对应属性的掩码;再使用可用的服装和配饰图像针对分割的属性,在原图上进行编辑;最终得到新的图像,其对应的新的文本注释利用大语言模型根据图像编辑采用的“服装和配饰图像”的服饰名称进行更改;比如当referenceattribute image部分对应的用来做替换的服饰的单词是gold hair、white skirt、sandals时,那么大语言模型将会用来匹配这三个词是替换原图注释中的哪些部分,并进行替换得到新的图像。直接使用原始数据集的文本注释来指导扩散模型生成新的图像,然后使用跨模态blip模型对生成的图像生成文本注释,并通过额外的属性注释提高文本注释丰富度;即提出很多属性种类,让blip模型再针对这些属性匹配生成的图像是否含有这些属性,若有,则添加到生成的文本注释中,以提高注释丰富度。
4、综上所述,现有技术仅仅是在原有数据的邻近空间进行有限的修改,来获取新的数据,由于数据集是有限的,会导致生成的图像缺乏足够的多样性,局限于某些固定的特征。而当原始数据集的图像分辨率较低时,现有技术直接对原始数据集的图像做编辑,编辑后得到的图像分辨率自然也低,因此导致生成的数据效果较差。并且现有技术严重依赖于原有数据集的数据,可能会导致隐私风险和合规性问题,且如果缺少大规模的数据集,现有技术将无法实现构建出新的数据集,进而导致在完成行人检索任务时,利用构建的数据集对tbpr任务模型进行训练后,无法得到满足检索精度要求的tbpr任务模型,模型性能差,导致行人检索任务完成度低。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术在构建新的数据集时极度依赖原有数据集,导致新的数据集图像多样性低、分辨率差,进而导致训练出的行人检索模型的检索精度低的问题。
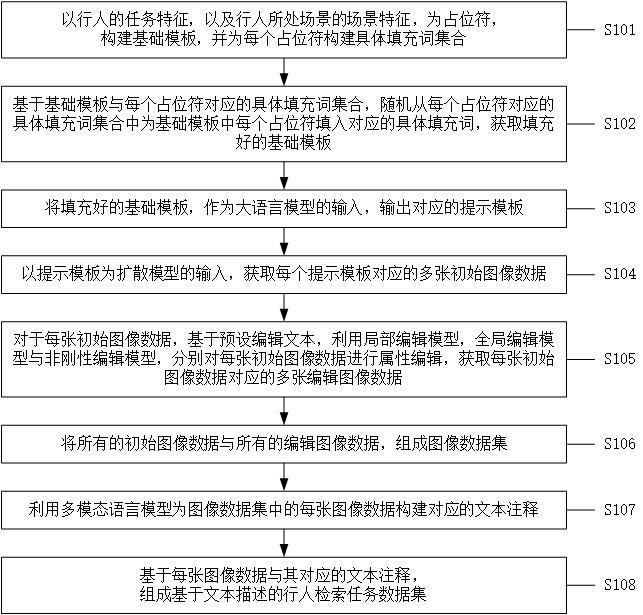
2、为解决上述技术问题,本发明提供了一种基于文本描述的行人检索任务数据集构建方法,包括:
3、以行人的人物特征,以及行人所处场景的场景特征,为占位符,构建基础模板,并为每个占位符构建具体填充词集合;
4、基于基础模板与每个占位符对应的具体填充词集合,随机从每个占位符对应的具体填充词集合中为基础模板中每个占位符填入对应的具体填充词,获取填充好的基础模板;
5、将填充好的基础模板,作为大语言模型的输入,输出对应的提示模板;
6、以提示模板为扩散模型的输入,获取每个提示模板对应的多张初始图像数据;
7、对于每张初始图像数据,基于预设编辑文本,利用局部编辑模型,全局编辑模型与非刚性编辑模型,分别对每张初始图像数据进行属性编辑,获取每张初始图像数据对应的多张编辑图像数据;
8、将所有的初始图像数据与所有的编辑图像数据,组成图像数据集;
9、利用多模态语言模型为图像数据集中的每张图像数据构建对应的文本注释;
10、基于每张图像数据与其对应的文本注释,组成基于文本描述的行人检索任务数据集。
11、优选地,所述行人的人物特征包括行人的性别、年龄、外貌特征与服饰特征;所述行人所处场景的场景特征包括行人的动作、地理环境、建筑设施与天气状况。
12、优选地,所述以提示模板为扩散模型的输入,获取每个提示模板对应的多张图像数据,包括:
13、对于每个提示模板,将其作为扩散模型的输入,通过调整扩散模型的生成引导系数与随机种子,获取每个提示模板对应的多张图像数据。
14、优选地,将所有的初始图像数据与所有的编辑图像数据,组成图像数据集后,还包括:
15、对图像数据集中的每张图像数据进行人体姿势识别,识别出每张图像数据中行人的鼻子、左眼、右眼、左耳、右耳、左肩、右肩、左胳膊肘、右胳膊肘、左手腕、右手腕、左臀、右臀、左膝、右膝、左脚踝与右脚踝,作为人体关键点;
16、对人体关键点进行区域划分,将鼻子、左眼、右眼、左耳与右耳划分为头部区域,将左肩、右肩、左胳膊肘、右胳膊肘、左手腕、右手腕、左臀与右臀划分为身体区域,将左膝、右膝、左脚踝与右脚踝划分为腿部区域;
17、对于图像数据集中的每张图像数据,若该图像数据中存在相同的人体关键点,则判定该图像数据中并非只有单一行人,则删除该图像数据;
18、对于图像数据集中的每张图像数据,若该图像数据中头部区域、身体区域与腿部区域不同时存在,则判定该图像数据中不存在完整行人,则删除该图像数据;
19、获取删除图像后的图像数据集,作为更新后的图像数据集。
20、优选地,基于大语言模型为每个占位符构建具体填充词集合,包括:
21、将行人的人物特征输入大语言模型,并向大语言模型发出指令,令大语言模型输出多个具体填充词,生成行人的人物特征对应的具体填充词集合;
22、将行人所处场景的场景特征输入大语言模型,并向大语言模型发出指令,令大语言模型输出多个具体填充词,生成行人所处场景的场景特征对应的具体填充词集合。
23、优选地,将填充好的基础模板,作为qwen2模型的输入,输出对应的提示模板,包括:
24、将填充好的基础模板输入qwen2模型的分词器中,转换为输入索引;
25、将输入索引输入到qwen2模型的主干网络中,转化为文本向量;
26、将文本向量输入qwen2模型的解码器层中,令文本向量依次经过均方层归一化、注意力机制后,与输入的文本向量进行残差连接后,得到第一隐藏态;令第一隐藏态经过均方层归一化,送入多层感知器中;将多层感知器的输出与所述第一隐藏态进行残差连接后,输出解码特征;
27、将解码特征输入输出层中,进行线性变换,获取对应的提示模板。
28、优选地,利用局部编辑模型,对初始图像数据进行局部编辑,包括:
29、基于注意力机制,获取初始图像数据的交叉注意力图;
30、将初始图像数据输入局部编辑模型中进行去噪,比较当前去噪次数与预设常数:
31、若,则获取预设编辑文本的交叉注意力图,作为目标交叉注意力图;
32、若,则获取初始图像数据对应的交叉注意力图与预设编辑文本的目标交叉注意力图融合后的交叉注意力图,作为目标交叉注意力图;
33、直至达到预设去噪次数,利用目标交叉注意力图对初始图像数据进行去噪,获取初始图像数据对应的局部编辑图像数据。
34、优选地,利用全局编辑模型,对初始图像数据进行全局编辑,包括:
35、基于注意力机制,获取初始图像数据的交叉注意力图;
36、将初始图像数据输入全局编辑模型中进行去噪;
37、比较预设编辑文本与初始图像数据对应的文本相同位置处的词元是否相同:
38、若相同,则不改变交叉注意力图中对应位置处的值;
39、若不同,则改变交叉注意力图中对应位置处的值;
40、直至所有词元均比较结束,获取当前交叉注意力图,作为目标交叉注意力图,对初始图像数据进行去噪,获取初始图像数据对应的全局编辑图像数据。
41、优选地,利用非刚性编辑模型,对初始图像数据进行非刚性编辑,包括:
42、将初始图像数据输入非刚性编辑模型中进行去噪,比较当前去噪次数与预设常数:
43、若,则计算注意力;
44、若,则计算注意力;
45、直至达到预设去噪次数,获取当前注意力,对初始图像数据进行编辑,获取初始图像数据对应的非刚性编辑图像数据;
46、其中,;表示第次去噪,表示预设常数;表示初始图像数据的映射向量表示,表示初始图像数据对应的文本的映射向量表示,表示的向量长度;表示局部编辑后的图像数据的映射向量表示,表示预设编辑文本的映射向量表示。
47、优选地,利用多模态语言模型为图像数据集中的每张图像数据构建对应的文本注释,包括:基于固定型指令构建文本注释与基于变化型指令构建文本注释;
48、所述基于固定型指令构建文本注释为:利用多模态语言模型读取图像数据,并基于预设注释指令为固定输出模板填充对应的属性,生成文本注释;
49、所述基于变化型指令构建文本注释为:利用多模态语言模型读取图像数据,并直接基于固定输出模版,生成文本注释。
50、本发明的上述技术方案相比现有技术具有以下有益效果:
51、本发明所述的基于文本描述的行人检索任务数据集构建方法,不需要基于原始数据进行衍生,而是直接以行人的人物特征,以及行人所处场景的场景特征为占位符,构建基础模板,并对基础模板进行填充后,生成对应的提示词;利用扩散模型,基于提示词,生成图像数据,完全不依赖原始数据,大大降低了隐私风险和规避了合格性问题;且扩散模型通过逐步去噪,能够更稳定地生成高质量图像,提高了生成的图像的分辨率。同时本发明利用局部编辑模型、全局编辑模型与非刚性编辑模型,直接基于生成的初始图像数据,有选择地对图像数据中对应属性的特征进行编辑,获取编辑图像数据,使得图像生成的泛化性好、自由度高,大大提高了生成的图像数据的多样性,能够更全面的训练行人检索模型,提高模型识别精度。
52、本发明利用人体姿势识别,对每张数据图像中的人体关键点进行识别,并基于识别出的关键点,将识别效果差、不符合任务要求的图像删除,筛除低质量图片,提高了图像数据集中图像的质量,进而提高了行人检索任务数据集中的数据质量。
- 还没有人留言评论。精彩留言会获得点赞!