一种基于货车GPS轨迹数据和高速交易数据的货车载货状态估计方法与流程
本发明隶属于交通大数据和智能交通领域,一种基于货车gps轨迹数据和高速交易数据的货车载货状态估计方法。
背景技术:
由于货车的gps轨迹数据仅仅记录了货车的经纬度信息,时间信息、行驶速度、方向,并没有明确的标识货车的一次行程是否载货。目前物流行业信息化程度低,存在货找不到车、车找不到的货的现象比较严重。货车空跑现象也比较严重。但是尚没有对货车空跑进行有效的监管方法。也就不能很好的估计货车空跑情况、分析货车订单饱满程度,最后进行合理的货车调度。
liao(2009)利用美国i-94/i-90走廊一年的卡成gps数据进行了案例研究,并给出了如货车速度、容量、停车行为等统计性的画像。但是他们针对的是双子城到芝加哥的路径,而不是全国性的出行模式。北航ma等人在2011发表的文中基于货车的gps数据,开发了一个在线货车运营性能评估系统,在解决信号丢失、信号抖动和异常行程问题的基础上修正了od识别算法。对于信号丢失问题,在文中选择了5mph的速度阈值限制。如果对货车计算的平均速度低于该阈值,则确定信号丢失的旅程已经结束。为了解决gps信号不准确,连续的gps点之间的距离被用来改进o-d算法,如果连续两个gps点的经纬度差值小于0.000051度(约65英尺或20米),则标记为可能的目的地点。当计算这次旅行的平均速度时,减去由波动引起的延迟时间以获得更精确的结果。对于特别短的旅程以及异常高的速度、或者旅行时间为0等情况的作为异常进行处理。
arunkuppam在2013年发表的一篇文章中利用货车gps数据开发一个基于出行的货车需求模型。该模型包括出行生成模型(评估货车目的所在区域生成的出行次数)、停车次数模型(预测一次出行停车的次数)、出行完成模型(预测一次出行是返回到起点还是在别的地方结束)、停车目的模型(预测每次停车的目的,文中分为了retail、construction、farming、households、government、warehousing、transportation、industrial/manufactruing、service(orother))、停车位置选择模型(预测每次出行每个停靠站的位置)、停车时间选择模型(预测每次停车的时间间隔)。以上提到模型主要基于多项式逻辑模型判断每个变量的系数,并确定影响模型的主要因素。例如在停车目的模型中发现出行开始的土地用途影响了随后出行停靠的目的,此外先前的停止目的是关键性变量。但是本文仅仅是基于已给定出行条件、变量的情况下,对各种变量使用逻辑模型进行简单的系数评估,不具有广泛的适用性。
junhuang等人在2014年研究了来自第三方公司的14654辆货车的gps轨迹数据集。从gps轨迹中提取了货车的出行,并使用lcss聚类方法,把出行聚类到路径中去。发现货车如果需要周末也工作,遇到春节这样的长假会休息半个月。货车的出行模式随着货运出发地到目的地的不同而不同。给定两个城市,货运货车一般有相对固定路径完成他们的订单。
目前对货车出行方面的分析研究较少,而且使用的数据也是仅仅基于货车gps轨迹数据,货车的出行数据没有被充分利用。
技术实现要素:
本发明的技术解决问题:克服现有技术的不足,充分利用货车出行留下的轨迹数据和高速交易数据,提供了一种基于货车gps轨迹数据和高速交易数据的货车载货状态估计方法。填补了目前尚没有对货车gps轨迹出行载货状态估计方法的空白。基于估计的货车载货状态能够分析货车的历史出行空载率,有效的评估货车利用状态以及货车的订单饱满程度。
本发明的技术解决方案:
一种基于货车gps轨迹数据和高速交易数据的货车载货状态估计方法,通过以下步骤实现:
(1)基于gps数据中记录的经纬度、时间戳和速度信息,与高速交易数据中记录的进出收费站时间、收费站时间、载重信息,进行gps轨迹数据和高速交易数据的匹配,并标记货车的一次行程是否经过高速,及经过高速的本次行程是否载货;
(2)去除货车最开始行程和最后一次行程,对每次行程提取出行特征,所述行程的出行特征包括本次行程、相邻的上一次行程、相邻的下一次行程的开始时间、结束时间、行程开始地点、结束地点、行程的od距离、行程累积出行里程、行程非高速下的出行速度、行程的时长;
(3)对(2)中提取的行程开始时间、结束时间:由于货车的开始、结束时间范围较大,根据货车历史行程,根据开始时间和结束时间分布,将一天划分为4个时间段,用1、2、3、4标识,然后根据行程开始时间和结束时间所属的时间段,标识时间特征;
(4)对(2)中提取的行程开始地点、结束地点进行预处;将货车历史行程的开始地点、结束地点的经纬度信息基于dbscan进行聚类,并基于轮廓系数法选择最优聚类个数,若聚为k个类别,考虑到聚类后的存在异常点,则一共有k+1个类别;然后标记行程开始地点和结束地点所属的类别,由于货车行程的开始、结束地点为标称型属性,不具备序列性,需基于one-hot编码处理,处理后的行程开始、结束地点分别作为k+1个特征;
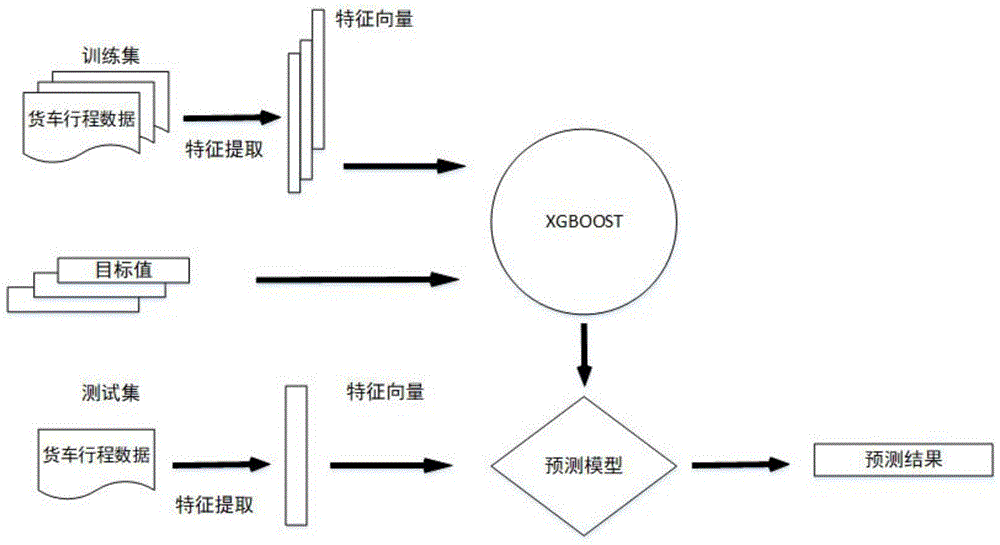
(5)基于步骤(3)的行程开始时间、结束时间,步骤(4)的行程开始地点、结束地点,步骤(2)提取的行程od距离、行程累积出行里程、行程非高速下的出行速度、行程的时长,对能确定货车载货与否的特征,作为训练集,基于xgboost方法,训练预测模型;
(6)将不能确定货车载货状态的行程所对应出行特征作为测试集,输入步骤(5)训练的预测模型,对本次行程载货与否进行预测,得到行程的载货状态。
所述步骤(1)中,gps轨迹数据是指:货车上安装的定位装置所采集的货车当前所在的时间戳、经度、纬度、货车当前的行驶速度、行驶方向。
所述步骤(1)中,高速交易数是货车进出高速收费站,收费站设备或者工作人员所采集的收费站信息、时间戳、货车型号以及货车载重。
所述步骤(1)中,gps轨迹数据和高速交易数据匹配:当gps记录的经纬度信息距离收费站经纬度500米以内,时间与高速交易数据中记录的时间差异在3分钟以内,且货车当前处于低速行驶状态,即小于5m/s时,则认为进行了一次匹配。若遍历完本次行程的所有轨迹点,根据和高速交易数据是否进行了匹配,以及高速交易数据中记录的货车载货信息,标记货车的本次行程是否经过高速、是否载货。
所述步骤(3)中,将一天划分为4个时段,是依据所有货车的行程开始时间和结束时间将一天的24小时划分为01:00~03:59,04:00~12:59,13:00~19:59,20:00~00:59共4个时间段,根据行程开始时间和结束时间所属的时间段分别标记为1,2,3,4。
所述步骤(2)中行程的od距离是指货车行程开始地点(origin)和行程结束地点(destination)之间的直线距离。
所述步骤(2)中行程非高速下的出行速度,是指货车在具有高速出行的情况下,货车在高速和非高速下出行环境的不同,高速出行部分的行程将不考虑在速度的计算范围内,仅计算货车非高速行程下的速度。
所述步骤(2)中行程累积出行里程是指依次累加行程中的相邻两个gps轨迹点之间的距离,得到最后行程累积出行里程。
本发明与现有技术相比的优点在于:
(1)目前对货车的出行分析较少,主要集中在货车的出行系数如速度、里程、时长、以及简单的出行模式分析,仅仅时对货车行为进行简单的监控;本发明从货车载货状态出发,估计货车历史行程的载货状态,可以基于此实现对车辆长期的空载率、订单饱满程度监控。
(2)目前的分析主要基于货车的gps轨迹数据,没有用到货车的高速出行数据,没有用到货车的高速出行数据;本文除了利用货车的gps轨迹数据外,还考虑了货车的高速出行数据,充分利用了货车出行留下的数据,基于高速出行中载货信息和实现货车的载货状态估计。
(3)本发明第一次基于货车的轨迹数据和高速交易数据,在提取货车行程的特征时,提取了本次行程、相邻的上一次行程和相邻的下一次行程的特征。考虑货车行程时间和空间上的关联性,能更好,更加准确的预测车辆的载货状态。
(4)使用xgboost机器学习方法来训练模型,进行货车载货状态估计,xgboost在各种大数据挖掘比赛中都取得比其他机器学习方法较好的效果,且支持并行和分布式计算,对数据量较大的情况式较优的。目前货车空跑现象比较严峻,但是尚没有对货车空跑进行有效的监管方法。也就不能很好的估计货车空跑情况、分析货车订单饱满程度,最后进行合理的货车调度,进行货车的载货状态估计时很有必要的。
附图说明
图1为对货车的行程进行特征提取后,基于xgboost机器学习方法,训练模型,然后实现对货车载货状态进行估计;
图2为基于货车gps轨迹数据和高速交易数据匹配的流程图。
具体实施方式
下面结合附图及实施例对本发明进行详细说明。
如图1、2所示,一种基于货车gps轨迹数据和交易数据的货车载货状态估计方法,具体步骤如下:
(1)进行货车gps轨迹数据和高速交易数据的匹配
本发明首先遍历货车行程中的轨迹数据与收费站经纬度信息。找到与收费站经纬度匹配的轨迹点,范围在500米以内,然后基于货车的高速交易数据进行经纬度,时间匹配,若时间在3分钟以内,且货车当前处于低速行驶状态(小于5m/s),则认为有一次高速出行,若货车本次行程中轨迹点都已经遍历完了,则根据匹配结果标记行程,遍历下一条行程。
(2)根据步骤(1)匹配的结果,考虑货车的行程时序上的关联性,且与时间和空间特征相关联,计算行程的出行特征,括本次行程、相邻的上一次行程、相邻的下一次行程的开始时间、结束时间、行程开始地点、结束地点、行程的od距离、行程累积出行里程、行程非高速下的出行速度、行程的时长。
a.计算行程开始与结束时间所的时间段,根据是否属于01:00~03:59,04:00~12:59,13:00~19:59,20:00~00:59标记为1、2、3、4。
b.计算行程开始位置与结束位置,首先对货车所有行程的开始位置和结束位置的经纬度,基于dbscan聚类,并基于轮廓系数法,选择最优聚类个数,例如k个,考虑无法聚类的异常点的情况,将行程开始与结束地点划分为k+1类,根据行程开始、结束地点所属的类别,并进行one-hot编码后,行程开始地点和结束地点分别表示为k+1个特征。
c.计算货车od距离,是根据货车行程开始经纬度、结束经纬度,计算od距离,其公式计算如下:
a=pd.lat-po.lat(1)
b=pd.lon-po.lon(2)
o(origin)表示行程开始地,d(destination)行程结束地,lat(latitude)表示纬度,lon(lontitude)表示经度,dis(distance)表示距离,其中po代表行程开始的轨迹点,pd代表行程结束的轨迹点。po.lat表示行程开始的轨迹点中记录的纬度,po.lon表示行程开始的轨迹点中记录的经度。pd.lat表示行程结束的轨迹点中记录的纬度,pd.lon表示行程结束的轨迹点中记录的经度。
d.计算行程的累出行里程,是根据行程的所有gps轨迹点进行累加计算,其计算公式如下:
其中n表示本次行程共采集了n个gps轨迹点。pi表示行程中的第i个轨迹点。
e.行程非高速上的出行速度,是指对于能匹配上高速出行的行程,则剔除高速出行部分的轨迹点,将非高速出行部分的轨迹点中采集的速度进行累加,求平均,得到最后的非高速出行下的速度avespeed。
其中m表示该行程中共有m个gps轨迹点没有经过高速,pi.speed表示当前轨迹点中记录的货车行驶速度。
f.行程时长,是指将基于行程结束的轨迹点中记录的时间减去行程开始的轨迹点的时间,作为本次行程的出行时长time。
time=pd.time-po.time(6)
其中pd.time表示行程开始时间,po.time表示行程结束时间。
(3)根据步骤(2)计算的货车出行特征,对于具有高速出行,且能确定其载货状态的行程出行特作为训练样本,基于xgboost方法,设置模型参数,并基于五折交叉验证,进行训练,并得到最后的预测模型。其中xgboost中的参数,eta(学习步长)为0.02,min_child_weight(孩子节点中最小的样本权重和)为40,colsample_bytree(在建立树时对特征采样的比例)为0.9497036,subsample(用于训练模型的子样本占整个样本集合的比例)为0.8715623,max_depth(树的最大深度)为8,lambda(l2正则惩罚系数)为0.0735294,其余参数为默认值。
xgboost的优化目标函数为:
其中,t表示第t轮,n表示有n个样本,i是损失函数,yi是真实的目标值,
(4)将步骤(2)中计算的不能确定货车载货状态的出行特征,作为测试集,输入到步骤(3)所训练的预测模型中,得到本次行程是否载货的预测结果。
以下以重庆市内的货车gps轨迹数据和高速交易数据为例,如图1、2所示为例进一步说明本发明的实现步骤:
1、gps轨迹数据和高速交易数据匹配
遍历货车行程中的经纬度点,例如对货车行程的中的轨迹点(2018-05-1807:48:59,30.662835269404663,107.77092608191113,0,260),分别为时间、纬度、经度、速度、方向,判断是该轨迹点中记录的经度、纬度是否和高速收费站经纬度匹配,若该经纬度点在高速收费站经纬度点500米以内,则进行货车高速交易数据匹配和gps轨迹数据匹配,判断轨迹点中记录的经纬度与高速收费站中记录进出行收费站的经纬度、时间是否匹配,以及货车当前是否处于低速行驶状态。如该轨迹点位行程的最后一个轨迹地,则结束遍历。
2、基于1中匹配结果,对每个行程增加标记位:是否经过高速、是否载货。若该行程经过高速则标记为1,没有经过高速则标记为0,若本次行程载货标记为1,不载货则标记为0。
3、对于2中标记的行程,除去货车最开始行程,和最后一次行程,提取货车相邻上一次行程、本次行程、相邻的下一次行程的开始时间点、结束时间点、开始地点和结束地点、od距离、累积出行里程、行程非高速下的出行速度、行程出行时长。例如行程的轨迹点记录的po为:
(2018-05-2112:04:54,30.718857934085086,107.81312686643948,10,350),结束的轨迹点pd为:
(2018-05-2419:21:01,29.80354200139796,107.07016634877027,0,14)则依据发明内容里面划分的时间段将本次的行程开始时间标记为2,结束时间标记为3,然后根据货车所有行程的开始地点和结束地点聚类的结果,若聚类为k个类别,根据本次行程的开始地点和结束地点所属的类别进行onehot标记,表示成k+1个特征。然后根据公式(1)、(2)、(3)计算od距离,对行程的所有轨迹点基于公式(4)计算累积里程,根据公式(5)计算货车的非高速下的出行速度,根据公式(6)计算行程时长。
4、对3中提取的所有特征,将是否经过高速标记位为1的行程,将其出行特征作为训练集,载货标记中0,1作为目标值,使用xgboost,基于五折交叉验证,训练预测模型。
5、对2中是否经过高速标记位0的行程,将其在3中提取的特征输入步骤4得到的预测模型,得到最后的预测结果。
- 还没有人留言评论。精彩留言会获得点赞!