一种基于全景相机的门禁识别方法、系统及智能设备与流程
1.本发明涉及图像处理技术领域,特别涉及一种基于全景相机的门禁识别方法、系统及智能设备。
背景技术:
2.传统车辆门禁系统多为伸缩门和车牌识别的结合,同时辅助有补光灯、红外收发装置,在无人值守的场景下,该种伸缩门仅能识别车牌,对于门禁处的环境感知水平较弱,如何防止车辆尾随,车牌遮挡抓拍、现场人员聚集、异常翻越等情况,则需要过多的智能系统进行搭配,单一的视频监控捕捉存在视野盲区,多监控视角安装相对耗时耗力。有鉴于此,本技术的发明人经过深入研究,得到一种基于全景相机的门禁识别方法、系统及智能设备。
技术实现要素:
3.本发明的目的是提供基于全景相机的门禁识别方法、系统及智能设备,其具有较好的环境感知水平。
4.本发明的上述技术目的是通过以下技术方案得以实现的:
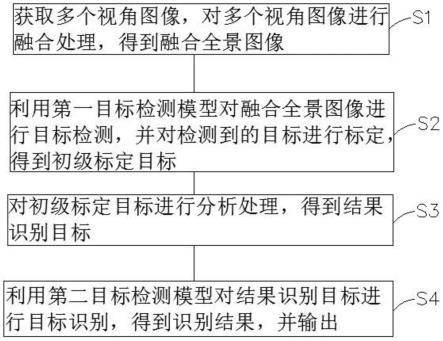
5.一种基于全景相机的门禁识别方法,包括如下步骤,
6.获取多个视角图像,对多个视角图像进行融合处理,得到融合全景图像;
7.利用第一目标检测模型对融合全景图像进行目标检测,并对检测到的目标进行标定,得到初级标定目标;
8.对初级标定目标进行分析处理,得到结果识别目标;
9.利用第二目标检测模型对结果识别目标进行目标识别,得到识别结果,并输出。
10.在一个优选实施例中,所述第一目标检测模型包括行人目标检测模型和车辆目标检测模型,所述初级标定目标包括行人标定目标和车辆标定目标,所述对初级标定目标进行分析处理包括对车辆标定目标进行分析处理和对行人标定目标进行分析处理,所述第二目标检测模型包括对应于所述对车辆标定目标进行分析处理的车牌识别模型、车身识别模型、主副驾驶人员人脸识别模型和车辆识别模型,以及对应于所述对行人标定目标进行分析处理的人脸识别模型、行人正常识别模型、行人翻越识别模型、行人摔倒识别模型、行人车辆尾随模型。
11.在一个优选实施例中,所述对车辆标定目标进行分析处理包括如下步骤:
12.识别车辆姿态,得到车辆姿态识别结果,输出为所述结果识别目标,所述车身姿态包括前车身、右前车身、左前车身、左侧面、右侧面、尾箱侧面和尾箱正面;
13.对车辆识别姿态为前车身的车辆标定目标提取车牌和主副驾人脸信息,输出为所述结果输出目标。
14.在一个优选实施例中,所述对行人目标进行分析处理包括按照目标大小设定行人目标区域,对行人目标区域进行放大处理,输出为所述结果识别目标。
15.在一个优选实施例中,对行人目标区域进行人脸标定,输出为结果识别目标。
16.在一个优选实施例中,所述行人标定目标数量超过聚集预设值时,输出行人聚集识别结果。
17.在一个优选实施例中,还包括步骤:
18.对行人标定目标进行跟踪,并判断其一定时间内的尺寸变化量,当一定时间内尺寸变化量超过预设值时,设置为疑似聚集目标;
19.对疑似聚集目标进行景深调节,并利用行人轮廓检测模型对不同景深下的疑似聚集目标进行目标识别,将不同景深下的识别目标数量进行统计求和,求和数量大于预设值时,输出行人聚集识别结果。
20.在一个优选实施例中,当所述初级标定目标的大小小于目标预设值时,排除该初级标定目标。
21.一种门禁识别系统,包括:
22.图像获取单元,用于获取多个视角图像,对多个视角图像进行融合处理,得到融合全景图像;
23.初级目标标定单元,用于利用第一目标检测模型对融合全景图像进行目标检测,并对检测到的目标进行标定,得到初级标定目标;
24.分析处理单元,用于对初级标定目标进行分析处理,得到结果识别目标;
25.目标识别单元:利用第二目标检测模型对结果识别目标进行目标识别,得到识别结果,并输出。
26.一种门禁识别智能设备,包括机体、四个摄像头、四个补光灯、处理器和存储器,所述机体具有连接成环形的四个侧面,所述四个摄像头分别设于所述四个侧面上,所述四个补光灯对应所述四个摄像头设置,所述处理器和所述存储器设于所述机体中,其中,所述存储有所述处理器的可执行指令,所述处理器配置为经由执行所述可执行指令来执行上述基于全景相机的门禁识别方法的步骤。
27.与现有技术相比,本发明的一种基于全景相机的门禁识别方法,其通过将多个视角的图像融合处理后得到融合全景图像,实现全向的环境感知,通过对融合全景图像的分级目标检测,实现对多种目标和多种状态的识别,具有极好的环境感知水平;本发明的一种门禁识别智能设备将所有的感应装置都是集成于一台智能设备上,其位置在出厂时即可实现标定,无需再在应用现场进行调试,并且所有的执行过程都在一个处理器当中完成,其结构相对较为简洁,有助于降低图像处理难度。
附图说明
28.图1是本发明涉及一种基于全景相机的门禁识别方法的流程图。
29.图2是本发明涉及一种基于全景相机的门禁识别方法的标定方式示意图。
30.图3是本发明涉及一种门禁识别智能设备的主视图。
31.图4是本发明涉及一种门禁识别智能设备的俯视图。
32.图中
33.标定框1;机体2;摄像头3;补光灯4;处理器5。
具体实施方式
34.以下结合附图对本发明作进一步详细说明。
35.本具体实施例仅仅是对本发明的解释,其并不是对本发明的限制,本领域技术人员在阅读完本说明书后可以根据需要对本实施例做出没有创造性贡献的修改,但只要在本发明的权利要求范围内都受到专利法的保护。
36.实施例一:
37.如图1所示,一种基于全景相机的门禁识别方法,包括如下步骤,
38.s1、获取多个视角图像,对多个视角图像进行融合处理,得到融合全景图像,融合处理的步骤包括:相机标定、多路视频的同步采集、传感器图像畸变校正、图像投影变换、特征点提取与匹配、全景图像拼接融合(消除拼接缝等)以及及亮度与颜色的均衡处理;
39.s2、利用第一目标检测模型对融合全景图像进行目标检测,并对检测到的目标进行标定,标定的方式可以采用标定框1的形式,将目标进行框选,得到初级标定目标,所述第一目标检测模型包括行人目标检测模型和车辆目标检测模型,所述初级标定目标包括行人标定目标和车辆标定目标;
40.s3、对初级标定目标进行分析处理,得到结果识别目标,包括对车辆标定目标进行分析处理和对行人标定目标进行分析处理;
41.s4、利用第二目标检测模型对结果识别目标进行目标识别,得到识别结果,并输出。
42.所述第二目标检测模型包括对应于所述对车辆标定目标进行分析处理的车牌识别模型、车身识别模型、主副驾驶人员人脸识别模型和车辆识别模型,以及对应于所述对行人标定目标进行分析处理的人脸识别模型、行人正常识别模型、行人翻越识别模型、行人摔倒识别模型、行人车辆尾随模型。从而实现车牌识别、车身识别、主副驾驶人员人脸识别、车辆识别、人脸识别、行人正常识别、行人翻越识别、行人摔倒识别行人车辆尾随识别。
43.进一步,所述对车辆标定目标进行分析处理包括如下步骤:
44.识别车辆姿态,得到车辆姿态识别结果,输出为所述结果识别目标,所述车身姿态包括前车身、右前车身、左前车身、左侧面、右侧面、尾箱侧面和尾箱正面;
45.对车辆识别姿态为前车身的车辆标定目标提取车牌和主副驾人脸信息,输出为所述结果输出目标,即可实现车牌和主副驾人脸信息的识别。
46.本实施例的一种基于全景相机的门禁识别方法,其通过将多个视角的图像融合处理后得到融合全景图像,实现全向的环境感知,通过对融合全景图像的分级目标检测,实现对多种目标和多种状态的识别,具有极好的环境感知水平。
47.进一步,如图2所示,所述对行人目标进行分析处理包括按照目标大小设定行人目标区域,行人目标区域即标定框1框定的区域,对行人目标区域进行放大处理,即将标定框1的尺寸扩大,使得识别区域放大,有助于进行后续的目标识别,输出为所述结果识别目标。进一步,对行人目标区域进行人脸标定,输出为结果识别目标,用于实现人脸识别。
48.进一步,所述行人标定目标数量超过聚集预设值时,输出行人聚集识别结果,从而可以判断是否发生人员聚集的情况。
49.本实施例的一种基于全景相机的门禁识别方法还包括步骤:
50.对行人标定目标进行跟踪,并判断其一定时间内的尺寸变化量,此处时间设置为
2s,尺寸变化量为计算行人标定目标的标定框1的宽度变化量,当一定时间内尺寸变化量超过预设值时,即当2s内的标定框1的宽度变化量超过预设值时,设置为疑似聚集目标,此处的预设值设置为0.3m-0.5m;
51.对疑似聚集目标进行景深调节,并利用行人轮廓检测模型对不同景深下的疑似聚集目标进行目标识别,将不同景深下的识别目标数量进行统计求和,求和数量大于预设值时,输出行人聚集识别结果,表示发生人员聚集。
52.以上过程主要是为了实现当行人穿着衣服颜色相近,且成团聚集在一起时造成直接识别困难时,通过判断目标的宽度变化,即检测成团聚集的人的间距变化来实现对是否为成团聚集的判断,当成团聚集时,通过景深调节,识别不同景深下的人员数量,从而实现成团聚集的行人数量的大致统计,实现人员聚集相对较为精准的识别。
53.进一步,当所述初级标定目标的大小小于目标预设值时,排除该初级标定目标,即目标的尺寸较小,表示其距离较远,而不针对其进行识别,只针对于距离较近的目标进行识别。
54.实施例二:
55.一种门禁识别系统,包括:
56.图像获取单元,用于获取多个视角图像,对多个视角图像进行融合处理,得到融合全景图像;
57.初级目标标定单元,用于利用第一目标检测模型对融合全景图像进行目标检测,并对检测到的目标进行标定,得到初级标定目标;
58.分析处理单元,用于对初级标定目标进行分析处理,得到结果识别目标;
59.目标识别单元:利用第二目标检测模型对结果识别目标进行目标识别,得到识别结果,并输出。
60.实施例三
61.一种门禁识别智能设备,如图3和图4所示,包括机体2、四个摄像头3、四个补光灯4、处理器5和存储器,所述机体2具有连接成环形的四个侧面,所述四个摄像头3分别设于所述四个侧面上,所述四个补光灯4对应所述四个摄像头3设置,所述处理器5和所述存储器设于所述机体2中,其中,所述存储有所述处理器5的可执行指令,所述处理器5配置为经由执行所述可执行指令来执行上述基于全景相机的门禁识别方法的步骤。
62.以上结构设置中4个摄像头3用于获取不同角度的视角图像,每个摄像头3的视野要大于90度,补光灯4用于对摄像头3进行补光,本智能设备将所有的感应装置都是集成于一台智能设备上,其位置在出厂时即可实现标定,无需再在应用现场进行调试,并且所有的执行过程都在一个处理器5当中完成,其结构相对较为简洁,有助于降低图像处理难度。
63.需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括
……”
或“包含
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的要素。此
外,在本文中,“大于”、“小于”、“超过”等理解为不包括本数;“以上”、“以下”、“以内”等理解为包括本数。
64.上述对实施例的描述是为便于本技术领域的普通技术人员理解和使用本发明,熟悉本领域技术的人员显然可以容易地对实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,不脱离本发明范畴所做出的改进和修改都应该在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1