基于深度强化学习的核电巡检方法、装置、设备及介质
本发明属于无人机巡航,尤其涉及一种基于深度强化学习的核电巡检方法、装置、设备及介质。
背景技术:
1、能源是人类生存和发展的关键物质基础,同时也是国际政治、经济、军事和外交关注的核心焦点。核能的发展给国家人民带来大量清洁能源的同时,也带来了核安全事故的潜在威胁。周期性的核电站安全壳巡检是保障核安全的重要安全措施。然而,常规的表面检测方法使用人工作业,成本高且耗时长。近年来随着无人机技术的发展,无人机(unmannedaerial vehicle,uav)的应用可以提高检测效率、节省时间和成本,但由于核电站场景存在全球定位系统(global positioning system,gps)信号缺失的区域,基于gps定位信号的巡检方案将无法应用于该场景下,在gps缺失的场景下,使用同步定位与地图创建(simultaneous localization and mapping,slam)算法进行定位是工业界常用的解决方案,然而目前算法效果最好、最先进的(state-of-the-art,sota)的slam算法在低纹理、场景结构单一的建筑表现巡检任务中依然存在鲁棒性问题,无法保障无人机巡检的安全性。
技术实现思路
1、本发明的目的在于提供一种基于深度强化学习的核电巡检方法、装置、设备及介质,旨在解决由于现有技术无法提供一种有效的核电巡检方法,导致无人机巡检的执行效率低且成功率低的问题。
2、一方面,本发明提供了一种基于深度强化学习的核电巡检方法,所述方法包括下述步骤:
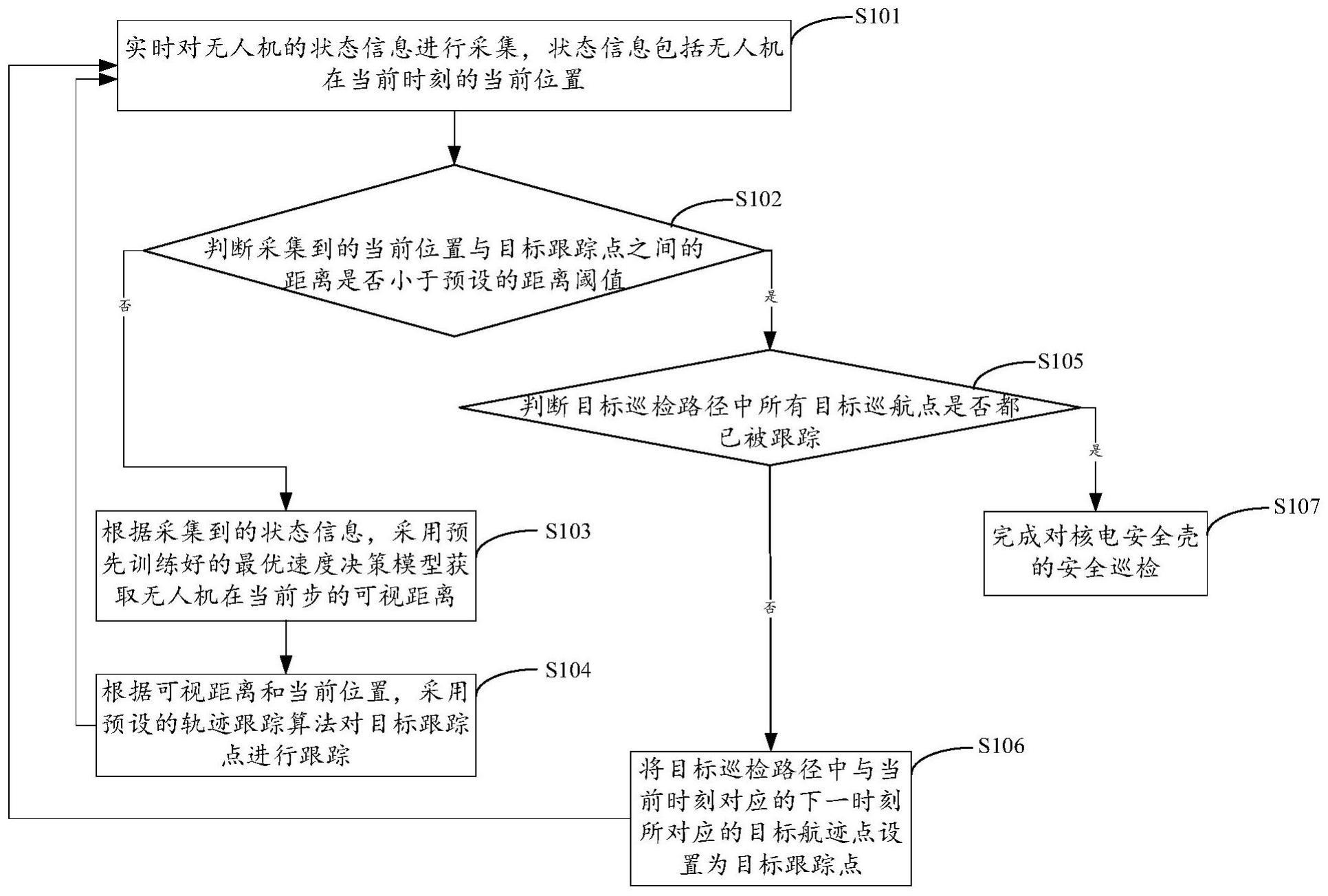
3、实时对无人机的状态信息进行采集,所述状态信息包括所述无人机在当前时刻的当前位置;
4、判断采集到的所述当前位置与目标跟踪点之间的距离是否小于预设的距离阈值,所述目标跟踪点为预先对核电安全壳规划的目标巡检路径中的某一个目标航迹点;
5、是则,判断所述目标巡检路径中所有目标航迹点是否都已被跟踪,是则,完成对所述核电安全壳的安全巡检,否则,将所述目标巡检路径中与所述当前时刻对应的下一时刻所对应的目标航迹点设置为目标跟踪点,并跳转至所述实时对无人机的状态信息进行采集的步骤;
6、否则,根据采集到的所述状态信息,采用预先训练好的最优速度决策模型获取所述无人机在当前步的可视距离;
7、根据所述可视距离和所述当前位置,采用预设的轨迹跟踪算法对所述目标跟踪点进行跟踪,并跳转至所述实时对无人机的状态信息进行采集的步骤。
8、优选地,所述采用预先训练好的最优速度决策模型获取所述无人机在当前步的可视距离的步骤之前,所述方法还包括:
9、在预先搭建好的第一仿真环境中,根据预先训练好的势函数集对所述最优速度决策模型进行离线训练;
10、对在对所述最优速度决策模型进行离线训练过程中收集到的第一离线经验数据集进行数据处理,得到真实奖励样本集;
11、根据所述真实奖励样本集和预设的真实奖励预测器损失函数,对真实奖励预测器进行训练;
12、在预先搭建好的第二仿真环境中,根据已训练好的所述真实奖励预测器预测的真实奖励信号,对已离线训练好的所述最优速度决策模型进行微调训练。
13、优选地,所述根据预先训练好的势函数集对所述最优速度决策模型进行离线训练的步骤之前,所述方法还包括:
14、在所述第一仿真环境中,根据预先规划的离线巡检路径、预设的每步动作的执行时间以及预设的离线可视距离,收集仿真无人机在执行所述离线巡检路径的任务中的第二离线经验数据集;
15、根据所述第二离线经验数据集、预设的第一奖励函数、预设的势函数目标公式以及预设的势函数更新规则,对势函数进行训练,训练好的所有所述势函数构成所述势函数集。
16、优选地,所述根据预先训练好的势函数集对所述最优速度决策模型进行离线训练的步骤,包括:
17、根据预设的筛选规则对所述势函数集中的势函数进行筛选,得到奖励塑形势函数;
18、根据所述奖励塑形势函数和预设的奖励塑形项公式,计算得到奖励塑形项;
19、根据所述奖励塑形项和预设的第二奖励函数,对所述最优速度决策模型进行离线训练。
20、另一方面,本发明提供了一种基于深度强化学习的核电巡检装置,所述装置包括:
21、信息采集单元,用于实时对无人机的状态信息进行采集,所述状态信息包括所述无人机在当前时刻的当前位置;
22、第一判断单元,用于判断采集到的所述当前位置与目标跟踪点之间的距离是否小于预设的距离阈值,所述目标跟踪点为预先对核电安全壳规划的目标巡检路径中的某一个目标航迹点;
23、第二判断单元,用于是则,判断所述目标巡检路径中所有目标航迹点是否都已被跟踪,是则,完成对所述核电安全壳的安全巡检,否则,将所述目标巡检路径中与所述当前时刻对应的下一时刻所对应的目标航迹点设置为目标跟踪点,并触发所述信息采集单元执行实时对无人机的状态信息进行采集;
24、距离获取单元,用于否则,根据采集到的所述状态信息,采用预先训练好的最优速度决策模型获取所述无人机在当前步的可视距离;以及
25、目标跟踪单元,用于根据所述可视距离和所述当前位置,采用预设的轨迹跟踪算法对所述目标跟踪点进行跟踪,并触发所述信息采集单元执行实时对无人机的状态信息进行采集。
26、优选地,所述装置还包括:
27、离线训练单元,用于在预先搭建好的第一仿真环境中,根据预先训练好的势函数集对所述最优速度决策模型进行离线训练;
28、数据处理单元,用于对在对所述最优速度决策模型进行离线训练过程中收集到的第一离线经验数据集进行数据处理,得到真实奖励样本集;
29、预测器训练单元,用于根据所述真实奖励样本集和预设的真实奖励预测器损失函数,对真实奖励预测器进行训练;以及
30、微调训练单元,用于在预先搭建好的第二仿真环境中,根据已训练好的所述真实奖励预测器预测的真实奖励信号,对已离线训练好的所述最优速度决策模型进行微调训练。
31、优选地,所述装置还包括:
32、离线数据收集单元,用于在所述第一仿真环境中,根据预先规划的离线巡检路径、预设的每步动作的执行时间以及预设的离线可视距离,收集仿真无人机在执行所述离线巡检路径的任务中的第二离线经验数据集;以及
33、势函数训练单元,用于根据所述第二离线经验数据集、预设的第一奖励函数、预设的势函数目标公式以及预设的势函数更新规则,对势函数进行训练,训练好的所有所述势函数构成所述势函数集。
34、优选地,所述离线训练单元包括:
35、势函数筛选单元,用于根据预设的筛选规则对所述势函数集中的势函数进行筛选,得到奖励塑形势函数;
36、奖励塑形计算单元,用于根据所述奖励塑形势函数和预设的奖励塑形项公式,计算得到奖励塑形项;以及
37、离线训练子单元,用于根据所述奖励塑形项和预设的第二奖励函数,对所述最优速度决策模型进行离线训练。
38、另一方面,本发明还提供了一种计算设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述一种基于深度强化学习的核电巡检方法所述的步骤。
39、另一方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述一种基于深度强化学习的核电巡检方法所述的步骤。
40、本发明实时对包含无人机在当前时刻的当前位置的状态信息进行采集,判断当前位置与目标跟踪点之间的距离是否小于距离阈值,是则,判断目标巡检路径中所有目标航迹点是否都已被跟踪,是则,完成对核电安全壳的安全巡检,否则,设置下一时刻所对应的目标航迹点为目标跟踪点,并跳转至实时采集状态信息的步骤,直至完成所有航迹点的跟踪,否则,根据采集到的状态信息,采用预先训练好的最优速度决策模型获取无人机在当前步的可视距离,根据可视距离和当前位置,采用预设的轨迹跟踪算法对目标跟踪点进行跟踪,从而提升了巡检任务的平均成功率和执行效率。
- 还没有人留言评论。精彩留言会获得点赞!