车辆轨迹预测模型构建方法、车辆轨迹预测方法及系统与流程
本发明属于轨迹预测
技术领域:
,具体涉及一种融合了目的地信息与轨迹信息的车辆轨迹预测模型构建方法、车辆轨迹预测方法及系统。
背景技术:
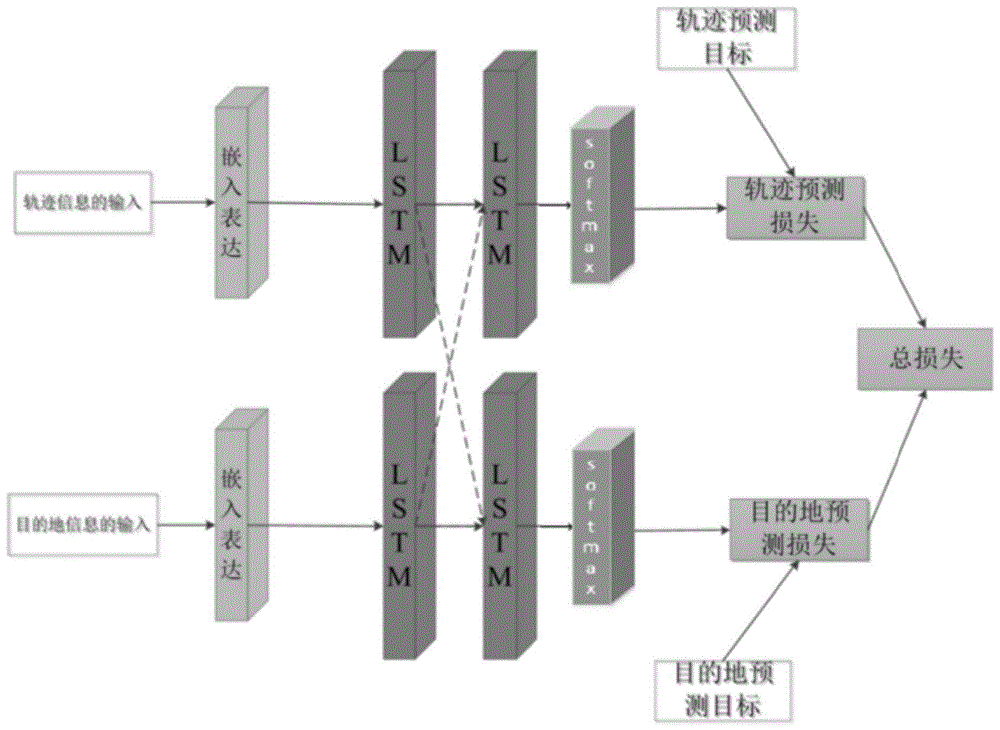
:轨迹预测轨迹预测是指采用对象的历史轨迹数据,对于出租车而言,主要是gps定位数据,基于大量的历史轨迹建立轨迹预测模型,以轨迹的已知部分作为预测模型的输入,通过模型的推演运算,得出轨迹的下一时刻所在道路。其本质也属于位置预测的一种。出租车的轨迹预测可以改善城市交通安全,属于智能交通的一部分。对于交管部门来说可以有效提高对于出租车这一公共交通资源的控制与利用,同时有助于缓解城市的拥堵状况,提高城市道路的利用状况并为广大市民带来切实利益。目前根据已有的轨迹片段进行轨迹预测的方法不断涌现,但由于历史轨迹的多样性和场景的多样性,导致很多模型不能取得很好的性能或是缺乏可迁移性。且目前的出租车轨迹预测方法多是在小区划分的基础上进行,这种粗粒度的划分可能会不满足某些任务场景下的特殊需要。技术实现要素:针对现有技术的缺陷或不足,本发明提供了一种车辆轨迹预测模型构建方法。为此,本发明所提供的车辆轨迹预测模型构建方法包括:步骤一,对目标区域待预测n+1时刻之前合理时间范围内的车辆轨迹数据进行清洗和校正,得到预处理数据,该预处理数据包括多条轨迹数据,任意条轨迹数据中包括多个轨迹点,各轨迹点的坐标为经纬度坐标;步骤二,将预处理数据中的各轨迹点的经纬度坐标与目标区域地图数据中的道路id对应,得到包含道路id信息的轨迹数据集,其中任意条轨迹数据为:t={r1,r2,...,ri,...,rn},其中ri表示在i时刻车辆所在的道路id,i=1,2,....,n;i=1表示所述合理时间范围的起始时刻,每个时刻对应一个采样点;步骤三,构建轨迹数据集中每一条轨迹数据的轨迹信息向量和目的地信息向量,构成轨迹数据向量集;构建每一条轨迹数据轨迹信息向量的标签和目的地信息向量的标签,构成标签数据集;其中,任意轨迹数据t={r1,r2,...,ri,...,rn}的轨迹信息向量t'={ri-k,ri-k+1,...,ri-1,ri},目的地信息向量t”={r1,r2,...,ri-k,ri-k+1,...,ri-1,ri},1≤i-k≤i-1,1≤k≤10;t'的标签为ri+1;t”的标签为rn;初始时2≤i≤11,且i-k≥1;步骤四,利用轨迹数据向量集和标签数据集对上一次训练得到的traj-mtl网络模型进行训练得到车辆轨迹车辆轨迹预测模型;初始时,traj-mtl网络包括两条通道,分别为轨迹预测通道和目的地预测通道,每条通道由依次连接的输入层、嵌入层、隐藏层和输出层构成;所述隐藏层由依次连接的第一层lstm网络、全连接层、第二层lstm网络构成,且两条通道的隐藏层中的第一层lstm网络的输出拼接后,将得到的拼接数据分别输入两个通道的全连接层,之后依次经各自通道的第二层lstm网络和输出层;所述训练过程中的损失函数中的损失为两个通道训练过程中损失之和;所述轨迹预测通道的嵌入层将每条轨迹数据的t'和其标签中的各道路id进行高维向量表示,生成各轨迹数据的轨迹信息向量的嵌入表达矩阵和该矩阵的标签向量,构成轨迹信息向量的嵌入表达矩阵集合和标签向量集合,作为轨迹预测通道内第一层lstm网络的输入和输出;所述目的地预测通道的嵌入层将每条轨迹数据的t”和其标签中的各道路id进行高维向量表示,生成各轨迹数据的目的地信息向量的嵌入表达矩阵和该矩阵的标签向量,构成目的地信息向量的嵌入表达矩阵集合和标签向量集合,作为目的地预测通道内第一层lstm网络的输入;步骤五,i=i+1,循环执行步骤三和四,直至i=n-1,得到待预测n+1时刻的道路轨迹预测模型。可选的,初始时,i=3,4或5,i-k=1。可选的,所述合理时间范围是一天或连续的2-7天,每30秒为一个采样点。可选的,所述道路id的高维向量获取方法包括:采用自然语言处理中的word2vec模型中的skip-gram算法对目标区域的所有道路id进行训练,构成d×|v|的矩阵,该矩阵的每个列向量为相应道路id的高维向量,d为每条道路对应的高维向量的维度,|v|为目标区域的道路数目,200≤d≤600。可选的,所述训练过程中采用的损失函数为玻尔兹曼分布的极小化负对数似然函数。可选的,所述输出层为softmax层。进一步,本发明提供了一种车辆轨迹预测方法。为此,本发明所提供的车辆轨迹预测方法包括:步骤1,数据处理;对目标区域待预测n+1时刻之前的合理时间范围内的车辆轨迹数据进行清洗和校正,得到预处理数据;将预处理数据中的各轨迹点的gps经纬度坐标与目标区域地图数据中的道路id对应,得到由道路id构成的轨迹数据集;步骤2,构建训练集:生成每一条轨迹数据的轨迹信息向量和目的地信息向量,构成待预测数据,i取n,任意条轨迹数据的轨迹信息向量t'={rn-k′,rn-k′+1,...,rn-1,rn},目的地信息向量t”={rn-k′,rn-k′+1,...,rn-1,rn};步骤3,轨迹点预测将所述待预测数据输入到上述训练好的模型中,两个通道的输出相同,该输出为各条轨迹的待预测n+1的时刻预测结果;步骤4,模型更新及预测:i=n+1,采用所述步骤二和三对上一待预测时刻的预测模型进行更新,得到下一待预测时刻的预测模型;执行步骤1、2和3对下一待预测n+2时刻的轨迹进行预测;步骤5,i=n+1+1,循环执行步骤4进行车辆轨迹预测。可选的,所述待预测n+1时刻之前的合理时间范围最少为30分钟。可选的,10≤k′≤60。同时,本发明还提供了一种车辆轨迹预测系统。为此,本发明所提供的车辆轨迹预测系统包括数据处理模块、模型更新模块和预测模块;所述数据处理模型用于对待预测数据进行处理,构建待预测数据及模型更新所用数据;所述模型更新模型,用于对上一时刻的预测模型进行更新;所述预测模块,利用待预测数据和更新后的模型对车辆轨迹进行预测,输出预测结果。本发明从实际出发考虑到目的地在出租车轨迹预测中不可避免的导向作用,所以将目的地信息加入到轨迹信息中,实现了基于多任务学习的城市规模的出租车轨迹有效预测;采用嵌入向量表示城市区域中的路段信息,分别对出租车的轨迹信息和目的地信息进行编码,以便能够将数目众多的道路信息送入深度神经网络中,然后分别将轨迹信息和目的地信息的嵌入表达送入长短期记忆网络(lstm)生成包含所有已知轨迹信息的长向量,利用多任务学习中的参数软共享方式将历史轨迹信息与目的地信息进行融合,通过全连接层进行解析与特征提取,以得到对每一条道路的概率预测;本发明采用多任务学习的方式,充分利用了已知轨迹信息与目的地信息,能有效提升轨迹预测的准确性。进一步,在模型的训练过程中采用了一种高效的损失函数,使模型能够更好地训练。附图说明图1本发明的城市规模出租车轨迹预测模型结构示意图。具体实施方式除非有特殊说明,本文中的术语根据本领域技术人员常规认识理解。本发明所述对车辆轨迹数据进行清洗和校正,其中数据清洗目的是去除无效数据、格式错误和异常数据、在某个时间段内gps地理位置没有变化以及不在目标区域内的数据,得到合格数据;数据清洗的方法手段对于本领域技术人员来讲是公知的。本发明的地图数据来自于现有市售的目标区域的地图数据,该数据包括区域内的道路、各道路的id、各道路的单双向标志、各道路上的采样点(一个道路id上设有多个采样点,每个采样点用相应的经度和纬度表征)。例如,购自四维图新的西安市地图数据。下面结合附图及实施例对本发明做进一步的详细说明。实施例1:本实施例数据来源于西安市交通局运输管理中心的西安市出租车真实数据记录,其中包含了出租车行驶过程中的定位数据,每条记录包含车辆的多种信息,涵盖西安二环区域内所有道路6093条具体的实验数据为2016年1月1日至1月7日的西安市二环区域内的出租车数据,时刻划分的根据是gps采样,每30秒一个采样点,采用本发明的方案训练轨迹预测模型;该实施例中的n=7*24*3600/30+1,k=2,3,5,8或10,初始时,i=11;初始网络的输出层为输出层为softmax层,训练过程中的损失函数采用玻尔兹曼分布的极小化负对数似然函数:其中,系数σ2由网络自行学习得到,p是相关任务的发生概率,x是模型的输出,y是标签,w表示当前任务,fw表示模型的输出x与标签y之间的函数关系,c和c’表示具体的标签,和分别表示模型的输出x与标签c和c’之间的函数关系;本实施例中,模型中的所有参数为:神经单元数300,迭代次数设为100次,训练批次大小设置为256,嵌入维度为512,学习率设置为0.0003。训练集、验证集与测试集的比例为8:1:1。本实施例中,轨迹预测实验结果如表1所示:表1本发明的轨迹预测实验结果实施例2:该实施例与实施例1不同的是,k取3,训练批次大小设置为256,取不同的迭代次数和嵌入维度进行模型训练结果如表2所示。表2本发明预测模型参数敏感度测试验证结果迭代次数嵌入维度精确率召回率f1值502560.52540.49510.4895802560.52910.49770.49321002560.52930.50940.50241202560.52830.50100.49391002560.52760.50140.49401002560.50500.48920.47901005120.53370.53870.531610010240.52550.49770.4909实施例3:采用实施例1得到的轨迹预测模型对实施例1所使用数据未来一天的车辆轨迹进行预测。同时,基于实施例1所用数据,将本发明预测方法结果与现有的其他基于机器学习的轨迹预测方法进行了对比。从表3中可以看出,对于机器学习中的其他神经网络或者模型而言,能够融合目的地信息的多任务学习在轨迹预测过程中是一项非常有效的方法。在精确率上,同样是采用lstm的模型,多任务学习能够比单一的lstm网络高出13.02%,而对在lstm上改进的e-dam同样能够高出8.35%。由此可见,在已知的轨迹信息中,能够挖掘更多的信息,比如目的地的信息,对轨迹预测的帮助也是极大的。表3本发明预测模型与其他模型预测实验结果对比实验结果精确率召回率f1值bp神经网络0.38150.38420.3828cnn0.39030.38970.3900lstm0.40350.39640.3999e-dam0.45020.45220.4511traj-mtl0.53370.53870.5316当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1