一种基于多信号灯强化学习的交通组织方案优化方法
1.本发明涉及交通信号灯控制领域,具体涉及一种基于多信号灯强化学习的交通组织方案优化方法。
背景技术:
2.在科技信息化的时代,人类的生活越来越丰富,现在大多数家庭都拥有自己代步的交通工具
‑
汽车,这就导致了在城市中各种各样的交通问题,比如等待时间过长、车道占有率过高等。随着人工智能的发展出现了许多交通智能化技术,开始有效地控制交通行为。智能体强化学习是当下人工智能发展的技术之一,目前强化学习为交通智能化技术的主流,其包括q
‑
learning、sarsa、td lambda等算法。
3.如何让智能体在交通环境中能够高效地学习这一直是近几年以来强化学习中的挑战。在传统的强化学习中训练智能体的方法都是不断地迭代策略进行重复训练,但是如此长此以往的训练只适用于单智能体上,对于多智能体来说并不合适。
4.考虑到对城市中的交通进行智能管理的问题,当智能体开始因策略执行行为时,如何在众多策略中选出一个优秀的策略并执行,是近几年研究的一个难点。
5.诸多研究对单个路口使用交通信号灯控制进行了广泛的研究,它们设定好了车辆以特定的方式到达目的地,研究大多数试图从车辆的行驶时间和路口的排队长度这两个方面进行优化。许多基于强化学习的方法试图从数据中通过学习来解决这个问题,例如通过建立q表使用q
‑
learning的早期实验,但是q
‑
learning的学习适合处理离散的状态,并且使用q
‑
learning部署到现在的交通环境中,面对单路口环境下,路口的情况有成千上万种,q表的容量是有限的,无法统计数以万计的状态,并不适合交通环境。
6.对于多路口交通信号优化,有一种方法是通过集中式训练智能体的学习进行联合建模并集体进行执行行为,但是这种方法有两个相关的常见问题:
7.a)随着智能体数量的增长,集中式训练的计算工作量太大;
8.b)在测试期间,每个智能体都是独立行动的,在动态的环境下智能体的变动需要结合周围其他智能体进行上下协调。
9.另一种方法是使用分散式的强化学习智能体来控制多路口进行交互,该方法就是将每个智能体基于自身周围的相邻路口的信息进行交互做出自己的决策。分散式的通讯更加的实用,并不需要集中决策具有良好的伸缩性,但在模型的收敛和速度上往往是很不稳定的。
技术实现要素:
10.针对现有技术中的上述不足,本发明提供了一种基于多信号灯强化学习的交通组织方案优化方法,使用多智能体和actor
‑
critic网络框架,能够优化多路口环境下的交通状态。
11.本发明的技术方案为:
12.一种基于多信号灯强化学习的交通组织方案优化方法,其步骤包括:
13.s1:构造actor网络
14.交通路网中包含有多个路口,每个路口的信号灯对应一个智能体,构造与多个智能体相对应的多个actor网络,所述actor网络包括状态空间集与行为空间集;
15.s2:传入观察值
16.多智能体观察多个路口的交通状态获得观察值,然后将观察值传入actor网络中的状态空间集中,观察值包括对应路口的车辆等待时间和车道占有率;
17.s3:传入行为方案
18.设定多智能体的行为方案,并将行为方案传入actor网络中的行为空间集中;
19.s4:计算行为偏转概率
20.在actor网络中,基于观察值与行为方案计算行为偏转概率;
21.s5:选择行为并更新状态
22.各个智能体基于行为偏转概率选择行为,并根据选择的行为更新状态空间集;
23.s6:critic网络学习
24.将actor网络中的行为偏转概率、初始状态空间集和更新后的状态空间集传入critic网络中进行集中学习训练,将学习后的信息反向传输到actor网络中,并将选择的行为方案输出;
25.s7:轨迹重构
26.actor网络进行行为选择后,将被封禁的路段从车辆的轨迹中删除并重新规划路径,并将重新规划的路径输出。
27.其中,actor网络根据策略函数,负责完成动作和周围的环境完成交互,该函数的近似公式为在公式中以s代表着智能体目前的状态,a代表着智能体选择的行为,这时对策略进行近似表示。此时策略π可以被描述为一个包含参数θ的函数:π
θ
(s,a)=p(a|s,θ)≈π(a|s)。状态空间的大小取决于智能体的数量,行为空间的大小取决于智能体的行为个数。critic网络使用的价值函数的近似,状态价值函数为引入了一个动作价值函数q^,这个函数由参数w描述,并接受状态s与动作a作为输入,计算后得到近似的动作价值,v为在状态s下智能的状态价值,即动作状态函数为ac算法中更新策略的参数使用的公式为θ=θ+α
▽
θ
logπ
θ
(s,a)v,其中α为训练步长,v为状态价值,θ为策略函数参数。
28.进一步的,在acotr网络之后构造subnet网络,subnet网络将actor网络传入的高纬度状态信息压缩处理成低纬度状态信息,然后将低纬度状态信息反向传入到actor网络中进行行为偏转概率的计算。传入subnet网络的矩阵个数为智能体的个数,将多智能体获取的状态信息作为输入,通过卷积进行特征提取,通过全连接层卷积输出特征转化为一维的一个向量,该向量为目标多智能体交互产生的状态信息。
29.subnet网络为卷积网络,分有一定层次且每层所采用的的滤波器不同,该subnet网络与所述actor网络共享参数。
30.进一步的,subnet网络在actor网络与critic网络之间,subnet网络将各个actor网络中初始状态空间集和更新后的状态空间集压缩,并和行为偏转概率一起传入critic网
络中进行集中学习。
31.进一步的,将道路的出车道进行道路离散化分为一定数量的路段,每个路段中含有相应的车辆,分别取每个路段中车辆长度与该段路段的长度进行取值比对得到车道占有率;车辆等待时间为当前道路中所有车辆的等待时间。
32.当道路的出车道进行道路离散化后然后分为n个路段,每个路段中含有相应的车辆,将车辆长度和路段长度的比值作为车道占有率加入到观察值中。不同路口有不同的车道数量,将道路离散化后,该路口的状态信息中就含有n+1中信息作为输入(包含1种路口车辆等待时间)。
33.在不同的路段中,每个路段中含有的车道数量也不同,在传入观察值时,需要将每段车道的车道占有率进行汇总然后传入到状态矩阵中。在车辆的出行道路中,在智能体的状态中设定s={s1,s2,
……
,sn,sn+1},其中s1,s2,
……
,sn,sn+1代表着车道占有率rate,sn+1代表着车辆排队的总时间,rate的计算公式为其中vehlength
i
代表车辆长度,roadlength
i
代表路段长度。
34.进一步的,步骤s3的行为方案为将左转信号灯设置红灯(禁左),和/或将右转信号灯设置红灯(禁右),和/或将直行信号灯设置红灯(禁直),和/或禁直掉头。当车流量需要涌入另一个交通流量较大的路段时,可以通过禁左、禁右、禁直和禁止掉头的行为进行调整。
35.进一步的,每个actor网络只针对各自的智能体负责,而不是负责全部或多个智能体,这样会使得智能体在学习过程中的行为延迟降低。每个智能体拥有相同的目标并且是同质的,可以通过参数共享的方式来加快训练速度。智能体的actor网络参数是相同的并不代表着这些智能体会采取相同的行为,每个智能体根据自身周围观察环境不同来采取不同的行为。并且,当策略在执行的过程中允许使用额外的信息来简化训练,在智能体协作的过程中,提出一个简易的actor
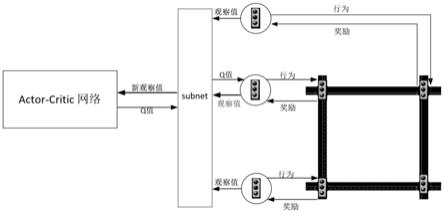
‑
critic算法,让critic网络在学习的过程中加入其他智能体的信息进行学习,所以根据参数共享的结果,每个智能体得到的td遵循如下梯度:g=
▽
θπ
logπ(a
i
|o
i
)(r+v
π
(s
t+1
)
‑
v(s
t
)),其中π为智能体的策略,a和s分别为智能体的行为和状态,o代表观察值,v代表状态价值函数,r为智能体的奖励值。
36.进一步的,在步骤s6中,critic网络根据输入的行为偏转概率、初始状态空间集和更新后的状态空间集计算当前价值v和下一个状态的价值v_;然后计算选择行为后的td
‑
error值,td=r+v
π
(s
′
)
‑
v
π
(s),r为反馈,s为最初获得的状态,s’为基于选择的行为得到的新的状态;最后计算td
‑
error的误差,td
‑
error=r+gamma*v
‑
v_,r为反馈,gamma为衰败值。
37.进一步的,步骤s7中,在不改变起点和终点的情况下,将封禁的路段改变路线,使车辆正常进行行驶,避免出现道路车辆死锁现象。
38.进一步的,轨迹重构后制定智能体所获取的奖励reward,并针对每回合下对车辆重构轨迹来计算整个路网的车辆总等待时间,其中reward=
‑
(wt
‑
selfwt),selfwt为原环境下道路中车辆的总等待时间,wt为通过强化学习每回合学习后车辆进行轨迹重构后的总等待时间;wt初始化为0,通过重构后的轨迹行驶车辆的排队时间与原有的排队时间进行比对来作为该回合的奖励。
39.进一步,使用路网畅通率和出行时间指数两个指标来评定交通状况。其中,路网畅通率为为路网在某一时间段t内,交通状态较好的路段里程与路网中所有路段里程的比值,
描述了路网总体通畅程度。其计算公式为rncr(t)为t时间段内的路网畅通率(t可取5min或者3min),n为路网中所包含路段数,l
ij
为第i条路段的长度,k
i
为二值函数,当路段i的交通状态等级属于可接受交通状态时,k
i
=1,否则k
i
=0,rncr(t)的取值范围为[0,1],值越大,表示路网状态越好,反之,路网状态越差。
[0040]
出行时间指数为实际出行时间与期望出行时间的比值,值越大表示交通状态越差,其计算公式为tti为出行时间指数,t为所取时间间隔,meantimeloss为在一段时间内的平均时间损失。
[0041]
本发明中的基于多信号强化学习的交通组织方案优化方法也可称为trajectory reward light,简称tr
‑
light,通过强化学习的两大要素奖励和状态以及多智能体之间的集中式学习分散式执行以及轨迹重构的思想来进行交通组织方案优化。
[0042]
本发明的有益之处在于:
[0043]
使用多智能体的强化学习,多智能体通过自主学习、分布协调和组织的能力,根据自身当前的状态与其他智能体进行交互学习,在这一过程中有效地配合其他智能体完成自己的学习并改变自身的状态完成最终高效的目标。
[0044]
将交通信号灯的控制作为动作的选择,将路口中的车辆等待时间和车辆与道路的占有率作为环境的观察值,通过集中式学习分布式执行的方法,将多路口的智能体进行训练学习,有效提高了路网的畅通率,同时在进行管控后对行驶该路段的车辆进行轨迹重构,将重构后的轨迹与强化学习相结合达到最佳效果。
[0045]
在ac算法的过程中将多智能体进行集中式的交互学习,智能体将自己执行的行为方式统一回馈到一个critic网络中,由同一个critic网络进行对其他智能体中的actor网络进行反向传递,这样的学习方式使得智能体之间能够更加稳定快速地收敛。
[0046]
subnet网络由神经网络构成,在传入高维数据后通过神经网络将这些数据进行压缩降维产生出新的信息,通过subnet网络传入到critic网络中进行学习,能够提升critic的学习效率。
附图说明
[0047]
图1为实施例1中的多智能体与单智能体环境区别示意图;
[0048]
图2为实施例1中的红绿灯行为方案设定示意图;
[0049]
图3为实施例1中的道路离散示意图;
[0050]
图4为实施例1中的多路口智能体协作示意图;
[0051]
图5为实施例1中的subnet网络示意图;
[0052]
图6为实施例2中的sumo仿真图;
[0053]
图7为实施例2中的不同算法实验对比图;
[0054]
图8为实施例3中的sumo仿真图;
[0055]
图9为实施例3中的不同算法实验对比图;
[0056]
图10为实施例4中的绵阳园艺山区域的sumo仿真地图;
[0057]
图11为实施例4中使用强化学习方法后迭代最终方案的结果示意图;
[0058]
图12为实施例4中不同算法的优化结果对比图。
具体实施方式
[0059]
下面结合附图,对本发明作详细的说明。
[0060]
所举实施例是为了更好地对本发明进行说明,但并不是本发明的内容仅局限于所举实施例。所以熟悉本领域的技术人员根据上述发明内容对实施方案进行非本质的改进和调整,仍属于本发明的保护范围。
[0061]
实施例1
[0062]
本实施例为多路口的基于多信号灯强化学习的交通组织方案优化方法,使用多智能体、actor
‑
critic网络、subnet网络、轨迹重构来提高路网畅通率。多智能体环境是每个步骤中有多个智能实体的环境,如图1所示,为多智能体与单智能体环境的区别。
[0063]
首先构造actor网络,交通路网中包含有多个路口,每个路口的信号灯对应一个智能体,多个智能体需要构造多个相对应的actor网络,actor网络包括状态空间集与行为空间集。
[0064]
通过交通信号灯中的program来改变道路的状态,实现某种意义上的短暂封路来进行交通管控。本实施例中从实际出发将行为设定为将左转信号灯设置红灯(禁左),将右转信号灯设置红灯(禁右),将直行信号灯设置红灯(禁直),禁止掉头的四种方案。当车流量需要涌入另一个交通流量较大的路段时,可通过禁左、禁右、禁直和禁止掉头进行调整。在动作设定中,先设置动作空间,将设定好的行为方案依次传入动作空间中。如图2所示,因为动作的设定是通过信号灯来设计,动作集为a={program1,program2,
…
program16},其中16代表能进行选择行为的总数,将图2中的案例代入动作集当中,其中program1就代表着禁止左转的行为,动作集a={禁左,禁右,禁直,禁掉头
…
program16},图2中因为一共有4条路可进行设定的program,所以共有4*4=16种可行行为方案进行设定。
[0065]
智能体通过观察路口的环境获得实时交通状态,根据这些状态传递给设定的actor网络中的状态空间集进行后续的执行。当前道路的状态将使用路口处的车辆等待时间和车道占有率进行表示,如图3所示,将道路的出车道进行道路离散化分为了10段,每段中会有相应的车辆含在各个路段中,将车辆和路段的比值作为车道占有率加入到观察值中,不同路口有不同的车道数量,将道路离散化后,该状态就含有11种信息作为输入(包含1种路口车辆等待时间)。在传入观察状态时,需要将所有车道的每段车道占有率进行汇总传人到状态矩阵中。对于车辆的出行道路中,在智能体的状态中设定s={s1,s2,
……
,s10,s11},其中s1,
……
,s11代表着车道占有率rate,s11代表着车辆排队的总时间,
[0066]
如图4所示,使用actor
‑
critic网络与subnet网络结合,实现多交叉口智能体协作。在actor网络中,基于所述观察值与行为方案计算行为偏转概率,各个智能体基于行为偏转概率选择行为,并根据选择的行为更新状态空间集。每个actor网络只针对各自的智能体负责,每个智能体拥有相同的目标并且是同质的,可以通过参数共享的方式来加快训练速度,每个智能体根据自身周围观察环境不同来采取不同的行为。
[0067]
在acotr网络之后构造subnet网络,subnet网络将actor网络传入的高纬度状态信息压缩处理成低纬度状态信息,然后将低纬度状态信息反向传入到actor网络中进行行为偏转概率的计算。如图5所示,subnet网络为卷积网络,分有一定层次且每层所采用的的滤波器不同,该subnet网络与所述actor网络共享参数。传入subnet网络的矩阵个数为智能体的个数,将多智能体获取的状态信息作为输入,通过卷积进行特征提取,通过全连接层卷积输出特征转化为一维的一个向量,该向量为目标多智能体交互产生的状态信息。
[0068]
将actor网络中的初始状态空间集和更新后的状态空间集传入subnet网络中进行压缩,并和行为偏转概率一起传入critic网络中进行集中学习。critic网络根据输入的行为偏转概率、初始状态空间集和更新后的状态空间集计算当前价值v和下一个状态的价值v_;然后计算选择行为后的td
‑
error值,td=r+v
π
(s
′
)
‑
v
π
(s),r为反馈,s为最初获得的状态,s’为基于选择的行为得到的新的状态;最后计算td
‑
error的误差,td
‑
error=r+gamma*v
‑
v_,r为反馈,gamma为衰败值,并将学习后的信息反向传输到actor网络中。
[0069]
actor网络进行行为选择后,将被封禁的路段从车辆的轨迹中删除并重新规划路径,在不改变起点和终点的情况下,将封禁的路段改变路线,使车辆正常进行行驶,避免出现道路车辆死锁现象。
[0070]
轨迹重构后制定智能体所获取的奖励reward,并针对每回合下对车辆重构轨迹来计算整个路网的车辆总等待时间,其中reward=
‑
(wt
‑
selfwt),selfwt为原环境下道路中车辆的总等待时间,wt为通过强化学习每回合学习后车辆进行轨迹重构后的总等待时间;wt初始化为0,通过重构后的轨迹行驶车辆的排队时间与原有的排队时间进行比对来作为该回合的奖励。
[0071]
实施例2
[0072]
本实施例为针对单路口进行基于多信号灯强化学习的交通组织方案优化方法。本实施例采用的仿真平台为sumo,sumo是一种开源的道路模拟器,可以满足模拟实验中所需要的相关数据的收集还有交通行为的模拟以及需要的路网建设,最关键的是还能收集到交通信号灯的配时数据。编写代码的开发ide工具使用的是pycharm,在完成相关的强化学习和神经网络的构建使用的是tensorflow
‑
gpu
‑
1.4.0版本和numpy,需要完善上述扩展,其次最重要的是要实施sumo traci的交通控制接口,traci可以帮助扩展在动态时控制交通信号灯,可以调用sumo仿真工具、获取单个的车辆信息以及获取每条道路的详细数据和实时路况。
[0073]
第一个实验采取双路口环境下,双红绿灯协调模式,在本实验过程中共有3000辆车部署到该仿真系统,模式初始设置为30辆汽车,随机种子参数设为4。在该环境下交通中的od对共有13对,在od对中多数轨迹是由北向南方向进行行驶,在在无任何强化学习方法的条件下,该模型中的汽车总等待时间为11567秒,在图6中由北向南方向中间路段两路口的车流量拥堵,在加入相关强化学习的方法后通过模型不断地训练,给出的优化方案方法中,最合理的结果如图6所示将两路口中由北向南方向的路段实时封禁,同时根据对于封禁路段中的车辆进行轨迹重构,改方向车辆通过其他路段达到目的地,其中该模型的对比实验如图7所示的结果,当算法跑到最优的结果的各个路口实施的方案如图7所示结果样式(tr
‑
light即为本发明中的多信号灯强化学习)。
[0074]
实施例3
[0075]
本实施例9宫格多路口实验模型,每个矩形代表一个信号交叉口,每两个相邻的十字路口由两条车道相连。
[0076]
在本实施例的设定中需要在sumo仿真软件中完成以下参数设定,在该9宫格环境中共有7000辆车步入到仿真系统,模型设置初始车辆为50辆车,其中最短的车辆行驶路径为2条,最长车辆行驶路径为7条,设置随机种子参数为10。
[0077]
在实验模型构建完成后,将每个智能体的动作方式按照之各自的行为方式构建好,在原条件下该环境中的汽车总等待时长为24732秒,该实验交通环境下od对共有21对,在原环境下9宫格右下区域交通量比较大,根据od的查询大部分车辆的轨迹终点在右下角路口,导致整个地图的路网环境不通畅,图8为模型实验最终结果后每个路口给出的最终方案实施上图为路口最终的实行方案,将右下方路口以及相邻路口实时交通管控,同时其他路口维持原来路口的方案预定,并将通往封禁方向的车辆实时轨迹重构,图9为不同算法实行的对比试验结果(tr
‑
light即为本发明中的多信号灯强化学习)。
[0078]
由图9看出在给定的实验环境下,因为由神经网络的作用,多信号灯强化学习效果非常明显,能够较快的应对各个路口之间的协调。
[0079]
实施例4
[0080]
本实施例将绵阳园艺山区域的地图使用sumo软件进行仿真出来,如图10所示,在sumo中构建好我们的仿真区域,并将红绿灯的原始配时时间设定好,在红绿灯的的设置中,选取了几个交通流量比较大的路口,并设置好红绿灯。本实施例中将与传统的q
‑
learning和dqn算法进行对比实验,针对该路网车辆总等待时间进行对比试验,在此环境中加入了真实的车辆数据,在晚高峰17:00到19:00时间内,该区域一共有51320辆汽车,在不使用任何强化学习方法的情况下,按交通信灯的原配时时间内,该环境中的车辆总等待时长338798秒,在历史轨迹数据中晚高峰时间段,a、b、c、d四个路口的车流量最大,使用强化学习方法模型后迭代最终方案的结果如图11所示,同时不同算法对该环境的总体优化结果如图12所示。
[0081]
根据图12反应的结果来看在迭代的前50回合内dqn算法和本发明中tr
‑
light算法的效果翻译差别还不是特别的明显,在迭代的次数变多后,tr
‑
light模型中的critic网络开始逐渐的发生作用td
‑
error开始自我学习更新,逐渐的往较好的行为模式去行动,开始更改自己的相应策略,来保持策略的最新模式,由于q
‑
learing的强化学习方法并不含有神经网络,无法根据状态进行预测,只是每次逐步的去选择最优的方式,所以优化效果并不明显,最后的结果也无法得到收敛,tr
‑
light模型的收敛速度随着迭代的增加开始提速,是最优先达到收敛结果的。
[0082]
针对添加的各个目标路口,对单路口和多路口的交通指标收集到的如下数据对这3种优化方法进行比对如下表1所示:
[0083]
路口优化方法迭代次数路网畅通率时间指数单路口q
‑
learning1360.476741.98378单路口dqn940.594211.43793单路口sarsa1440.493271.82331单路口pg1050.547321.31251单路口tr
‑
light620.683151.12741
多路口q
‑
learning43000.349753.46581多路口dqn16000.436532.67138多路口sarsa47000.314623.60431多路口pg31000.405872.96971多路口tr
‑
light11670.513121.94672
[0084]
表1
[0085]
在多交叉口环境下,通过控制交通信号灯设计一种tr
‑
light的模型,借助了actor
‑
critic的算法框架,同时使用了智能体之间集中式学习分散式执行的方法,结合了集中式学习和分散式学习的优点,使得算法在收敛速度上得到了较大的提升。通过多路口实验数据的比对,传统算法上的q
‑
learning算法在处理交通环境种中由于智能体的状态是百变多样的,q学习没有神经网络无法对状态进行预测所以导致了该算法的难以得到收敛。对于dqn算法来讲虽然有了神经网络的辅助但在多智能体的交互方法上没有得到实施,tr
‑
light模型的设计使得交通状态得到改善,为后期多智能体强化学习的交通信号控制的应用奠定了基础。
[0086]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1