基于可解释时空注意力机制的停车泊位预测方法
1.本发明属于泊位预测方法技术领域,具体涉及一种基于可解释时空注意力机制的停车泊位预测方法。
背景技术:
2.近年来,随着城市化进程的深入,城市居民私家车保有量急剧增加,停车位的需求量也在不断的增加。通常情况下,街道的停车位有限,人们寻找街道上免费停车位所花费的时间和燃油成本已经超过了停车场付费;同时,在寻找街道上停车位的过程中,也给交通的流畅度和空气质量带来了不利的影响。
3.基于上述现状,提出城市智能化概念,城市智能化的一个主要体现就是通过物联网(internetof things,iot)来解决当前城市所存在的问题,例如停车位紧张问题。其主要思想是通过使用传感器监控城市的交通状况、空气温度、污染水平以及停车场使用率等数据来了解城市的状态。因此,我们可以通过使用物联网监控一个城市停车场中停车位的使用率方法,来解决停车位紧缺问题,从而达到智能化的效果。虽然监控单个停车位的方法难以执行,但是可以通过统计进出非街道停车场的车辆数据,对未来停车场的入驻率进行分析预测。
4.停车场泊位预测是充分发挥停车智能化效果的关键。泊位预测是一个典型的时间序列预测问题。时间序列的预测可根据预测目标的不同分为长时预测(多步预测)和短时预测(单步预测)。时间序列预测与分类和回归问题不同,时间序列预测问题增加了观察值之间的顺序和时间依赖的复杂性,这使得时间序列预测问题比一般的预测问题更加复杂。
5.目前,预测方法可分为:基于统计的预测、基于机器学习的预测。基于统计的预测包括指数平滑法、马尔科夫预测法、自回归移动平均模型(autoregressive integrated moving averagemodel,arima)等预测方法;基于机器学习的预测方法包括bp神经网络、小波神经网络、回归树、支持向量机、循环神经网络和长短期记忆神经网络等方法。
6.但是,上述两大类方法的预测高精度均建立在预测步数量足够少的基础上,一般是1-3个预测步长。如果预测步增加,那么预测精度将大幅下降。同时,上述方法无法对含有各种不确定因素的影响的模型进行精确预测。
技术实现要素:
7.为了解决现有技术中存在的问题,本发明的目的是提供一种基于可解释时空注意力机制的停车泊位预测方法,解决了现有停车泊位预测方法精度低、结果不稳定的问题,并且对时空注意力机制模型做出解释。
8.为了实现上述目的,本发明所采用的技术方案是,基于可解释时空注意力机制的停车泊位预测方法,包括以下步骤:
9.步骤s1:确定待预测停车场,对停车场泊位数据进行收集;
10.步骤s2:对步骤s1收集到的停车场泊位数据进行预处理,包括数据清洗、特征提
取、和归一化处理;
11.步骤s3:构建基于双向长短期记忆神经网络(bi-directional long short-term memory, bilstm)的泊位预测模型;
12.步骤s4:在步骤s3的基于bilstm的泊位预测模型基础上,构建时空注意力机制层捕获全局关键特征信息;
13.步骤s5:将步骤s2中预处理之后的数据按4:1的比例划分为训练集与测试集,用训练集数据训练步骤s4中构建的时空注意力机制神经网络模型,用自适应矩估计(adaptive moment estimation,adam)优化算法寻找全局最优点,用变量控制方法选择超参数,损失函数为均方误差(mean square error,mse);自适应矩估计优化算法通过使用动量和自适应学习率来加快收敛速度,不断优化神经网络模型;
14.步骤s6:在步骤s5优化的时空注意力机制神经网络模型中运行测试集数据,统计并记录运行结果,得到泊位预测结果、空间注意力权重和时间注意力权重,通过时空注意力权重变化训练得到的神经网络模型能很好的反映泊位预测结果,即通过时空注意力权重变化对泊位预测结果做出解释。
15.进一步的,所述步骤s1中收集的停车场泊位数据包括:停车场名称(parkingname)、收集时间(lastupdated)、泊位入驻数(occupancy)和停车场泊位容量(capacity)。
16.进一步的,在所述步骤s2中数据清洗的方法是采用临近平均值代替缺失数据,去除异常数据;特征提取的方法是将收集时间(lastupdated)、泊位入驻数(occupancy)和停车场泊位容量(capacity)的有效时空特征提取出来;归一化处理的方法是采用min-max标准化对原始数据进行线性变换,使结果值映射到区间[0,1]之间。
[0017]
进一步的,步骤s3中bilstm包括两条单向lstm链式结构,是由前向lstm和后向 lstm组合而成。每条单向lstm的当前时间步t的输入为x
t
=[x1,x2,
…
,xw],w为滑动窗口的长度,lstm结构具体为:
[0018]it
=σ(wix
t
+u
iht-1
+bi)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0019][0020]ft
=σ(wfx
t
+ufh
t-1
+bf)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0021]ot
=σ(wox
t
+u
oht-1
+bo)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0022][0023][0024][0025]ht
=o
t
tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0026]
公式(1)-(8)中,参数i
t
表示当前时间步t的输入门,参数σ表示sigmoid函数,参数 x
t
表示当前时间步t对应的输入序列,参数h
t-1
表示上一时间步的隐藏状态,参数f
t
表示当前时间步t的遗忘门,参数o
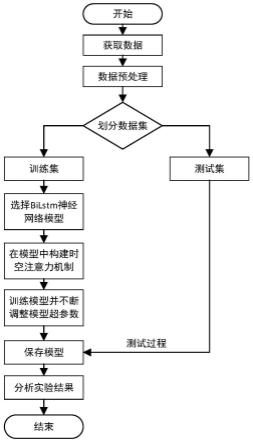
t
表示当前时间步t的输出门,tanh(x)为激活函数,参数表示当前时间步t对应的候选记忆细胞;参数wi表示输入门输入过程的权重参数,wf表示遗忘门遗忘
过程的权重参数,wo表示输出门输出过程的权重参数,wc表示记忆单元传输过程的权重参数;参数ui表示输入门状态转移权重参数,uf表示遗忘门状态转移权重参数,uo表示输出门状态转移权重参数,uc表示记忆单元状态转移权重参数;参数bi表示输入门偏差参数,bf表示遗忘门偏差参数,bo表示输出门偏差参数,bc表示记忆单元偏差参数;c
t
表示当前时间步t 对应的细胞状态。
[0027]
进一步的,步骤s4构建时空注意力机制的方法如下:
[0028]
步骤4.1.构建空间注意力模块,对当前时间步的输入序列x
t
=[x1,x2,
…
,xw]w×1先进行 sigmoid激活函数然后进行softmax正则化,得到空间注意力权重;
[0029]
步骤4.2.将上面得到的空间注意力权重s
t
与输入序列x
t
进行哈达玛积操作,得到x
t
′
;
[0030]
步骤4.3.将带有空间注意力权重的输入序列x
t
′
输入到bilstm中,得到隐藏层状态数据 h
t
;
[0031]
步骤4.4.构建时间注意力模块,将步骤c得到的隐藏层状态数据先经过relu函数激活,然后在正则化处理,得到时间注意力权重t
t
。
[0032]
进一步的,步骤4.1中所用公示如(9)-(10):
[0033][0034]
在公式(9)中,参数σ
t
是x
t
经过激活函数sigmoid得到的结果,σ1是x1经过sigmoid得到的结果,σ2是x2经过sigmoid得到的结果,σw是xw经过sigmoid得到的结果,对输入序列x
t
中的每一项进行sigmoid激活,激活函数会将输入序列x
t
中的值变换到0到1之间;
[0035][0036]
在公式(10)中,参数s
t
是σ
t
经过正则化函数softmax得到的结果,s1是σ1经过softmax 得到的结果,s2是σ2经过softmax得到的结果,sw是σw经过softmax得到的结果;将公式 (9)中得到的σ
t
进行softmax正则化处理,softmax函数会将输入序列σ
t
中的值变换到0到 1之间,并且其值累加和为1。
[0037]
进一步的,步骤4.2中所用公式如(11):
[0038]
x
t
′
=s
t
x
t
=[s1x1,s2x2,
…
,swxw]w×1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0039]
在公式(11)中,x
t
′
为空间注意力权重s
t
与输入序列x
t
进行哈达玛积操作的结果。
[0040]
进一步的,步骤4.3中所用公式如(12):
[0041]ht
=[h1,h2,
…
,hw]w×sꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0042]
在公式(12)中,h
t
为bilstm中的隐藏层状态输出,s为隐藏层的神经元个数。
[0043]
进一步的,步骤4.4中所用公式如(13)-(14):
[0044]rt
=relu(h
t
)=max(0,h
t
)=[r1,r2,
…
,rw]w×1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0045]
在公式(13)中,参数r
t
为h
t
激活后的结果,r1是h1经过relu得到的结果,r2是h2经过 relu得到的结果,rw是hw经过relu得到的结果。将隐藏层状态数据进行relu激活,relu函数会将值变为非负数。
[0046][0047]
在公式(14)中,参数t
t
为r
t
的正则化处理结果,t1是r1正则化后的结果,t2是r2正则化得到的结果,tw是rw正则化得到的结果。对公式(13)得到的r
t
进行正则化处理。
[0048]
与现有技术相比,本发明至少具有以下有益效果:
[0049]
本发明基于可解释时空注意力机制的停车泊位预测方法,通过双向长短期记忆神经网络 bilstm模块建立模型,bilstm中引入了门机制用于控制特征的流通和损失来避免梯度消失和梯度爆炸,解决长期依赖学习能力不足的问题。
[0050]
进一步的,本发明通过时空注意力模块建立模型,在空间注意力模块中对停车泊位数据进行权重计算选取相关性较高的数据输入到神经网络模型中,在时间注意力模块中对模型隐藏层数据进行权重计算选取权重较大的数据输出,通过时空注意力机制捕获全局关键特征信息,获得学习序列与目标序列的相关性,解决了现有技术中对泊位占有率预测结果不稳定、精度低的问题。
[0051]
进一步的,本发明采用的深度学习算法在处理大量停车场数据时具有良好的数据特征提取能力以及拟合非线性复杂系统的预测能力。
[0052]
进一步的,本发明可作为停车诱导信息系统(parking guidance information system,pgis)帮助用户辅助决策,不仅可以及时为用户提供泊位信息,降低停车时间和燃油消耗,还能对未来一段时间的泊位需求做出预估,缓解停车场周边交通运行的压力。
[0053]
进一步的,本发明通过高效地停车诱导,有效地提升停车场的泊位利用率,为用户提供更多的出行规划选择,具有良好的经济效益及社会效益。
附图说明
[0054]
图1是本发明基于可解释时空注意力机制的停车泊位预测方法的流程图;
[0055]
图2是本发明基于可解释时空注意力机制的停车泊位预测方法中bilstm的结构图;
[0056]
图3是本发明基于可解释时空注意力机制的停车泊位预测方法中lstm的结构图;
[0057]
图4是本发明基于可解释时空注意力机制的停车泊位预测方法中空间注意力机制的结构图;
[0058]
图5是本发明基于可解释时空注意力机制的停车泊位预测方法中时间注意力机制的结构图;
[0059]
图6是实施例中不同迭代次数bilstm的预测模型有无时空注意力机制均方根误差对比图;
[0060]
图7是实施例中不同隐藏层维度bilstm的预测模型有无时空注意力机制均方根误差对比图;
[0061]
图8是实施例中不同学习率bilstm的预测模型有无时空注意力机制均方根误差对比图;
[0062]
图9是实施例中预测值与真实值对比曲线图;
[0063]
图10是实施例中预测步为1、7、14、21、28、35时,空间注意力权重变化图;
[0064]
图11是实施例中时空注意力机制模型的时间注意力权重变化图;
[0065]
图12为不加时空注意力机制的时间注意力权重变化图;
具体实施方式
[0066]
以下将结合附图对本发明作进一步的描述,需要说明的是,以下实施例以本技术方案为前提,给出了详细的实施方式和具体的操作过程,但本发明的保护范围并不限于本实施例。
[0067]
一、本发明原理
[0068]
本发明基于可解释时空注意力机制的停车泊位预测方法,如图1所示,包括以下步骤:
[0069]
步骤1:针对待预测停车场,在固定时间段内均匀采集停车场泊位占有情况数据,收集的停车场泊位数据包括:停车场名称parkingname,收集时间lastupdated,泊位入驻数occupancy,停车场泊位容量capacity。
[0070]
步骤2:对步骤1收集到的停车场泊位数据进行预处理,包括数据清洗、特征提取和归一化处理,得到实验数据集,具体方法为:
[0071]
步骤2.1,本发明中数据清洗主要是对数据缺失值和异常值进行处理,数据缺失在研究过程中经常会发生,不仅容易丢失大量有价值的信息,而且还加剧了数据样本背后规律的不确定性。对于数据缺失一般有两种思路:一种是数据填充,另一种是直接舍弃整个样本数据。直接舍弃整个样本数据常常不是一个好的方法,根据实际应用场景选取合适的数据填充方法更具意义。常用的数据填充法有特殊值填充、均值填充、近邻法等。因为泊位数据是沿着时间轴变动的,本发明采用缺失值相临时刻的均值来填充,如公式(15)所示。
[0072][0073]
在公式(15)中参数x
t
′
表示t时刻的数据缺失值,x
t-1
表示t-1时刻的数据值,x
t+1
表示t+1 时刻的数据值。
[0074]
步骤2.2,特征提取采用主成分分析方法(principal component analysis,pca)将收集时间lastupdated、泊位入驻数occupancy和停车场泊位容量capacity等有效时空特征提取出来。假设输入样本集为d=(x1,x2,
…
,xn),输出维度为m,pca算法步骤为:
[0075]
a.对样本集进行中心化
[0076][0077]
在公式(16)中,xi′
为样本中心化后的值,xi为样本集中的每一个样本,为所有样本的均值。
[0078]
b.计算样本的协方差矩阵
[0079][0080]
如公式(17)所示,m为输出维度,d为输入样本的矩阵形式,d
t
为输入样本d的转置, c为输入样本d的协方差矩阵。
[0081]
c.对协方差矩阵做特征值分解
[0082]
cβi=λiβ
i i=1,2,
…
,n并且λ1≥λ2≥
…
≥λnꢀꢀꢀꢀ
(18)
[0083]
如公式(18)所示,c为输入样本d的协方差矩阵,λi为第i个特征值,βi为特征值λi所对应的特征向量。
[0084]
d.取最大的m个特征值所对应的单位特征向量w1,w2,
…
,wm。
[0085]
步骤2.3,归一化可以使没有可比性的数据变得具有可比性,同时保持相比较的两个数据之间的相对关系。为了加快预测模型的收敛效率,采用min-max标准化对原始数据进行线性变换,使结果值映射到区间[0,1]之间,转换函数如公式(19)所示:
[0086][0087]
在公式(19)中参数x
′
表示归一化之后的数据,参数x表示原始数据泊位入驻数,参数 min(x)表示原始数据泊位入驻数中的最小值,参数max(x)表示原始数据泊位入驻数中的最大值。
[0088]
步骤3:构建基于双向长短期记忆神经网络(bi-directional long short-term memory, bilstm)的泊位预测模型。
[0089]
如图2所示,bilstm是双向的lstm网络,由前向lstm
l
与后向lstmr组合,被用来建模上下文信息,其中,参数lstm
l
为前向lstm,参数(x0,x1,
…
,x
t
)为输入序列,参数lstmr为后向lstm,参数h
lt
为前向lstm的隐藏状态,参数h
rt
为后向lstm的隐藏状态,bilstm的隐藏状态输出{h
lt
,h
rt
}。
[0090]
由上可知,bilstm是由两条单向lstm链式结构组成,如图3所示,为lstm的内部结构,其中符号表示点乘,符号表示相加,符号tanh表示双曲正切激活函数,参数σ表示 sigmoid激活函数,参数i
t
表示当前时间步t的输入门,参数f
t
表示当前时间步t的遗忘门,参数o
t
表示当前时间步t的输出门,参数c
t-1
表示上一时间步记忆细胞,参数h
t-1
表示上一时间步的隐藏状态,参数h
t
表示当前时间步t的隐藏状态,c
t
表示当前时间步t对应的细胞状态。每条单向lstm的当前时间步t的输入为x
t
=[x1,x2,
…
,xw](w为滑动窗口的长度),lstm结构具体为:
[0091]it
=σ(wix
t
+u
iht-1
+bi)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(20)
[0092][0093]ft
=σ(wfx
t
+ufh
t-1
+bf)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0094]ot
=σ(wox
t
+u
oht-1
+bo)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(23)
[0095][0096][0097][0098]ht
=o
t
tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(27)
[0099]
公式(20)-(27)中,参数x
t
表示当前时间步t对应的输入序列,tanh(x)为激活函数,参数表示当前时间步t对应的候选记忆细胞;参数wi表示输入门输入过程的权重参数,wf表示遗忘门遗忘过程的权重参数,wo表示输出门输出过程的权重参数,wc表示记忆单元传
输过程的权重参数;参数ui表示输入门状态转移权重参数,uf表示遗忘门状态转移权重参数,uo表示输出门状态转移权重参数,uc表示记忆单元状态转移权重参数;参数bi表示输入门偏差参数, bf表示遗忘门偏差参数,bo表示输出门偏差参数,bc表示记忆单元偏差参数。
[0100]
sigmoid激活函数是一个常见的s型函数,由于其单增以及反函数单增的特性常被用于神经网络激活函数,其可以将一个实数映射到0-1之间。tanh为双曲正切函数,将输入值转换为-1至1之间。lstm中输入门i
t
可以将新的信息选择性的记录到细胞状态中,遗忘门f
t
可以将细胞状态中的信息选择性遗忘,输出门o
t
可以将细胞状态中的信息输出。
[0101]
步骤4:在步骤3的基于双向lstm的泊位预测模型基础上,构建时空注意力机制层捕获全局关键特征信息。
[0102]
bilstm神经网络模型接受输入序列、上一时间步记忆细胞和上一时间步的隐藏状态,经过输入门、遗忘门和输出门的控制变换,得到当前时间步记忆细胞c
t
和当前时间步的隐藏状态 h
t
。如图4所示,输入序列x
t
经过sigmoid和softmax激活生成空间注意力权重。如图5所示,隐藏状态h
t
经过relu和softmax激活生成时间注意力权重。具体步骤如下:
[0103]
步骤4.1构建空间注意力模块,对当前时间步x
t
的输入序列x
t
=[x1,x2,
…
,xw]w×1先进行sigmoid激活函数然后进行softmax正则化,得到空间注意力权重。如公式(28)-(29):
[0104][0105]
在公式(28)中,其中σ
t
是x
t
经过激活函数sigmoid得到的结果,σ1是x1经过sigmoid得到的结果,σ2是x2经过sigmoid得到的结果,σw是xw经过sigmoid得到的结果。对输入序列 x
t
中的每一项进行sigmoid激活,激活函数会将输入序列x
t
中的值变换到0到1之间。
[0106][0107]
在公式(29)中,其中s
t
是σ
t
经过正则化函数softmax得到的结果,s1是σ1经过softmax 得到的结果,s2是σ2经过softmax得到的结果,sw是σw经过softmax得到的结果。将公式 (28)中得到的σ
t
进行softmax正则化处理,softmax函数会将输入序列σ
t
中的值变换到0到 1之间,并且其值累加和为1。
[0108]
步骤4.2,将上面得到的空间注意力权重s
t
与输入序列x
t
进行哈达玛积操作,如公式(30):
[0109]
x
t
′
=s
t x
t
=[s1x1,s2x2,swxw]w×1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(30)
[0110]
在公式(30)中,x
t
′
为空间注意力权重s
t
与输入序列x
t
进行哈达玛积操作的结果,具体操作为对应序列的每一项相乘。
[0111]
步骤4.3,将带有空间注意力权重的输入序列x
t
′
输入到bilstm中,得到隐藏层状态数据,如公式(31):
[0112]ht
=[h1,h2,
…
,hw]w×sꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(31)
[0113]
在公式(31)中,h
t
为bilstm中的隐藏层状态输出,s为隐藏层神经元个数。
[0114]
步骤4.4构建时间注意力模块,将步骤4.3得到的隐藏层状态数据先经过relu函数激活,然后在正则化处理,得到时间注意力权重,如公式(32)-(33):
[0115]rt
=relu(h
t
)=max(0,h
t
)=[r1,r2,
…
,rw]w×1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(32)
[0116]
在公式(32)中,参数r
t
为h
t
激活后的结果,r1是h1经过relu得到的结果,r2是h2经过 relu得到的结果,rw是hw经过relu得到的结果。将隐藏层状态数据h
t
进行relu激活,relu 函数会将值变为非负数。
[0117][0118]
在公式(33)中,t
t
为r
t
的正则化处理结果,t1是r1正则化后的结果,t2是r2正则化得到的结果,tw是rw正则化得到的结果。对公式(32)得到r
t
进行正则化处理,得到时间注意力权重 t
t
。
[0119]
步骤5:将步骤2中预处理之后的数据按4:1的比例划分为训练集与测试集。用训练集数据训练步骤4中构建的时空注意力机制神经网络模型,用自适应矩估计(adaptive momentestimation,adam)优化算法寻找全局最优点,用变量控制方法选择超参数,损失函数为均方误差(mean square error,mse)。自适应矩估计优化算法通过使用动量和自适应学习率来加快收敛速度,不断优化神经网络模型。
[0120]
具体优化过程为将训练集数据输入到步骤4构建的时空注意力机制神经网络模型中训练,通过每次计算预测结果与训练集数据中的泊位入驻数之间的均方误差,用均方误差对模型参数求梯度,用自适应矩估计算法更新神经网络模型中的权重参数(wi、wf、wo、wc)、状态转移权重参数(ui、uf、uo、uc)、偏差参数(bi、bf、bo、bc)等。通过变量控制方法选择bilstm 隐藏神经元的个数(e_hidden)、学习率(learning_rate)和迭代次数(epochs)。通过多次迭代更新提高神经网络模型预测结果的准确性,并且每一次训练都根据均方误差调整神经网络模型的参数。当均方误差比较小且稳定时,确定迭代次数,使神经网络模型的预测更加高效和精确。训练完成后,得到优化后的神经网络模型。
[0121]
步骤6:在步骤5优化的时空注意力机制神经网络模型中运行测试集数据,统计并记录运行结果,得出泊位预测结果、空间注意力权重和时间注意力权重。
[0122]
在空间注意力模块,通过对输入序列进行sigmoid和softmax处理。由于sigmoid函数在连续函数空间稠密,可以将输入特征输出为0-1之间,并且数据在传递过程中不容易发散。 softmax则会计算出数据序列的概率,概率较大的值对预测结果影响也大。空间注意力权重变化会影响模型对输入数据的特征提取,经过空间注意力模块得到的空间注意力权重可以很好的捕获数据的变化趋势。当数据长度为18时,选取预测步为1、7、14、21、28、35作为输入数据序列,结合空间注意力权重的变化来分析可解释性。
[0123]
在时间注意力模块,通过对隐藏层数据进行relu和softmax处理。由于relu线性激活函数速度快,可能使神经元输出结果为0,这样就造成了神经网络的稀疏性,减少参数的相互依赖关系,缓解过拟合问题的发生。softmax则会计算出数据序列的概率,概率较大的值对预测结果影响也大。时间注意力权重变化会影响模型对泊位数据的预测结果。
[0124]
如公式(34)所示,将时间注意力权重t
t
和隐藏层状态数据h
t
进行矩阵相乘得到h
ij
。
[0125][0126]
在公式(34)中,t
t
表示时间注意力权重,h
t
表示隐藏层状态数据,h
ij
表示t
t
和h
t
矩阵相乘的结果,下标i,j表示第i行第j列。rs×1表示h
ij
是一个s维的矩阵。
[0127]
得到h
ij
之后,如公式(35)所示,h
ij
经过神经网络输出处理得到泊位预测结果,将h
ij
和截断正态分布得到的s维向量进行矩阵乘法。
[0128]
p=o(h
ij
),p∈r1×1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(35)
[0129]
在公式(35)中,p为h
ij
经过神经网络输出处理的结果,r1×1表示p是一个1维矩阵。p为预测结果。
[0130]
泊位预测结果和时间注意力权重的关系如公式(34)-(35)所示。从泊位预测理论上讲,时间注意力权重会随着输入泊位数据的变化而变化。通过有无时空注意力机制的时间注意力权重变化图对比来说明提出模型的有效性。
[0131]
通过空间注意力模块和时间注意力模块的权重捕获,可以实现对泊位数据的高精度预测。
[0132]
二、仿真实验
[0133]
在待预测停车场采集停车场泊位占有情况数据,如表1所示:
[0134]
表1停车场泊位占有数据
[0135][0136]
采集停车场泊位数据,每隔30min采集一次,occupancy为数据记录时刻的泊位入驻数。
[0137]
通过对采集数据进行数据清洗、特征提取和归一化处理等数据预处理措施,得到实验数据集。将数据集按照4:1划分为训练集和测试集,采集的数据集总量为1276,其中1020条数据为训练集,256条数据为测试集。
[0138]
构建基于双向长短期记忆神经网络bilstm的泊位预测模型,结构包括两条单向lstm。在此基础上构建时空注意力机制层捕获全局关键特征信息,结构包括空间注意力模块和时间注意力模块。通过变量控制方法选择bilstm隐藏神经元的个数(e_hidden)、学习率(learning_rate) 和迭代次数(epochs)。
[0139]
将数据集输入网络进行训练,固定隐藏神经元的个数(e_hidden)和学习率 (learning_rate),测试不同迭代次数(epochs)在bilstm泊位预测模型中rmse的变化情况。如图6所示,其中lstm变化曲线为bilstm神经网络模型没有时空注意力机制下测得数据, sta_lstm为bilstm神经网络模型加上时空注意力机制下测得数据。从图中可以看出,当epochs 为130时,均方根误差(root mean square error,rmse)最低,训练效果较好。其中均方根误差如公式(36)所示:
[0140][0141]
在公式(36)中,n为样本数量,yi为样本预测值,y为真实样本值。rmse是用来衡量
预测值和真实值之间的偏差,rmse越小代表模型的预测误差越小,模型的效果越好。
[0142]
固定迭代次数(epochs)和学习率(learning_rate),测试不同隐藏神经元的个数(e_hidden) 在bilstm泊位预测模型中rmse的变化情况。如图7所示,其中lstm变化曲线为bilstm神经网络模型没有时空注意力机制下测得数据,sta_lstm为bilstm神经网络模型加上时空注意力机制下测得数据。从图中可以看出,当e_hidden为128时,均方根误差最低,训练效果较好。
[0143]
固定隐藏神经元的个数(e_hidden)和迭代次数(epochs),测试学习率(learning_rate)在 bilstm泊位预测模型中rmse的变化情况。如图8所示,其中lstm变化曲线为bilstm神经网络模型没有时空注意力机制下测得数据,sta_lstm为bilstm神经网络模型加上时空注意力机制下测得数据。从图中可以看出,当learning_rate为0.001时,均方根误差最低,训练效果较好。
[0144]
在深度学习中,模型通过训练从训练集中学习所有样本的普遍规律,容易导致过拟合或欠拟合。通过增加模型训练迭代的次数,可以克服模型拟合不足的现象。通过增加数据集和引入形式化方法,可以克服过拟合现象。本发明采用神经单元的dropout,在训练过程中将按比例随机断开神经单元之间的连接,概率为0.5。
[0145]
将上面优化后的训练模型保存,然后读取测试集数据在训练模型运行,下面给出模型的预测结果,并给出加时空注意力机制和不加时空注意力机制的效果对比。
[0146]
实施例超参数为:预测步长为36、隐藏神经元的个数(e_hidden)为128、迭代次数(epochs) 为130、学习率(learning_rate)为0.001、dropout为0.5、数据长度(time_step)为18。在上面超参数确定情况下,训练bilstm神经网络模型达到较好的预测效果。然后将测试集数据输入模型中,即可得到预测结果。
[0147]
如表2所示,为有无时空注意力机制的预测效果对比,从表中可以看出,加上时空注意力机制的预测效果明显好于不加时空注意力机制的预测效果。在预测步长为36时,加上时空注意力机制的预测模型预测结果误差小于10的有33个,其预测结果平均误差为4.6;不加时空注意力机制的预测模型预测结果小于10的有26个,其预测结果平均误差为10.67。加时空注意力机制的预测结果如图9所示。
[0148]
表2有无时空注意力机制预测对比
[0149][0150][0151]
因此,本发明方法可以预测到未来36个目标步长的停车场泊位占有率情况,且可以保证预测结果较高的预测精度;模型预测结果的误差相对稳定,模型达到了很好的拟合效果。
[0152]
下面根据预测步为1、7、14、21、28、35时的数据序列以及预测值和真实值结合空间注意力权重变化具体分析。
[0153]
当预测步为1时,数据序列为:40 44 58 72 85 95 105 130 141 150 153 167 174 175168 164 159 150,真实值:49,预测值:46。
[0154]
从图10中的第一幅图可以看出,当预测步为1时,数据序列前四个数据40、44、58、72 的空间注意力权重较大,对预测结果的影响也越大。权重较大的数据序列与预测结果基本吻合。
[0155]
当预测步为7时,数据序列为:130 141 150 153 167 174 175 168 164 159 150 46 5671 84 89 116 134,真实值:151,预测值:146。
[0156]
从图10中的第二幅图可以看出,当预测步为7时,数据序列第一个数据130的空间注意力权重最大,对预测结果的影响也越大,预测结果为146。
[0157]
当预测步为14时,数据序列为:168 164 159 150 46 56 71 84 89 116 134 146 162180 191 191 185 173,真实值:177,预测值:175。
[0158]
从图10中的第三幅图可以看出,当预测步为14时,数据序列后三个数据191、185、173 的空间注意力权重较大,对预测结果的影响也越大。预测结果为175,误差为2。
[0159]
当预测步为21时,数据序列为:84 89 116 134 146 162 180 191 191 185 173 175 169168 166 55 60 75,真实值:75,预测值:80。
[0160]
从图10中的第四幅图可以看出,当预测步为21时,数据序列第16个数据55空间注意力权重较大,对预测结果的影响也越大。预测结果为80,误差为5。
[0161]
当预测步为28时,数据序列为:191 191 185 173 175 169 168 166 55 60 75 80 83101 111 140 152 160,真实值:170,预测值:173。
[0162]
从图10中的第五幅图可以看出,当预测步为28时,数据序列前三个数据191、191、185 的空间注意力权重较大,对预测结果的影响也越大。预测结果为173,误差为3。
[0163]
当预测步为35时,数据序列为:166 55 60 75 80 83 101 111 140 152 160 173 176171 165 149 141 126,真实值:111,预测值:115。
[0164]
从图10中的第六幅图可以看出,当预测步为35时,数据序列的第五个数据80和第九个数据140空间注意力权重较大,对预测结果的影响也越大。预测结果为115,误差为4。
[0165]
从上面分析可以看出空间注意力模块可以捕获输入序列的有效信息,达到较好的预测效果。
[0166]
由bilstm神经网络模型可以得到预测结果和时间注意力权重,具体的时间注意力权重如表3所示。
[0167]
表3时间注意力权重
[0168]
预测步长时间注意力权重预测步长时间注意力权重预测步长时间注意力权重10.90046465130.89176965250.8387200820.86617154140.89536774260.8466516130.83993518150.90152711270.8547081440.84633106160.9050622280.8611321450.8483004170.90600705290.8684852160.85123992180.90672338300.87479812
70.85662454190.90131193310.8809580880.86199999200.86308038320.8846104790.86963457210.8381806330.88824958100.87839156220.84075493340.89198482110.88378865230.83980519350.89123964120.88736379240.83798218360.88929909
[0169]
将上表中的时间注意力权重用图的形式展示更为直观,在图11中可以看出,时间注意力权重变化规律和图9的泊位预测结果变化规律大致符合,通过时间注意力权重变化对泊位预测结果进行解释。
[0170]
没有加时空注意力机制的神经网络模型,时间注意力权重变化如图12所示。其权重变化和泊位预测结果变化关系不是很明显。这也说明了时空注意力神经网络的有效性。
[0171]
本发明在长期预测中的预测精度和稳定性均比lstm模型有明显的提升。
[0172]
对于本领域的技术人员来说,可以根据以上的技术方案和构思,给出各种相应的改变和变形,而所有的这些改变和变形,都应该包括在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1