基于最小化压力差的深度强化学习交通信号协调优化控制方法
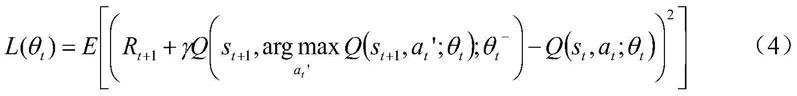
1.本发明涉及智能交通领域,特别是一种基于最小化压力差的深度强化学习交通信号协调优化控制方法。
背景技术:
2.随着城市化步伐的不断加快,城市道路拥堵现象已经成为一个严重的社会问题。交通信号智能控制系统在缓解交通拥堵方面发挥着重要的作用。随着人工智能的快速发展,自适应交通信号控制越来越受到研究人员的重视。目前的智能交通控制方法,比如模糊控制、进化算法、动态规划等方法,能够提升一定的城市通行效率,但其往往要对交通控制问题进行动力学建模,计算最优解的过程会消耗大量的时间且复杂度高,难以适用于实际的交通控制场景。而基于强化学习的交通控制方法可以避免复杂的交通建模,能够实时根据交通状态决策出最优的信号控制策略,并且能适用于各种复杂的交通场景,是目前自适应交通信号控制领域的研究重点。
3.强化学习交通信号控制的一个关键问题是如何定义状态、奖励和动作。现有的研究通常将奖励定义为其他几种交通状态的加权线性组合。而为了全面描述交通状况,一些方法使用复杂的状态定义,例如使用视觉图像来表示状态,这意味着需要更大的维度来表示状态,导致维度爆炸,复杂的状态定义会增加学习时间,并不会带来显著的效果。
技术实现要素:
4.本发明的目的在于提供一种基于最小化压力差的深度强化学习交通信号协调优化控制方法,包括以下步骤:
5.步骤s100,采集交叉口各条车道上的车辆位置信息和速度信息;
6.步骤s200,根据车辆位置信息和速度信息,基于深度强化学习交通信号控制模型得到下一时刻的动作;
7.步骤s300,根据动作信息,得到下一时刻交叉口信号灯的信号配时方案,选择保持当前相位或执行下一个信号相位;
8.步骤s400,执行信号配时方案,循环步骤s200~s400。
9.进一步地,步骤s100具体包括:
10.步骤s101,将每一条车道距离停车线一定距离范围内以固定长度间隔分成多个单元格;
11.步骤s102,获取每一单元格内车辆的位置向量和速度向量其中每一单元格内的位置向量的数值为对应单元格中车辆的数量,vi为车辆i的实际速度,v
max
为道路允许的最大速度;
12.步骤s103,所有单元格的位置向量和速度向量分别组成位置矩阵和速度矩阵。
13.进一步地,步骤s200基于深度双q网络模型获取下一时刻动作,所述深度双q网络模型,包括当前值网络和目标值网络,其中每一时刻t的当前值函数q(s
t
,a
t
;θ
t
)和目标值函数q(s
t
,a
t
;θ
t
—);其中s表示交通状态,由位置信息和速度信息构成,a表示动作,θ表示网络权重,当a
t
=0时,交叉口保持当前相位不变,当a
t
=1时,切换到相位序列中当前相位的下一个相位;步骤s200具体包括:
14.步骤s201,通过当前值网络计算得到最大q值所对应的动作a
t’,
[0015][0016]
其中a
t’为最优动作;
[0017]
步骤s202,根据a
t’,在目标值网络中计算目标q值y
tddqn
,对最优动作进行评估
[0018][0019]
其中,表示当前值网络在状态s
t+1
下输出的最大动作值所对应的动作;表示目标网络在状态s
t+1
下,根据在线网络选择的动作输出的动作值;γ表示折扣系数;r
t+1
表示在状态s
t
下执行动作后获得的奖励;
[0020]
步骤s203,通过最小化目标q值与当前q值之间的时间差分误差实现最优动作的拟合。
[0021]
进一步地,还包括基于深度双q网络模型对交通信号控制模型进行训练的过程,该过程包括以下步骤:
[0022]
步骤s501,利用仿真软件构建交通仿真环境;
[0023]
步骤s502,初始化算法参数,参数包括经验回放池m、抽样批量b、贪婪系数ε、折扣系数γ、学习率α、训练迭代步数t;
[0024]
步骤s503,从仿真软件中获取当前的车辆位置信息和速度信息,组成交通状态;
[0025]
步骤s504,将交通状态s
t
输入到当前值网络中,输出当前交通状态下所有执行动作a的q值q(s,a;θ),根据下式选择最优动作a’并执行
[0026][0027]
步骤s505,执行完动作后,根据奖励函数获得奖励r
t
,同时观测下一时刻状态s
t+1
,将当前交通状态和动作以及下一个时间段的交通状态和奖励值作为一个四元组《s
t
,a
t
,r
t
,s
t+1
》储存在经验缓冲池中;
[0028]
步骤s506,判断经验缓冲池中样本数量是否大于b;若是,通过经验优先级回放机制在经验缓冲池中选取数量为b的经验数据,通过下式计算损失函数l(θ),并通过梯度下降算法更新当前值网络参数θ;若否,跳转到步骤s503;
[0029][0030]
步骤s507,每隔c步,将当前值网络参数θ拷贝到目标值网络参数θ
—
,完成目标网络参数更新,即θ
—
=θ;
[0031]
步骤s508,当前交通状态s
t
更新为最新的交通状态
st+1
,即s
t
←st+1
;
[0032]
步骤s509,判断算法的迭代次数是否超过t;若否,则返回步骤s504进行;若是,则完成基于强化学习的交通信号控制模型的训练,得到训练好的交通信号控制模型。
[0033]
进一步地,步骤s300所述的相位包括σ={nsg,ewg,nslg,ewlg},其中σ为相位集合,nsg表示南北方向车道允许通行,ewg表示东西方向车道允许通行,nslg表示南北左转允许通行,ewlg表示东西左转允许通行。
[0034]
进一步地,相位按照nsg
→
nslg
→
ewg
→
ewlg的顺序变换。
[0035]
进一步地,还包括基于归一化压力算法获得奖励的过程,该过程具体为:
[0036]
步骤s601,构建归一化压力模型
[0037]
ρa=k
×
qa+ω
×
(qa)m[0038]
其中,ρa为车道上的归一化压力,qa为车道a上车辆的排队长度,m、和k为固定参数,ca为道路a上能承受的最大容量;
[0039]
步骤s602,获取车辆从车道a驶入车道b的压力差表示为ρ
(a,b)
[0040]
ρ
(a,b)
=ρ
a-ρb[0041]
其中,ρa和ρb分别为驶入车道a与驶出车道b上归一化压力;
[0042]
步骤s603,获取交叉路口i的压力pi;
[0043][0044]
其中,(a,b)∈σ表示(a,b)是相位集合σ={nsg,ewg,nslg,ewlg}中的一组相位运动;
[0045]
步骤s604,设置奖励函数
[0046]ri
=-pi。
[0047]
本发明与现有技术相比,具有以下优点:(1)通过将实时的交通信息进行离散化状态编码作为深度神经网络的输入,提升交通状态表示的准确度,也避免了因为状态空间较大导致的“维度灾难”问题;(2)采用交叉口各相位间交通压力差的和作为算法的奖励,压力的计算不仅考虑了道路上车辆的排队长度,还考虑了道路的容量问题;(3)通过深度双q学习网络模型在线学习交通信号的控制策略,解决了q值过估计问题,加快了算法收敛速度,实现交通信号的自适应控制;(4)该方法能够较好地实现相邻交叉口的协调控制,在区域路网间能更均匀地分配交通流,有效地减少车辆平均排队长度和平均行驶时间,较好地缓解交通路网交通拥堵。
附图说明
[0048]
图1为本发明的系统结构示意图。
[0049]
图2为本发明的方法流程示意图。
[0050]
图3为本发明的基于深度强化学习的交通信号控制模型训练流程图。
[0051]
图4为交叉路口模型示意图和四组相位运动图。
[0052]
图5为本发明的交通状态的矩阵表示图。
[0053]
图6为本发明的深度神经网络结构图。
[0054]
图7为本发明实施例中实际路网在sumo中仿真路网图。
[0055]
图8为本发明的模拟高峰流量场景实验的车流量变化情况图。
[0056]
图9为本发明的实施例中与其他方法的平均累计奖励值变化态势对比图,其中(a)是dql平均累计奖励值示意图,(b)是ddqn平均累计奖励值示意图,(c)是ddqn-mpd平均累计奖励值示意图。
[0057]
图10为本发明的实施例中与其他方法的性能对比曲线图,其中(a)为平均排队长度示意图,(b)为平均行驶速度示意图,(c)为交叉口平均延误示意图,(d)为平均行驶时间示意图。
具体实施方式
[0058]
将区域路网中每个控制节点作为一个智能体,每个智能体独立感知当前节点所在的环境的状态,共同参与协调优化全局的交通效率。智能体通过将实时的交通信息进行离散化状态编码作为深度神经网络的输入,提升交通状态表示的准确度,又能避免因为状态空间较大导致的“维度灾难”问题。使用深度双q网络作为网络模型,各个智能体在学习策略的过程中,使用交通压力差作为奖励的依据。压力差值表示的是交叉口上下游车道上车辆密度之间的不平衡程度。利用优先级经验采样策略选择小批量样本,以最小化压力差为目标对控制策略进行更新,从而实现对多路口交通的协调控制,提升路网的通行效率。
[0059]
结合图1,本实施例提供一种基于最小化压力差的多智能体深度强化学习交通信号协调优化控制系统。控制系统将区域路网中每个控制节点作为一个智能体,每个智能体均包括信息采集模块、学习及优化模块、控制决策模块、执行模块。
[0060]
信息采集模块:用于获取路口交通的交通状态,采集区域路网中各交叉口车道上车流数据信息;
[0061]
学习及优化模块:基于所述信息采集模块输入的当前时刻交叉口交通状态信息,通过交通信号控制模型选择最优动作,并输出结果;
[0062]
所述控制决策模块:用于接收学习及优化模块中选取的动作,转换成相对应的信号灯配时方案;
[0063]
执行模块:将信号灯的配时方案传输给交叉口的信号灯执行。
[0064]
结合图2,一种基于最小化压力差的深度强化学习交通信号协调优化控制方法,包括以下步骤:
[0065]
步骤s100,采集交叉口各条车道上的车辆位置信息和速度信息;
[0066]
步骤s200,根据车辆位置信息和速度信息,基于深度强化学习交通信号控制模型得到下一时刻的动作;
[0067]
步骤s300,根据动作信息,得到下一时刻交叉口信号灯的信号配时方案,选择保持当前相位或执行下一个信号相位;
[0068]
步骤s400,执行信号配时方案,循环步骤s200~s400。
[0069]
结合图4、图5,步骤s100中,将每一条车道距离停车线一定距离范围内以固定长度间隔分成多个单元格,每个单元格表示交叉口驶入车道上的车辆位置信息和车辆速度信息组成的二维向量,并将所有单元格进一步构成位置矩阵和速度矩阵来描述交通状态。其中,
位置矩阵的元素的数值为对应单元格中车辆的数量,如图5所示;根据道路限速值对车辆速度进行归一化得到与位置矩阵相对应的速度矩阵,其中速度矩阵中的元素计算方法如公式(1)所示
[0070][0071]
其中,vi为车辆i的实际速度,v
max
为道路允许的最大速度。
[0072]
步骤s200中,智能体获取到当前交叉口的交通状态后,会在动作空间中选取一个动作执行。智能体的动作集合a={1,0},在某一时刻t,交叉口的状态为s
t
,智能体根据状态选择当前时刻的动作a
t
∈a。当a
t
=0时,交叉口保持当前相位不变,当a
t
=1时,切换到相位序列中当前相位的下一个相位。本实施例中最短相位持续时间为δt=5s,相位发生切换时,绿灯切换至红灯间隙会有持续3s的黄灯,用于清空还未驶出交叉口的车辆。
[0073]
结合图6,步骤s200中,深度强化学习交通信号控制模型采用了深度双q网络模型(ddqn),具有当前值网络和目标值网络的双网络结构,当前值函数q(s,a;θ)与目标值函数q(s,a;θ
—
),其中,网络权重值分别为θ与θ
—
。当前值网络模型和目标值网络模型采用相同的网络结构,设计为两层卷积层加三层全连接层,其中s表示交通状态、a表示动作、q表示网络值参数。
[0074]
步骤s201,通过当前值网络计算得到最大q值所对应的动作a
t’,即:
[0075][0076]
其中,t表示时刻;
[0077]
步骤s202,在利用选择出来的动作,在目标值网络中去计算目标q值,对动作进行评估(对应的q值就是对动作的评估),即
[0078][0079]
其中,y
tddqn
表示ddqn中在线网络的目标值;表示当前值网络在状态s
t+1
下输出的最大动作值所对应的动作;表示目标网络在状态s
t+1
下,根据在线网络选择的动作输出的动作值;γ表示折扣系数;r
t+1
表示在状态s
t
下智能体执行动作后获得的奖励;
[0080]
步骤s203,为了使算法更加稳定,目标值网络不像当前值网络一样实时更新参数,而是每隔一定的时间步更新一次,利用这种方式使目标值网络与当前值网络具有较低的相关程度。最优值(即公式(2)获得的动作)的拟合通过最小化目标q值与当前q值之间的时间差分误差td-error来实现,结合两者计算出误差函数表示为:
[0081][0082]
在基于深度强化学习交通信号控制模型进行最优动作选择之前,先进行交通信号控制模型训练,结合图3,训练方法如下:
[0083]
步骤s501,构建交通仿真环境:根据目标道路交叉口的交通环境和交通流数据,配置交通仿真软件,建立与目标道路交叉口相似的交通仿真环境,如图7所示;
[0084]
步骤s502,初始化交通信号控制模型:初始化算法参数,参数包括经验回放池m、抽样批量b、贪婪系数ε、折扣系数γ、学习率α、训练迭代步数t;
[0085]
步骤s503,从仿真软件中获取当前的交通状态,根据模型状态定义方法生成车辆位置信息和速度信息组成的模型状态信息s
t
,所述状态信息包括车辆位置信息和速度信息,其获取方式同步骤s100;
[0086]
步骤s504,将状态s
t
输入到当前值网络中,输出当前交通状态下所有执行动作a的q值q(s,a;θ),根据公式(5)从动作空间中选择最优动作a’并执行
[0087][0088]
步骤s505,执行完动作后,根据奖励函数的定义获得奖励r
t
,同时观测下一时刻状态s
t+1
,将当前交通状态和动作以及下一个时间段的交通状态和奖励值作为一个四元组《s
t
,a
t
,r
t
,s
t+1
》储存在经验缓冲池中;
[0089]
步骤s506,判断经验缓冲池中样本数量是否大于b;若是,通过经验优先级回放机制在经验缓冲池中选取数量为b的经验数据,通过公式(6)计算损失函数l(θ),并通过梯度下降算法更新当前值网络参数θ;若否,跳转到步骤s503;
[0090][0091]
步骤s507,每隔c步,将当前值网络参数θ拷贝到目标值网络参数θ
—
,完成目标网络参数更新,即θ
—
=θ;
[0092]
步骤s508,当前交通状态s
t
更新为最新的交通状态
st+1
,即s
t
←st+1
;
[0093]
步骤s509,判断算法的迭代次数是否超过t;若否,则返回步骤s504进行;若是,则完成基于强化学习的交通信号控制模型的训练,得到训练好的交通信号控制模型;将训练好的交通信号控制模型应用到学习及优化模块中,以实际道路交叉口当前交通状态信息为输入,基于深度强化学习模型选择相应的动作。
[0094]
步骤s300中所述的相位包括nsg表示南北方向车道允许通行,ewg表示东西方向车道允许通行,nslg表示南北左转允许通行,ewlg表示东西左转允许通行。为了更加符合现实状况,相位的变化应该具有周期性,避免在不同相位之间无规律切换。在该交通信号控制中,相位周期集合如4所示,信号相位被定义为集合σ
[0095]
σ={nsg,ewg,nslg,ewlg}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0096]
相位按照nsg
→
nslg
→
ewg
→
ewlg的顺序变换。
[0097]
在动作执行后,需要反馈动作的结果好坏。算法的奖励函数是在智能体执行完动作以后,通过环境中状态的反馈得知该动作的好坏,奖励越大越好。本实施例定义了一种车道上交通流的压力计算方法,反映的是道路上交通流的密集程度,压力越小说明当前道路上车辆越少;将奖励定义为交叉口相位之间的压力差,能更加准确的反应出强化学习执行动作后的环境变化程度,使得算法能更快地向着最优策略收敛。本实施例提出了一种归一化压力的计算方法,将交叉口所有相位间压力差的和作为将算法奖励。压力表示的是道路上交通流的密度,压力差值表示的是交叉口上下游车道上车辆密度之间的不平衡程度,差
值越大,车辆分布越不平衡。本发明采用如下归一化压力的计算方法。归一化压力公式为:
[0098]
ρa=k
×
qa+ω
×
(qa)mꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0099]
其中,ρa为车道上的归一化压力,qa为车道a上车辆的排队长度,m、ω和k为参数。在公式(3)中,归一化压力差公式由两部分组成,当排队长度较小时,压力的增长是由k
×
qa决定的,确保在qa值较小时曲线是线性的。随着排队长度的增加,压力的增长是ω
×
(qa)m决定的。确保在qa值较大时曲线呈指数增长。
[0100]
归一化压力值的范围在[0,1]区间内,0表示没有车辆排队,压力值为0。当排队长度达到道路最大容量时,压力值等于1,这意味着道路不能从上游道路接收车辆。假设ca为道路a上能承受的最大容量,当qa=ca时,道路的压力达到最大值ρa=1,即
[0101][0102]
将公式(9)代入公式(8)得到参数ω为
[0103][0104]
将公式(10)代入公式(8)可得
[0105][0106]
在交叉口中,一个相位交通流压力差定义为驶入车道和驶出车道之间的归一化压力差值。将车辆从车道a驶入车道b的压力差表示为ρ
(a,b)
[0107]
ρ
(a,b)
=ρ
a-ρbꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0108]
ρa和ρb分别为驶入车道a与驶出车道b上归一化压力。其中(a,b)∈σ表示(a,b)是相位集合σ={nsg,ewg,nslg,ewlg}中的一组相位运动。交叉口i的压力为四种相位运动的压力差之和,表示为
[0109][0110]
选择交叉口的压力作为强化学习算法的奖励,奖励函数如下式所示,奖励值越大,表示交叉口的压力之和越小
[0111]ri
=-piꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0112]
结合图8~图10,对本发明的实施例进行仿真实验与分析。
[0113]
仿真实验采用sumo交通仿真平台。采用交通仿真中的traci(traffic control interface)模块,通过python语言实现算法与sumo在线交互,获取实时的交通状态,并执行调节信号的控制动作。如图5所示,使用openstreetmap选取某实际道路路网作为仿真实验研究对象,使用sumo的netedit生成区域交通路网模型,包括29个红绿灯控制的交叉口。
[0114]
在模拟器运行过程中,每个时间步会产生一定数量的车辆,并在路网中随机分布。每一辆新生成的车辆都会按照一定的规则随机生成一条路线,车辆会沿着这条路线行驶,最终在到达目的地时将车辆从路网中移除。为了实现对真实交通情况的仿真,本文引入了可变流量的设定,模仿现实高峰交通流场景,流量变化如图8所示,横轴表示时间,时间长度固定3600秒,纵轴表示产生的车辆数。在单位训练周期内车流量会存在一个明显的高峰期
和低谷期,流量变化由小变大到达高峰,维持一定的高峰流量之后逐渐变小。
[0115]
实验一:基于深度q学习的交通信号控制方法。该方法不考虑相邻路口交通状况,使用排队长度作为强化学习的状态和奖励的定义,表示为dql。
[0116]
实验二:采用深度双q网络作为算法的模型,使用排队长度作为状态的定义,将上下游车道上车辆数量之间的差值作为强化学习的奖励,该方法假设道路的容量是无限大的,没有考虑道路的容量问题,表示为ddqn。
[0117]
实验三:本发明所提出的方法,采用深度双q网络作为算法的模型,使用各路口各相位间压力差的和作为强化学习的奖励,压力的计算不仅考虑了道路上车辆的排队长度,还考虑了道路的容量问题,表示为ddqn-mpd(minimize pressure difference traffic signal control based on deep reinforcement learning)。
[0118]
在相同仿真环境下对三种基于深度强化学习交通信号控制模型进行训练,在训练阶段,仿真实验的训练总步数106时间步,仿真实验共执行1400个迭代回合。每个迭代回合的仿真步数为720步。将实验得到的数据分别用散点进行绘制,如图9所示,横轴表示训练的步数,纵轴表示每个训练集的平均累计奖励值,平均奖励值越大,表明算法的表现越好。由图可知,dql由于采用深度q学习网络模型,使用排队长度作为状态和奖励的定义,简单的定义导致算法没有学到有效的控制策略。ddqn-mpd和ddqn算法,在初始的学习阶段中缺乏经验样本,所以往往会选择随机动作策略,从而导致算法总是获得较低的奖励值。而随着训练回合数逐渐增加,算法通过大量经验样本的训练,算法的平均奖励值也因此不断升高,最终趋于收敛状态,算法学习到了有效的交通协调控制策略。相较于ddqn,ddqn-mpd算法的收敛速度更快,平均奖励值的离散程度更低,说明在训练后期有较好的收敛性和稳定性。
[0119]
仿真实验阶段,在相同的实验场景下分别对三种方法进行了10次仿真实验,并将三种方法的实验结果进行汇总,得到了如表1所示的对比结果。
[0120]
表1:三组实验仿真结果
[0121][0122]
表1总结了在评估中比较的关键指标的平均值,由表1可知,本发明提出的基于最小化压力差的多智能体深度强化学习交通信号协调优化控制表现是最好的。相对于实验二,平均行驶时间减少了18.6%,平均行驶速度提升了18.3%,平均延误时间减少了27.4%,平均排队长度减少了35.6%,交叉口车辆的平均延误降低了28.4%。实验表明本发明提出的方法能够更好缓解交通拥堵,提高交通效率。
[0123]
如图10所示,将10次仿真实验得到的数据分别用不同颜色进行绘制,然后分别对每个训练回合中10次实验的数据求平均,得到了平均数据变化曲线图,实线部分为10次测试结果的平均值,阴影部分为对10次实验数据求标准差,根据标准差得到了数据的离散区间。仿真实验模拟高峰流量的状况,随着车流量的增加,道路负载与通行压力会越来越大。由图可知,由于在训练阶段dql算法模型没有收敛,路口智能体不能根据交通状态得到有效
的控制策略,导致区域交通一直处于拥堵状态。ddqn交通流量在到达高峰后,平均行驶速度和平均行驶时间一直在恶化,交叉口平均延误一直增加,说明该算法不能较好地实现对高峰流量下的交通信号的协调控制。ddqn-mpd在三种控制算法中具有最好的效果,能够较好地实现相邻交叉口的协调控制,在区域路网间能更均匀地分配交通流,有效地减少车辆平均排队长度和平均行驶时间,较好地缓解高峰时段的交通拥堵。
[0124]
通过以上实施例,本发明提出的基于归一化压力差的深度强化学习的交通信号协调优化控制方法,与2种度强化学习算法相比,其在交通信号的控制中也能得到更好的效果,有效缓解交通压力,提升交通效率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1