一种基于离线强化学习的交叉口车辆轨迹优化方法、系统
本发明属于车路协同智能交通道路控制,尤其涉及基于离线强化学习的交叉口车辆轨迹优化方法、系统。
背景技术:
1、随着城市交通需求逐年增长,城市道路正在承受严重的交通拥堵,而拥堵又加重了能源消耗和环境恶化。交叉口是城市道路交通网络管控的瓶颈所在,改善主干道交叉口处的车辆管控对交通系统的效率有重要的作用。
2、传统的交通控制策略包括定时信号控制、自适应信号控制以及车辆驱动控制等。定时信号控制使用历史交通数据标定预先设施的信号灯参数,包括相位序列、周期长度和绿灯时长。车辆驱动和自适应信号控制将基础设施中的探测设备应用于实时交通数据收集并且根据时变的交通需求调整信号灯时长。
3、随着网联cav(connected and autonomous vehicle,自动驾驶车)技术的发展,v2v(vehicle-to-vehicle,车车)通信与v2i(vehicle-to-infrastructure,车路)通信为交通管控提供了全新的数据集。这种双边通信实现了将交通信息实时传递给车辆并优化轨迹,同时可以收集精确的车辆轨迹数据。实时数据通信可以通过将轨迹数据传输给信号灯,实现信号相位和配时的优化;也可以假定信号相位与配时固定,通过控制车辆速度或加速度将信号灯数据用于车辆行驶轨迹的优化,从而减少能源消耗,车辆排放和延误,提升车辆的安全性。通常优化控制问题将车辆位置与速度视作状态变量,将加速度视作控制变量。但是在复杂的约束条件与多目标状况下,优化控制方法的计算复杂度较高。一种方法是将时间和状态空间离散化,将问题转化为多阶段决策问题,另一种方法是将车辆轨迹划分为具有连续加速的不同的部分,从而缓解计算压力。
4、与此同时,基于drl(deep reinforcement learning,深度强化学习)的交叉口控制方法也提供了解决上述困境的新思路。将车辆或信号灯作为强化学习的智能体,智能体根据自身动作和交叉口状态变化不断更新策略,选择回报最高的动作,从而优化交叉口的节能控制。但在在线强化学习中,智能体在训练过程中需要不断与环境进行交互,根据最新的反馈数据更新策略并选择动作。由于在线学习过程中,智能体尚未成熟时可能会选择危险动作导致交通事故,同时,实时策略的更新对计算复杂度与速度要求较高,可能导致策略更新不及时。因此,考虑离线强化学习方法,将已有的交叉口车辆轨迹数据用于智能体训练,车辆智能体只需根据当前状态从形成的策略空间中选择最优的策略控制交叉口车辆。该方法压缩了计算复杂度,优化车辆轨迹,实现节能减排,安全性与效率的提升。
技术实现思路
1、本发明所要解决的技术问题是:一种基于离线强化学习的交叉口车辆轨迹优化方法,在智能网联环境下收集交叉口车辆通行轨迹数据与信号相位数据,构建用于训练车辆控制策略的静态数据集;在信号灯与网联车辆的通信范围内,车辆智能体采用由构建的数据集训练的交叉口通行策略提供的最优通行轨迹,优化交叉口车辆控制。
2、本发明为解决上述技术问题采用以下技术方案:
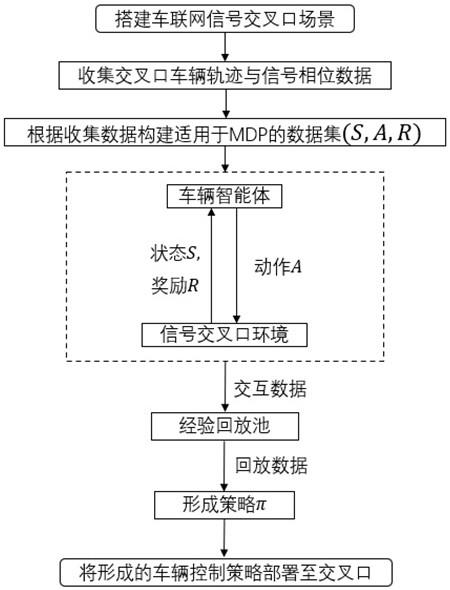
3、本发明提出的一种基于离线强化学习的交叉口车辆轨迹优化方法,包括如下步骤:
4、s1、搭建智能网联环境下交叉口信号灯与网联车辆的通信场景,根据交叉口之间的距离,设定车辆与信号灯的通信距离阈值,一般为100到300米范围,当车辆进入信号灯的控制范围时,双方可进行信息交互。
5、s2、收集信号交叉口网联车辆的运行数据和信号灯的spat(signal phase andtiming,相位与配时)信息,构建静态数据集。
6、s3、将车辆在交叉口的行驶过程模拟成马尔科夫决策过程,在步骤s2构建的静态数据集中以离线状态通过强化学习方法训练车辆智能体,得到适用的交叉口通行策略。
7、s4、将训练后的策略应用于交叉口的车辆控制,根据观察到的环境状态数据选定最合适的加速度,通过控制车辆加速度使车辆按照最优化的轨迹运行。
8、进一步,步骤s1中,搭建智能网联环境下交叉口信号灯与网联车辆的通信场景的具体过程为:在智能网联交通环境下,基于v2i通信,道路设施与网联车辆通过通信设备交换车辆运行轨迹和信号灯spat信息;比较在不同通信距离阈值下的车辆运行结果,选出合适的通信距离阈值rc,当信号灯与车辆距离小于rc时,车辆位于通信区域内,能够根据网联交叉口系统提供的策略行进,此时的通信范围是以信号交叉口为圆心,以rc为半径的圆形区域;否则,车辆将按照自身的跟驰行为行进。
9、进一步,步骤s2的具体过程如下:根据步骤s1中搭建的信号交叉口通信场景,收集的车辆运行数据,包括车辆到交叉口停止线的距离、速度、加速度、绿灯剩余时间的信息。
10、进一步,步骤s3中,将车辆运行行为抽象为具有马尔科夫性质的决策过程,则某一时刻的交叉口车辆状态只取决于上一时刻的状态与车辆行为,且该决策过程是随时间不断行进的,将车辆作为智能体,在智能体与环境状态之间存在一个不断交互的过程。离线强化学习实现在智能体不与环境进行交互的前提下,仅根据收集的数据集,通过强化学习算法得到适用的策略。离线强化学习可以避免智能体与环境交互过程中产生的危险或是统计智能体回报导致的延误。具体步骤如下:
11、s301、将车辆通过交叉口的行驶过程模拟成马尔科夫决策过程,马尔科夫决策具体过程用五元组(s,a,r,p,γ)来描述,其中:s和a为环境状态和智能体动作的集合;r为奖励函数,奖励可以取决于环境状态和智能体动作或只取决于状态;p是状态转移函数,表示在某状态下执行某动作后到达另一状态的概率;γ是折扣因子,用于衡量当前奖励与未来长期回报的相对重要性。
12、s302、将网联车辆作为智能体,通过四维向量定义状态s,具体公式为:
13、st=[dr(t),vr(t),φ(t),g(t)]t;
14、其中,dr(t)代表车辆所处的位置;vr(t)代表车辆速度,由网联车辆提供;φ(t)代表绿灯剩余时间,若车辆行进方向处于红灯状态,φ(t)值为0;g(t)为红灯剩余时间,由v2i通信传输的spat信息提供。
15、s303、智能体动作a表示为车辆的加速度控制,即加速度限值at∈[dm,um范围内的连续动作空间;其中dm为加速度的下限值,um为加速度的上限值。除了加速度限值外,加速度还满足车辆的安全性要求,即避免追尾或超出限速值范围。
16、s304、定义奖励函数r,为了提高车辆的安全性能,需控制车辆在交叉口行动轨迹,改善车辆在交叉口处的拥挤和停车-启动行为,进而提升通行效率,降低车辆能耗。因此考虑车辆通过交叉口的时长、车辆通过交叉口的能量消耗以及ttc(time-to-collision,碰撞时间)作为奖励函数的指标。ttc表示前车与后车保持当前速度差时,后车追上前车发生碰撞需要的时间:
17、
18、其中,ttci(t)表示第i辆车在第t秒的碰撞时间,xi表示第i辆车的位置,vi表示第i辆车的速度,l表示i车前车的车身长度;考虑集计的车辆旅行时长难以将奖励分配到每个时间步从而为瞬时的车辆动作进行决策,因此定义奖励函数:
19、rt=ω1(x(t)-x(t-1))+ω2f(t)+ω3ttci(t)
20、其中,x(t)-x(t-1)表示单个时间步内车辆的运动距离,f(t)表示车辆的瞬时油耗,ω1表示单个时间步内通行距离的权重,ω2表示车辆油耗的权重,ω3表示ttc在奖励函数中的权重。
21、s305、由于信号交叉口场景的复杂性,环境的状态转移概率难以求出,因此基于无模型的强化学习方法定义状态转移函数p;为实现对车辆的最优控制,车辆通过对静态数据集进行学习得到最佳策略π*,实现期望回报最大化:
22、
23、其中,θ表示策略空间;根据前述的环境状态、智能体动作与奖励定义,通过车辆的轨迹数据与信号灯历史数据计算得到。
24、s306、折扣因子γ用于衡量当前奖励与未来长期回报的相对重要性,取值范围为[0,1),接近1的γ更关注长期的累积奖励,接近0的γ更重视短期奖励。从时刻到终止状态时,所有奖励的衰减总和为回报:
25、
26、s307、使用cql(conservative q-learning,保守q-learning)离线强化学习算法消除部分外推误差q值为给定策略π下的状态价值函数:
27、
28、s308、为了避免q值的过高估计,cql对某些状态上的高q值进行惩罚,在训练次数范围内,每一步都需更新熵正则系数α,具体公式为:
29、
30、s309、更新函数q,具体公式为:
31、
32、其中,为实际计算时策略π的贝尔曼算子。
33、s310、更新策略πφ,得到最终适用该交叉口车辆控制的策略,具体公式为:
34、
35、进一步,步骤s4中,使车辆按照最优化的轨迹运行的具体过程为:将网联车辆作为智能体部署到交叉口环境,在每个离散步内,车辆根据步骤s3中提出的策略从动作空间中选择相应的动作,通过控制车辆的加速度使车辆按照策略提供的最优化轨迹运行,从而减少车辆能耗,提高车辆通行效率和安全性能。
36、进一步,本发明还提出一种基于离线强化学习的交叉口车辆轨迹优化系统,包括:
37、智能网联下的通信场景模块,用于在交叉口处当车辆进入信号灯的控制范围时,车辆与信号灯可进行信息交互。
38、数据集模块,用于构建车辆运行轨迹和信号灯spat信息的数据集,包括车辆到交叉口停止线的距离、速度、加速度、绿灯剩余时间的信息。
39、马尔科夫决策模块,用于将车辆在交叉口的行驶过程模拟成马尔科夫决策过程。
40、交叉口通行策略模块,用于在离线状态下通过强化学习方法训练车辆智能体,得到适用的交叉口通行策略。
41、车辆控制模块,用于通过控制车辆加速度使车辆按照最优化的轨迹运行。
42、进一步,本发明还提出一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现前文所述的基于离线强化学习的交叉口车辆轨迹优化方法的步骤。
43、进一步,本发明还提出一种计算机可读的存储介质,所述计算机可读的存储介质存储有计算机程序,所述计算机程序被处理器运行时执行前文所述的基于离线强化学习的交叉口车辆轨迹优化方法的步骤。
44、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
45、1、本发明采用的离线强化学习方法将已有的交叉口车辆轨迹数据用于智能体训练,车辆智能体只需根据当前状态从形成的策略空间中选择最优的策略控制交叉口车辆,避免车辆智能体在初始训练阶段横冲直撞可能造成的事故,提升了安全性能。
46、2、本发明利用离线强化学习方法训练车辆智能体,计算复杂度较低,避免了智能体与环境的数据交互造成时间消耗导致的策略更新不及时,提升了车路协同系统向车辆提供控制策略的效率。
47、3、本发明提供的离线强化学习方法,将车辆旅行时间、车辆能耗、ttc作为奖励函数的参数,联合优化了车辆的经济性和安全性能,可以缓解城市交叉口由于拥堵导致的交通延误和碳排放,实现了城市交叉口系统运行效率的提升和节能减排。
- 还没有人留言评论。精彩留言会获得点赞!