基于卡口对路网构建与速度重构的出行链划分方法和系统
本发明涉及车牌识别,特别涉及一种基于卡口对路网构建与速度重构的出行链划分方法和系统。
背景技术:
1、自动车牌识别(automatic number plate recognition,anpr)技术通过道路上固定的激光或摄像机等传感器,获取路网中车辆的出行记录,具有样本量大,采集精度高和持续时间长等优势,但受到卡口颗粒度大,直接提取轨迹空间的分辨率低,出行链难以精确划分等限制,常用于交通流分布、流量统计、od预测等宏观交通特性分析。目前,一部分学者也将其应用于微观交通特性分析,如出行轨迹、出行结构、路径行为选择等。故如何基于anpr数据对出行链进行精确划分十分必要。
2、基于自动车牌识别数据进行出行链划分一般流程如下:
3、(1)数据预处理:对缺失值和异常值进行处理,通常采用直接删除或者进行插补进行处理。
4、(2)原始出行链提取:将预处理后的数据按车牌号码和时间先后顺序进行排序,得到原始出行链。
5、(3)构建路网结构:根据卡口信息进行路网的构建。
6、(4)出行链划分:选定划分出行链所需求的特征,并根据特征设置阈值,再依阈值进行筛选后打断出行链。
7、现有技术中在构建路网结构时,由于anpr设备布设时颗粒度大等原因,难以建立真实完整的路网参数。目前较多的处理方式是根据真实路网拓扑结构,设置虚拟点位。但该方法需要道路空间数据作为支撑,实现较为复杂,操作相对繁琐,当卡口点位较多,且道路结构复杂时,很难实现路网参数的构建。
8、关于出行链划分时的阈值选择,主要考虑的特征时间或者速度。但是以时间作为阈值时完全忽略了空间分布影响,故更多选取速度作为特征。在采用速度作为特征时,现有技术通常直接依据行程距离以及行程时间计算出速度再设置阈值标准进行划分。但是在计算车辆行驶速度时,统计车辆行驶速度往往受到极大值与极小值的影响,分布往往是偏态分布,这将导致最终结构误差较大。在采用速度作为特征时,由于其受行程时间的影响很大,难以保障行程时间的可靠性。
技术实现思路
1、本发明针对现有技术的缺陷,提供了一种基于卡口对路网构建与速度重构的出行链划分方法和系统。通过寻找交通网络中直接相邻关系的任意两个卡口形成邻近卡口对,再依据卡口对的经纬度坐标直接换算成为卡口对间距离,即可构建完整的卡口路网。采取一种基于异常值数据表现以及行程时间分布特征的异常值提取方法,对异常的行程时间数据进行快速准确的筛除,保障行程时间的可靠性。采用引入超参数的box-cox方法矫正速度数据,减小结构误差。
2、为了实现以上发明目的,本发明采取的技术方案如下:
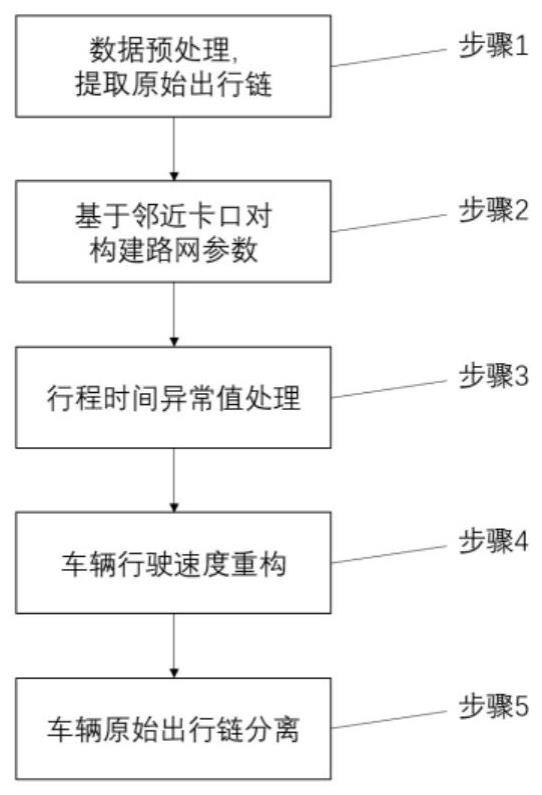
3、一种基于卡口对路网构建与速度重构的出行链划分方法,包括以下步骤:
4、步骤1:数据预处理,对原始数据进行筛选和清洗,去除污损数据,污损数据包括:车牌号码识别为"污损车牌"或号牌种类为"99"的数据,然后按照车辆号牌号码与行程时间先后进行排序,提取原始出行链。
5、步骤2:根据原始出行链数据,提取邻近卡口对信息。邻近卡口对指的是交通网中具有直接相邻关系的任意两个卡口。通过将前后两个邻近卡口看作一次出行的起始点(o点)和终止点(d点),同一车牌号码对应的前后两条卡口数据即为一对邻近卡口对。
6、步骤3:处理行程时间异常值;
7、将速度作为划分出行链的阈值。行程时间是指相邻两次卡口数据采集时间的差值。对行程时间进行异常值处理,包括过短和过长的行程时间。造成行程时间过短的原因包括:车牌误检、超速和存在套牌车辆。造成行程时间过长的原因包括:检测设备间存在停驻点、行驶速度过低、设备漏检和误检。进行异常值提取和筛除。
8、步骤4:车辆行驶速度重构;
9、在构建路网参数和筛除异常行程时间后,计算车辆的行驶速度。对行驶速度进行正态化处理。
10、步骤5:车辆原始出行链分离,具体如下:
11、step1:出行链初始化;
12、将原始的出行链进行划分处理,形成每辆车的初始出行链。
13、step2:计算时间间隔;
14、根据出行链的节点信息,计算每个节点之间的时间间隔。
15、step3:计算平均速度;
16、根据出行链的节点距离和时间间隔,计算每个节点之间的平均速度。
17、step4:计算速度标准差;
18、根据每辆车的平均速度,计算其经过路段速度的标准差。
19、step5:确定速度阈值;
20、根据计算得到的平均速度和速度标准差,确定速度阈值的下限和上限。速度阈值的下限表示车辆速度过低的阈值,速度阈值的上限表示车辆速度过高的阈值。
21、step6:出行链分离;
22、根据确定的速度阈值,对出行链进行分离。如果某个节点的速度超过速度阈值的上限或低于下限,则将该节点作为划分点,将出行链分为多个子链。子链表示车辆在行驶过程中的不同路段或路径。
23、进一步地,步骤2中,提取出邻近卡口对采用时空信息上移的方法。具体如下:定义邻近卡口对中的o点的经纬度坐标分别为lono,lato,d点的经纬度坐标分别为lono,latd。赤道圆的平均半径r为6,371,004m。根据三角函数公式求得两点间距离,距离d的公式如下:
24、d=arccos(sin(lato)×sin(latd)+cos(lato)×cos(latd)×cos(lono-lond))×r
25、式中,r为6,371,004m,经纬度坐标均采用弧度制。
26、进一步地,步骤3中,异常值提取具体步骤如下:
27、step1:根据实际数据情况,选择合适的时间窗大小,一般取1min至30min。时间窗是指在一定时间范围内进行异常值检测和处理的窗口。
28、step2:根据实际数据情况和研究要求,设置行程时间的上下限阈值。行程时间小于下限阈值或大于上限阈值的数据将被认为是异常值。
29、step3:均方差检测。选择第i个时间窗内的行程时间ti构成行程时间选择样本集tdsi,筛选掉tdsi中均值和三倍均方差范围之外的数据,并将筛选后的样本集合按从小到大的顺序排序,即max(j)为时间窗i内最大的序号,得到样本集tds′i,tds′i用公式表示如下:
30、
31、step4:根据中位数平均绝对偏差值进行时间滤波。计算出tds′i样本中位数以中位数对tds′i中数据进行划分,分别计算前后子集中行程时间与中位数的绝对偏差和计算公式如下:
32、
33、得到两个绝对偏差后,筛掉中位数分别与3倍前后绝对偏差之和范围外的行程时间值,即:
34、
35、得到筛选后的样本集t″i。
36、step5:重复step4直至各参数统计量趋于稳定。
37、重复进行step4,计算新的中位数和绝对偏差,然后进行时间滤波,得到新的样本集t″i。重复这个过程,直到样本集t″i的均值和标准差等参数统计量趋于稳定。
38、进一步地,步骤4:对行驶速度进行正态化处理,使用box-cox变换进行正态化处理,具体如下:
39、
40、其中,y为原始的行驶速度数据,λ为超参数,c为修正参数。通过调整λ和c的值,可以将数据进行合适的正态化处理。
41、进一步地,步骤5的具体步骤如下:
42、step1:出行链初始化。将原始出行链进行划分处理,形成第i辆车初始出行链为根据建立的路网参数可得li间的出行距离为
43、step2:计算时间间隔。将li相邻时间做差得两点之间时间间隔为其中j=1,2,...,n。
44、step3:计算平均速度。计算出行链li路段相邻节点间的平均速度,计算公式为:
45、
46、并滚动计算已经过路段的平均速度,计算公式为:
47、
48、step4:计算速度标准差。计算第i辆车经过路段速度的标准差,计算公式为:
49、
50、step5:确定速度阈值。假设当前判别点位为出行链的第n个点,则另速度阈值下限为:
51、
52、速度阈值上限为
53、
54、其中λ是调整参数。
55、step6:出行链分离。根据确定的阈值即可对出行链进行划分。
56、本发明还公开了一种基于卡口对路网构建与速度重构的出行链划分系统,该系统能够用于实施上述的出行链划分方法,具体的,包括:
57、数据预处理模块,功能如下:
58、数据筛选与清洗:去除污损数据。
59、数据排序与提取:按照车辆号牌号码与行程时间先后进行排序,提取原始出行链数据。
60、邻近卡口对提取模块,功能如下:
61、邻近卡口对识别:将前后两个邻近卡口看作一次出行的起始点和终止点,同一车牌号码对应的前后两条卡口数据即为一对邻近卡口对。
62、异常行程时间处理模块,功能如下:
63、异常值提取:识别过短和过长的行程时间,包括车牌误检、超速、套牌车辆、检测设备间存在停驻点、行驶速度过低、设备漏检和误检等异常情况。
64、异常值筛除:对异常行程时间进行筛除,以确保数据的准确性和可靠性。
65、车辆行驶速度重构模块,功能如下:
66、路网参数构建:基于卡口对信息和筛除异常行程时间后,构建路网参数。
67、行驶速度计算:根据路网参数和行程时间计算车辆的行驶速度。
68、速度正态化处理:对行驶速度进行正态化处理,以保证数据的可比性和统一性。
69、出行链分离模块,功能如下::
70、出行链初始化:将原始的出行链进行划分处理,形成每辆车的初始出行链。
71、时间间隔计算:根据出行链的节点信息,计算每个节点之间的时间间隔。
72、平均速度计算:根据出行链的节点距离和时间间隔,计算每个节点之间的平均速度。
73、速度标准差计算:根据每辆车的平均速度,计算其经过路段速度的标准差。
74、速度阈值确定:根据计算得到的平均速度和速度标准差,确定速度阈值的下限和上限。
75、出行链分离:根据确定的速度阈值,对出行链进行分离,将速度超过阈值的节点作为划分点,将出行链分为多个子链。
76、本发明还公开了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述出行链划分方法。
77、本发明还公开了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述出行链划分方法。
78、与现有技术相比,本发明的优点在于:
79、1.路网结构与参数建立的便捷性:本发明利用邻近卡口对信息建立路网结构与参数,通过直接近似计算两点之间的距离,避免了复杂路网结构和大量数据量导致的路网参数难以建立的问题。这种便捷性使得系统能够快速构建准确的路网结构,为后续的出行链划分提供了可靠的基础。
80、2.异常值处理和正态化处理的准确性:本发明采用一种基于异常数据值表现和行程时间分布特征的异常值提取方法,能够有效识别和提取出行程时间的异常值。同时,通过box-cox方法对偏态速度数据进行矫正,实现了行程时间的正态化处理。这种准确性保证了数据的可靠性和可比性。
81、3.出行轨迹提取的高效性和准确性:针对原始出行链包含多次出行的问题,本发明在过滤后的样本数据基础上设计了出行链分离算法。该算法能够高效而准确地提取实际出行轨迹,避免了多次出行的混淆和误判,提高了出行链划分的准确性。
82、4.数据可比性:利用速度正态化处理模块对行驶速度进行处理,使得不同车辆的速度可以进行比较和统一,提高了数据的可比性。
83、5.出行链划分精度:出行链分离模块,本发明根据平均速度、速度标准差和速度阈值等参数对出行链进行精确划分,可以有效区分不同的出行链,提高了出行链划分的精度。
- 还没有人留言评论。精彩留言会获得点赞!