一种双向模型迁移的多主体联合强化学习方法
本发明涉及智能交通信号规划,具体地说,涉及使用强化学习、迁移学习技术的一种面向多主体联合强化学习的双向模型迁移技术和面向多点投毒攻击的区域通行效率优化方法。
背景技术:
1、基于模型的迁移方法(model based transfer learning)是指从源域和目标域中找到他们之间共享的参数信息,以实现迁移的方法。这种迁移方式要求的假设条件是:源域中的数据与目标域中的数据可以共享一些模型的参数。迁移学习可以利用源领域数据中的知识,提供目标领域数据中的学习初始点,加快网络收敛速度。迁移学习还可以提高模型的适应性和鲁棒性。
2、强化学习(reinforcement learning,rl)主要用于解决序贯决策问题,其核心思路是智能体在与环境的持续交互中进行试错学习,即根据环境反馈学习最佳策略,使得智能体从环境中获取的累积回报达到最大。多智能体强化学习(multi-agent reinforcementlearning,marl)是强化学习研究的一个重要分支,旨在让多个智能体在特定环境中通过合作与竞争的方法来实现共同目标。与传统的单智能体强化学习相比,marl具有多项优势:能够更好地模拟现实世界的复杂环境,解决涉及多个参与者的问题,并提高系统的鲁棒性、学习效率、自适应与可扩展性。
3、智能交通信号灯系统(intelligent traffic signal system,isig)是一个提升交通运行效率的智能系统。美国交通部usdot于2016年开始试点在纽约市、坦帕(佛罗里达州)、夏延(怀俄明州)、坦普尔(亚利桑那州)和帕洛阿尔托(加利福尼亚州)等城市街道部署isig系统,实际可以降低26.6%的车辆通行延时。中国交通部依托滴滴出行于2018年在山东省济南的344个道路交叉口试点智能交通信号灯系统,实际可以降低10%-20%的车辆通行延时。
4、相位控制优化(controlled optimization of phases,cop)算法是isig系统中的核心信号规划算法,应用于单个交叉口车辆延迟的优化。cop算法基于动态规划算法,是一种求解最优决策问题的递归方法。在此基础上,cop算法优化了一个由相位序列和相应的持续时间组成的信号规划,能够根据交叉口实时自适应修改红绿灯相位顺序和持续时间。
5、isig数据投毒攻击指通过攻击传感器,造成传感器工作异常甚至失效,进而通过对污染数据加工利用,形成对isig系统的直接或者间接攻击,这也被称为对智能交通信号灯系统规划算法层面的一种漏洞攻击。一辆攻击车辆伪造的轨迹数据投毒攻击就足以导致交通延时增加68.1%,这比不用isig系统还要慢23.4%,有22%的车辆的通行时间甚至高出正常的14倍以上。本质上,数据污染攻击的关键是干扰信号规划算法的输入数据,由于联网车辆、路边单元和路口中央单元的软硬件及联动系统的复杂性,攻击者在多点都有可能实现到达表的记录数据干扰。
6、isig防护难点主要源于冷启动攻击的异常检测滞后性。攻击者会使用一辆或多辆新改造过的车辆入网,在获得授权后,可以突然地直接发送错误的位置和错误的速度等污染数据,而由于系统并没有该车辆的历史运行数据,同时系统计算该车辆附近参照车辆返回的数据可能存在延时或无法精确,最终导致无法在初始时间段做出及时有效的异常检测。而随着攻击车辆历史运行记录与相关参照车辆数据增多,isig系统才能逐渐利用异常检测充分地确认该冷启动投毒攻击的存在,并及时采取强制停止该车辆的数据发送等恢复措施。这个客观存在的异常检测滞后性,使得污染数据总会不可避免地作为输入进入系统,对输入敏感的isig系统安全带来不可忽视的风险。因此,从逻辑上看,即使增加基于异常检测规则的防火墙,也不太可能完全阻止冷启动污染数据的进入。
技术实现思路
1、在防护中除了考虑利用各种因素尽可能地缩小检测滞后时间,重点是考虑如何通过增加系统鲁棒性来实现在短时间克服干扰甚至区域“消化”这些污染数据,从现有的isig改进入手,探索通过统一的机制来实现针对isig智能交通信号灯规划算法cop的打补丁和优化,探索通过区域“消化”污染数据来实现针对投毒攻击的安全防护作用。
2、本发明针对智能交通信号系统isig数据投毒攻击,遵循以区域联合强化学习抵御多点投毒攻击为主的思路,以基于个体-联合体双向模型迁移的动态联合强化学习为核心,开展多主体协同一体化防护技术研究,能够有效防护投毒攻击,提高系统安全鲁棒性。
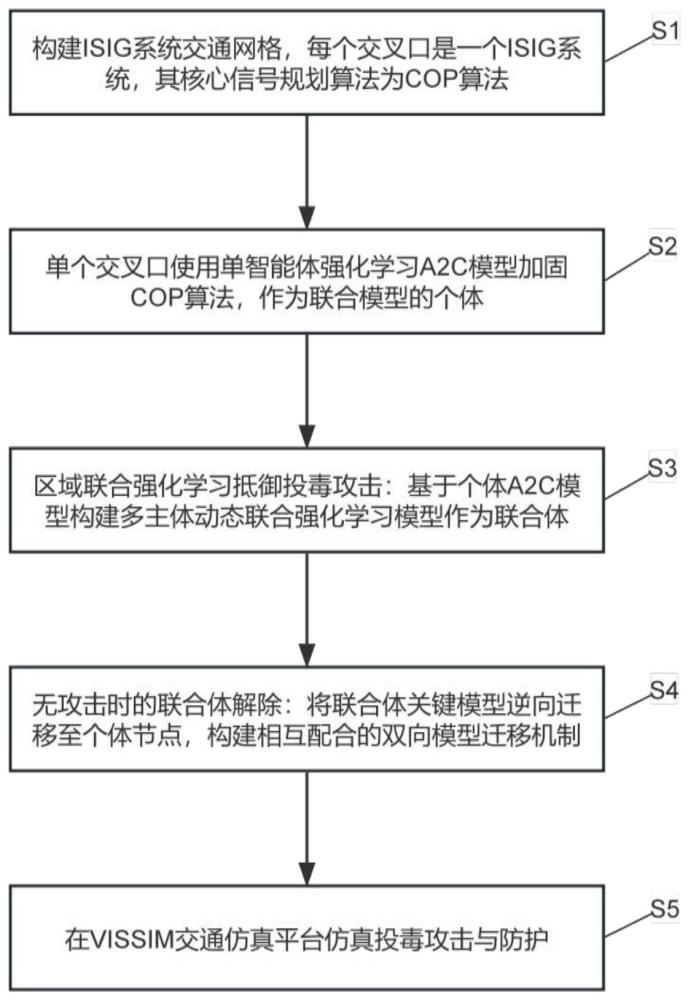
3、第一方面,一种双向模型迁移的多主体联合强化学习方法,包括下述步骤:
4、构建isig系统交通网格,将每个交叉口定义为一个isig系统,其核心信号规划算法为自适应相位控制cop算法;
5、单个交叉口使用单智能体强化学习a2c模型加固cop算法,作为联合模型的个体;
6、基于个体a2c模型构建多主体动态联合强化学习模型作为联合体;
7、将联合体关键模型逆向迁移至个体节点,构建相互配合的双向模型迁移机制。
8、在上述方案的基础上,所述构建isig系统交通网格的具体过程为:
9、设置交叉口数量和大小;
10、每个交叉口应用单独的isig系统进行信号控制。
11、在上述方案的基础上,所述单个交叉口使用单智能体强化学习a2c模型加固cop算法,作为联合模型的个体的具体过程为:
12、构建强化学习状态空间与动作空间:
13、平均划分交通网格的每个交叉口内的每条车道,对每个单元定义四维特征,分别是:单位异常态s、车辆数量n、等待时长w与车辆速度v;
14、设计奖励函数;
15、构建强化学习a2c模型:
16、在t时刻的模型表达式为:
17、
18、其中γ是折扣因子,rt+γv(st+1;w)是时间差分目标,rt+γv(st+1;w)-v(st;w)是一个优势函数;
19、在cop算法运行后使用a2c修正信号规划输出。
20、在上述方案的基础上,所述奖励函数具体为:
21、根据交叉口拥堵程度评价指标计算得到当前环境反馈奖励:
22、r=ω1∑i∈lli+ω2∑i∈ldi+ω3∑i∈lwi+ω4n+ω5t;
23、其中,li代表车道i上的车辆队列长度,di代表车道i上的车辆延迟程度,vl是车道上的车辆平均行驶速度,vm是车道上允许的最大行驶速度,n是固定时间间隔内通过交叉口的车辆总数,t是固定时间间隔内的车辆通过交叉口的总计通行时间,v是车辆的运行速度;wi(t)是车道i上t时刻的车辆等待时长:
24、
25、在上述方案的基础上,所述基于个体a2c模型构建多主体动态联合强化学习模型作为联合体的具体过程为:
26、构建基于个体模型迁移的联合体底层框架:
27、把强化学习网络模型嵌入到多主体联合学习模型框架中,通过构建适配层进行个体联合,将个体模型的动作输出序列作为适配层网络的输入;
28、构建递归神经网络rnn适配层进行个体联合:
29、包括输入层、隐含层以及输出层的构建;
30、输入层包含n个神经节点,n的个数等于参与动态联合模型构建的a2c个体模型个数;输出层输出新的动作序列;基于rnn构建神经网络上的所有节点,共享一套相同的参数(u,v,w,b,c),对于任意时序t,隐藏层上的状态可由输入at和前一时序的来确定:
31、
32、其中,u为输入层与隐含层上的连接参数,为基于前一时序值进行训练的参数,w为隐含层上的偏置项,b为联合训练模型个体数,时序t上模型的输出与网络预测输出通过下述公式计算得到:
33、
34、
35、其中,v为隐含层与输出层上的连接参数,c是输出层上的偏置项,m是隐含层神经节点的个数;
36、构建适配层分时训练机制。
37、在上述方案的基础上,所述构建适配层分时训练机制的具体过程为:
38、训练协同交通区域中的两个相邻交叉口的节点,将其余对应的神经节点进行权重休眠;
39、预先设置单轮训练迭代次数,当适配层神经网络达到预设迭代次数时,第一轮训练结束,两个相邻交叉口的节点存储训练好的参数矩阵;
40、在第二轮训练中,将新的一个节点加入到神经网络的训练中,继续对其余神经节点进行权重休眠,初始化新的一个节点上的权重参数,所述两个相邻节点的权重参数直接利用上一周期中训练好的参数值;
41、当达到预设迭代次数时该轮训练结束,参与训练的节点分别存储训练好的参数矩阵,开始下一轮迭代;
42、其中,利用对数似然损失函数lt实现反向传播计算:
43、
44、其中,为rnn的预测输出;是由环境反馈r,个体模型i所属交叉口环境状态si计算得到的期望输出,表示为表示预测概率;
45、时刻损失函数表示为参数c,v,w,b,u的梯度计算方法如下,其中δt为t时序的隐藏状态梯度;
46、
47、
48、
49、
50、
51、在上述方案的基础上,所述将联合体关键模型逆向迁移至个体节点,构建相互配合的双向模型迁移机制,具体过程为:
52、基于逆向迁移将关键参数保留至对应个体:
53、对每一个训练个体i来说,将网络参数ρi=(u,v,w,b,c)保存下来,与进行联合训练之前个体模型i的初始环境状态si0一起存储到个体模型i中,在下一次联合训练模型构建时,面向状态差异对适配层网络的初始化参数进行调整;
54、构建基于a2c状态差异的初始化参数向量调整方法:
55、调整初始化参数ρi为ρ′i=f(si0,sic),
56、
57、其中,ρi为个体模型保存的最近一次联合训练的适配层网络参数矩阵,ρ′i为基于状态差异调整后的参数矩阵,si0为个体模型i存储下来的最近一次联合训练之前的初始环境状态,sic为个体模型i的当前环境状态,ri为根据si计算得到的交叉口i拥堵状态评估指标,θ,为调整因子;
58、如果ri0>ric,则增加节点i的网络训练权重ρi;如果ri0=ric,则不改变ρi;如果ri0<ric,则减小节点i的网络训练权重ρi。
59、第二方面,提供一种电子装置,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现第一方面中所述的方法的步骤。
60、第三方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面中所述的方法的步骤。
61、第四方面,提供一种在交通仿真平台仿真投毒攻击与防护的方法,基于上述方案中任一项所述方法的步骤,包括下述步骤:
62、搭建两套包含网格节点的i-sig系统:
63、其中,一套定义为无攻击系统,另一套定义为有攻击系统,有攻击系统在无攻击系统复制基础上注入投毒攻击;
64、生成投毒攻击:基于单点投毒攻击实现异步多点攻击的模拟生成,并直接作用于有攻击系统。
65、对比分析:在仿真平台上进行有攻击系统与无攻击系统的可视化分析;
66、对模型反馈调优的细节数据分析。
67、本发明的有益效果:
68、本发明通过使用基于双向模型迁移的多主体联合强化学习模型,可以有效地防护针对智能交通信号系统的数据投毒攻击,提升交通信号控制的鲁棒性;基于双向模型迁移的多主体强化学习模型的动态联合与解除机制,充分利用每一次联合体的训练知识,有利于在实际应用中灵活适应遭受投毒攻击和无攻击情况下的信号控制。
- 还没有人留言评论。精彩留言会获得点赞!