一种交通信号灯策略评估演化方法及系统
本发明属于交通信号灯智能控制,特别涉及一种交通信号灯策略评估演化方法及系统。
背景技术:
1、交通信号灯策略对提高交通效率、缓解交通拥堵至关重要,良好的交通信号灯控制策略能够智能化调整红绿灯时长,有效缓解交通拥堵,提高道路使用效率,减少交通事故,对城市发展具有重要意义。
2、目前,传统采用固定时长的控制方式,存在极度依赖专家经验,且无法适应复杂多变的动态交通流的缺陷。鉴于上述固定时长控制方式存在的缺陷,研发人员提出了基于强化学习的交通信号灯控制方法(示例性的,如colight,可通过动态沟通、共享信息加强交通路口之间的协作能力;如presslight,可通过最大压力的状态和奖励设计,克服性能参数的敏感性),能够在一定程度上克服缺陷;但是,它们都需要较长的学习过程,且没有充分考虑交通路口的时间信息和控制策略的优劣,存在交通信号控制策略演化收敛慢,演化前期波动性大等一系列问题,亟需一种科学有效的策略评估方法。
3、现有比较成熟的策略评估方法alpha-rank,引入了多种群离散时间的模型和进化论中遗传突变的思想,在给出策略收益矩阵后,可以计算转移矩阵,得出多个智能体的策略分布和得分排名;但是,它更多适用于游戏环境,且随着动作和状态空间的增大,计算量也会很大,不适合部署到多个交通路口的环境进行策略评估。
技术实现思路
1、本发明的目的在于提供一种交通信号灯策略评估演化方法及系统,以解决上述存在的一个或多个技术问题。本发明提供的技术方案,通过决斗网络实现优势交通信号灯控制策略的评估,可解决策略演化收敛慢的问题;另外,通过时空融合的图神经网络充分捕捉交通路网和车流的时空信息,能够部署到实际大规模交通路口的环境。
2、为达到上述目的,本发明采用以下技术方案:
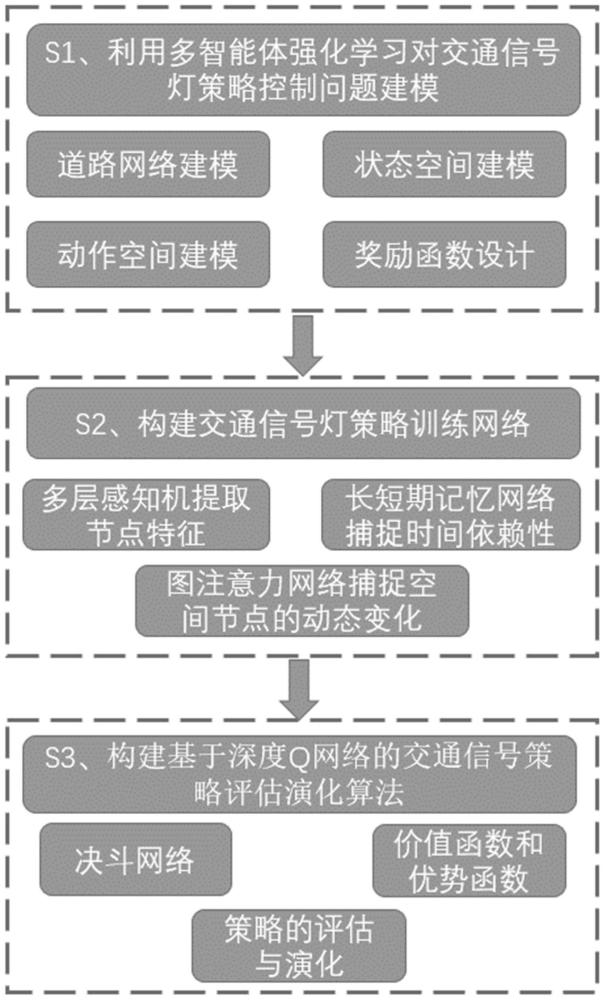
3、本发明第一方面,提供一种交通信号灯策略评估演化方法,包括以下步骤:
4、利用多智能体强化学习,将交通道路网络的信号灯控制策略问题建模为马尔可夫决策过程模型;
5、基于马尔可夫决策过程模型,构建交通信号灯策略训练网络;其中,所述交通信号灯策略训练网络中,利用多层感知机提取每个路口的交通状况和邻居信息,结合时空融合的图注意力网络动态捕捉邻近路口对目标路口的影响权重;
6、基于交通信号灯策略训练网络,构建基于深度q网络的交通信号策略评估演化算法,实现交通信号灯策略评估演化;其中,所述交通信号策略评估演化算法中,利用决斗网络的价值函数和优势函数,评估策略的优势,预测最佳动作,通过参数梯度更新逐步优化策略,进行优势策略演化。
7、本发明方法的进一步改进在于,所述利用多智能体强化学习,将交通道路网络的信号灯控制策略问题建模为马尔可夫决策过程模型的步骤包括:
8、假设系统中有n个交通路口,将每个交通路口视作一个智能体,每个智能体均将观察到的系统状态的一部分作为观测值;智能体的状态定义为智能体i在时间t的观测值由一个独热向量表示的当前信号相位和与交叉路口相连的每条进入车道上的车辆数量组成;智能体i的动作定义为候选动作集合的四种信号相位中的一种信号相位作为下一个时间段内的决策;其中,四种信号相位分别为东西方向直行、南北方向直行、东西方向左转和南北方向左转;
9、给定系统在时间t的状态st和相应的多个智能体的联合作用at,系统按照状态转移概率p(st+1|st,at)到达下一个状态st+1;
10、智能体i的奖励定义为其中,γ是惩罚因子,为时间t时在智能体i的进入车道l上的排队车辆数量;
11、使用每个智能体i在第n次迭代时的动作价值函数qi(θn),通过最小化损失来使深度神经网络逼近总奖励回报表达式为,
12、
13、其中,是下一次的观测值;是下一次的动作值;θn代表相关参数。
14、本发明方法的进一步改进在于,所述交通信号灯策略训练网络中,利用多层感知机提取每个路口的交通状况和邻居信息的步骤包括:
15、将道路网络的信息和车流中每辆车的出发地、目的地信息输入网络,提取每个交通路口进入车道上的信号相位、车辆数量信息作为输入层;利用两个全连接层构成的多层感知机提取特征,公式为,其中,we和be是要学习的权重矩阵和偏差向量,hi表征每个路口的交通状况。
16、本发明方法的进一步改进在于,所述交通信号灯策略训练网络中,结合时空融合的图注意力网络动态捕捉邻近路口对目标路口的影响权重的步骤包括:
17、将交通状况信息传递给时空融合的图神经网络;所述时空融合的图神经网络中,时间模块采用长短期记忆网络,空间模块采用图注意力网络;其中,
18、长短期记忆网络中,捕捉时间特征的公式为,h′i=lstm(hi);
19、图注意力网络中,首先确定交通路口i的邻近路口j在确定目标交通路口i的策略时的重要性,公式为,eij=(h′iwt)·(h′jws)t;其中,ws和wt分别是邻近路口和目标路口的多层感知机参数;归一化计算邻近路口j对目标交通路口i的重要性分数,公式为,
20、
21、其中,τ是影响系数,是目标路口的邻近路口的集合;
22、设定每个目标路口的邻近路口共有5个,分别为目标路口本身以及4个距离目标路口地理距离最近的路口,将多个邻近路口的特征与各自的重要性分数结合,公式为,
23、
24、其中,wc是邻近路口j的多层感知机的参数;wq和bq是待训练的参数;
25、采用多头注意力机制,并行执行多组可训练参数的注意力函数,最后取平均,公式为,
26、
27、其中,h是注意力头的数量,h=5;是第h个注意力头的重要性分数。
28、本发明方法的进一步改进在于,所述交通信号策略评估演化算法中,
29、采用决斗网络的架构,由评估网络和目标网络组成;其中,评估网络和目标网络为参数不同但结构相同的q网络,均由输入层、特征提取层、时空融合的图神经网络层、价值函数层、优势函数层和输出层构成;
30、每隔一定时间,将评估网络的参数复制给目标网络,目标网络产生预测的q值,并与评估网络的q值进行损失计算,以评估网络进行梯度更新;
31、q网络采用经验回放机制,使用深度神经网络来逼近值函数,将训练过的数据储存到回放记忆池中,用于后续从中随机采样进行训练;
32、在t时间,决斗网络产生预测q值,公式为,
33、
34、其中,θ是时空融合的图神经网络层的空间模块的参数,是价值函数层和优势函数层共享的;α和β分别是优势函数层和价值函数层的参数;是动作的集合;
35、优势函数层产生维的向量,价值函数层产生一维的标量;
36、基于策略训练网络得到的特征hmi,决斗网络的价值函数层和优势函数层的公式分别为,
37、
38、
39、其中,wp1,wp2,b1,b2分别是待学习的参数;
40、决斗网络优化策略演化的损失函数公式为,
41、
42、其中,t是影响网络更新的总时间步数;n是交通道路网络中的路口数量,θn表示所有的可训练参数。
43、本发明第二方面,提供一种交通信号灯策略评估演化系统,包括:
44、建模单元,用于利用多智能体强化学习,将交通道路网络的信号灯控制策略问题建模为马尔可夫决策过程模型;
45、策略训练网络构建单元,用于基于马尔可夫决策过程模型,构建交通信号灯策略训练网络;其中,所述交通信号灯策略训练网络中,利用多层感知机提取每个路口的交通状况和邻居信息,结合时空融合的图注意力网络动态捕捉邻近路口对目标路口的影响权重;
46、策略评估演化单元,用于基于交通信号灯策略训练网络,构建基于深度q网络的交通信号策略评估演化算法,实现交通信号灯策略评估演化;其中,所述交通信号策略评估演化算法中,利用决斗网络的价值函数和优势函数,评估策略的优势,预测最佳动作,通过参数梯度更新逐步优化策略,进行优势策略演化。
47、本发明系统的进一步改进在于,所述建模单元中,利用多智能体强化学习,将交通道路网络的信号灯控制策略问题建模为马尔可夫决策过程模型的步骤包括:
48、假设系统中有n个交通路口,将每个交通路口视作一个智能体,每个智能体均将观察到的系统状态的一部分作为观测值;智能体的状态定义为智能体i在时间t的观测值由一个独热向量表示的当前信号相位和与交叉路口相连的每条进入车道上的车辆数量组成;智能体i的动作定义为候选动作集合的四种信号相位中的一种信号相位作为下一个时间段内的决策;其中,四种信号相位分别为东西方向直行、南北方向直行、东西方向左转和南北方向左转;
49、给定系统在时间t的状态st和相应的多个智能体的联合作用at,系统按照状态转移概率p(st+1|st,at)到达下一个状态st+1;
50、智能体i的奖励定义为其中,γ是惩罚因子,为时间t时在智能体i的进入车道l上的排队车辆数量;
51、使用每个智能体i在第n次迭代时的动作价值函数qi(θn),通过最小化损失来使深度神经网络逼近总奖励回报表达式为,
52、
53、其中,是下一次的观测值;是下一次的动作值;θn代表相关参数。
54、本发明系统的进一步改进在于,所述交通信号灯策略训练网络中,利用多层感知机提取每个路口的交通状况和邻居信息的步骤包括:
55、将道路网络的信息和车流中每辆车的出发地、目的地信息输入网络,提取每个交通路口进入车道上的信号相位、车辆数量信息作为输入层;利用两个全连接层构成的多层感知机提取特征,公式为,其中,we和be是要学习的权重矩阵和偏差向量,hi表征每个路口的交通状况。
56、本发明系统的进一步改进在于,所述交通信号灯策略训练网络中,结合时空融合的图注意力网络动态捕捉邻近路口对目标路口的影响权重的步骤包括:
57、将交通状况信息传递给时空融合的图神经网络;所述时空融合的图神经网络中,时间模块采用长短期记忆网络,空间模块采用图注意力网络;其中,
58、长短期记忆网络中,捕捉时间特征的公式为,h′i=lstm(hi);
59、图注意力网络中,首先确定交通路口i的邻近路口j在确定目标交通路口i的策略时的重要性,公式为,eij=(h′iwt)·(h′jws)t;其中,ws和wt分别是邻近路口和目标路口的多层感知机参数;归一化计算邻近路口j对目标交通路口i的重要性分数,公式为,
60、
61、其中,τ是影响系数,是目标路口的邻近路口的集合;
62、设定每个目标路口的邻近路口共有5个,分别为目标路口本身以及4个距离目标路口地理距离最近的路口,将多个邻近路口的特征与各自的重要性分数结合,公式为,
63、
64、其中,wc是邻近路口j的多层感知机的参数;wq和bq是待训练的参数;
65、采用多头注意力机制,并行执行多组可训练参数的注意力函数,最后取平均,公式为,
66、
67、其中,h是注意力头的数量,h=5;是第h个注意力头的重要性分数。
68、本发明系统的进一步改进在于,所述交通信号策略评估演化算法中,
69、采用决斗网络的架构,由评估网络和目标网络组成;其中,评估网络和目标网络为参数不同但结构相同的q网络,均由输入层、特征提取层、时空融合的图神经网络层、价值函数层、优势函数层和输出层构成;
70、每隔一定时间,将评估网络的参数复制给目标网络,目标网络产生预测的q值,并与评估网络的q值进行损失计算,以评估网络进行梯度更新;
71、q网络采用经验回放机制,使用深度神经网络来逼近值函数,将训练过的数据储存到回放记忆池中,用于后续从中随机采样进行训练;
72、在t时间,决斗网络产生预测q值,公式为,
73、
74、其中,θ是时空融合的图神经网络层的空间模块的参数,是价值函数层和优势函数层共享的;α和β分别是优势函数层和价值函数层的参数;是动作的集合;
75、优势函数层产生维的向量,价值函数层产生一维的标量;
76、基于策略训练网络得到的特征hmi,决斗网络的价值函数层和优势函数层的公式分别为,
77、
78、
79、其中,wp1,wp2,b1,b2分别是待学习的参数;
80、决斗网络优化策略演化的损失函数公式为,
81、
82、其中,t是影响网络更新的总时间步数;n是交通道路网络中的路口数量,θn表示所有的可训练参数。
83、与现有技术相比,本发明具有以下有益效果:
84、本发明提供了一种交通信号灯策略评估演化方法,其在大规模交通路口的实际工程场景中,是一种行之有效的策略评估方法,可有效应对大规模交通路口的复杂多变的动态交通流量场景,实现优势交通信号灯策略的评估演化;能够加快交通信号控制策略的演化收敛,最小化路网中车辆的平均行程时间,最大化路网的吞吐量,降低部署的难度和成本。
85、针对交通信号灯策略的部署问题,本发明采用了时空融合的图神经网络的方法,用长短期记忆网络捕捉信号相位序列的时间依赖性,用图注意力网络获取交通路口的车流特征、信号相位特征等,使得交通信号灯的策略可充分考虑时间特征和空间特征,能有效开展多个路口的动态信息共享与协作,扩展到大规模路口的环境,并实际可部署。
86、针对交通信号灯策略的评估演化问题,本发明具体采用了决斗网络的方法,用决斗网络的优势函数评估策略的优势,并能预测信号相位动作,使得交通信号灯的策略可以经过优势评估,可促进优势策略演化,提高稳定性,并可避免演化过程中的无效策略探索,提高学习效率,加快策略的演化收敛。
- 还没有人留言评论。精彩留言会获得点赞!