基于改进的深度强化学习单交叉口路口交通灯控制方法与流程
本发明属于交通信号灯控制,尤其涉及基于改进的深度强化学习单交叉口路口交通灯控制方法。
背景技术:
1、近年来,人工智能技术的快速发展为智能交通系统(intelligenttransportation system,its)的应用提供了契机,能够帮助优化交通流,提高通行效率和安全性,其中,交通流量检测和交通信号控制尤为重要。交通流量检测作为交通控制的信息来源,可以让交通管理者快速了解当前路面的实际情况,从而加快对紧急或复杂事件的处理效率同时也能更好地为驾驶员和乘客提供实时信息和建议。交通信号灯作为交通流控制的核心工具,控制方式正从传统的静态模式向智能化、动态化转变,以适应不断变化的交通需求,缓解城市交通拥堵问题。
2、交通流量检测主要以车流目标检测方法为主,传统方法是通常依赖于相关的硬件设备,例如地磁传感器、红外传感器或者微波雷达灯对车体进行统计分析,具有较高的实时性和一定的准确性。而另一种目前更主流的方式是通过计算机视觉(computer vision,cv)技术对摄像头下的视频进行车辆检测,该方法能够得到实时全面的交通信息且安装维护简易方便,同时也具有准确性较高的特点。目前已有的交通灯控制算法主要有以下几种:
3、通过分析行人的存在、区域内车辆的分类、对通行时间的适当评估以及不同程度的交通拥堵等历史交通信息,利用离散时间模型来描述系统,进行周期性采样,并通过解决数学规划问题来获取定时计划,然后预先设定好的每个相位信号灯的时间间隔,不对道路状况的变化而做出相关调整,从而完成交通灯静态固定时长的控制。这种交通灯的静态固定时长控制是目前最常用的信号控制方式,因其简单易维护且不需动态调整,用户能够预测信号变化。然而,这种方法可能导致时间和能源的浪费。当某个方向的车辆密度频繁变化时,固定时长控制的不足便显现出来,容易引发交通拥堵。
4、通过交通流量、交叉口的信号控制策略和车辆排队长度等因素构建max-pressure模型,输入交叉口的实时交通流数据及车辆到达率和排队情况,利用该模型计算每个交叉口的“压力”(即车辆到达率与排队长度的比值),选择压力最大的方向进行信号放行。随着实时的信息的获取和压力计算,动态调节信号灯的相位以及持续时间,从而达到交通灯的动态时长控制。基于模型的交通灯控制方法通常依赖于特定的交通流模型,而这些模型可能无法充分反映实际交通情况的复杂性,导致结果不够可靠。在动态变化的交通环境中,这种局限性尤为明显,可能导致频繁的信号调整和不必要的交通拥堵。其算法也存在一些固有缺陷,例如局部寻优能力较弱、计算精度低以及收敛性差等问题。
5、系统通过各种传感器和监控设备收集和处理实时交通流量数据,例如车辆数量、速度和密度等。然后将收集到的交通流量数据,scoot分析交通拥堵状况和流量变化趋势,从而确定合适的控制周期和信号相位时长。之后根据控制周期和相位时长,计算交通信号的偏移量和相位设置,这样便可对交通灯进行自适应控制。自适应交通灯控制方法与多种算法结合以解决交通问题,但算法的缺陷可能导致建模困难和局部最优解的产生。由于这类的方法要求高效的数据采集与处理能力,以及强大的算法优化能力,其对道路网络和交通流量变化敏感,这可能导致交通信号控制的不稳定性和不确定性。
6、将交叉口信号控制问题转化为马尔可夫决策过程,由状态空间、动作空间、状态转移概率、奖励函数和折扣因子表示。其中,状态空间内的状态主要包含有排队长度、累积等待时间、车辆平均速度、车辆数量相关交通流信息。动作空间是采用改变交通灯相位的方式来表示。状态转移概率是在某时刻,根据状态和智能体的动作共同作用下获取的下一个可能状态的概率分布。价值函数由状态价值函数和动作价值函数决定,于深度强化学习的a2c算法通常需要大量的样本来训练,且对过往的经验利用率较低,导致训练时间较长。而且在大量新数据的加入中,训练过程可能面临不稳定,尤其是在学习率调整不当时,会导致性能波动。
7、深度强化学习(drl)是结合深度学习(deep learning, dl)与强化学习(reinforcement learning, rl)的方法,通过不断地进行“试错”的方式来学习。drl的三个核心要素是状态、动作和奖励。状态(state)是描述智能体当前环境的信息,动作(action)是智能体基于状态做出的响应,可能是离散或连续的。奖励(reward)是智能体在采取动作后获得的即时反馈,通常通过设定机制来激励或惩罚智能体的行为,正向奖励促使智能体学习某一动作,负向奖励则抑制不当行为。drl的目的在于最大化累积奖励,通过智能体与环境交互来实现优化动作选择。智能体在每个时刻观察环境状态,选择相应动作,并根据结果获得奖励,通过奖励机制调整行为,从而实现对环境的最优响应通过这些机制,如图1所示。利用advantage actor critic(a2c)算法对策略函数的参数进行更新迭代,通过不断地添加数据,利用奖励函数优化动作选择策略使得智能体能够达到快速的收敛, 从而让智能体来完成对交通灯的控制。基于深度强化学习的a2c算法通常需要大量的样本来训练,且对过往的经验利用率较低,导致训练时间较长。而且在大量新数据的加入中,训练过程可能面临不稳定,尤其是在学习率调整不当时,会导致性能波动。
8、因此,如何对现有的深度强化学习交通灯控制方法进行改进,以减小模型训练样本,提高样本利用率,加快学习速度,让模型能够更快的收敛,同时升模型的稳定性与准确性,是目前亟需解决的技术问题。
技术实现思路
1、本发明的目的在于提供基于改进的深度强化学习单交叉口路口交通灯控制方法,用以减小模型训练样本,提高样本利用率,加快学习速度,让模型能够更快的收敛,同时升模型的稳定性与准确性。
2、为解决上述技术问题,本发明采用的技术方案如下:
3、基于改进的深度强化学习单交叉口路口交通灯控制方法,包括以下步骤:
4、s1:获取当前被控制单交叉路口的当前车辆的密度、当前车辆速度以及当前车辆等待时间,并基于当前车辆的密度、当前车辆速度以及当前车辆等待时间定义智能体状态值s,动作空间a,动作选择策略ε和奖励函数 r;
5、s2:创建神经网络q(s, a;θ)和目标网络q’(s’, a;θ-)和经验池e,将智能体状态值s,动作空间a,动作选择策略ε和奖励函数 r存储于经验池e中,并从中采样一个批次对创建的神经网络q(s, a;θ)进行训练;
6、s3:将训练后的神经网络q(s, a;θ)的参数更新至目标网络q’(s’, a;θ-);
7、s4:基于神经网络q(s, a;θ)和目标网络q’(s’, a;θ-)共同对单交叉口路口交通灯进行控制。
8、优选的,在步骤s1中定义状态值s的具体过程为:
9、s110:对被控制单交叉路口的道路进行均匀分布,遍历车辆列表;
10、s111:当主干道上有车辆时,计算其与红绿灯交叉口的距离,以判断车辆在当前时间步的单元格位置,并统计该单元格内的车辆数量;
11、s112:根据每个单元格预设的最大承载车辆数,采用离散交通编码计算并表示当前单元格的车辆密度;
12、s113:引入速度参数,构建当前单元格内车辆的平均速度并设置为速度矩阵;
13、s114:合并两个单独通道 s p和 s v,得到所述智能体状态值s。
14、优选的,步骤s112中采用离散交通编码计算并表示当前单元格的车辆密度的具体公式为:
15、;
16、其中,为第 i行第列中的车辆密度值, l为单条交通道路的长度, x为隔断计数的距离。
17、步骤s113中,引入速度参数,构建当前单元格内车辆的平均速度并设置为速度矩阵的具体公式为:
18、;
19、步骤s114中合并两个单独通道 s p和 s v,得到所述智能体状态值s的具体公式如下:
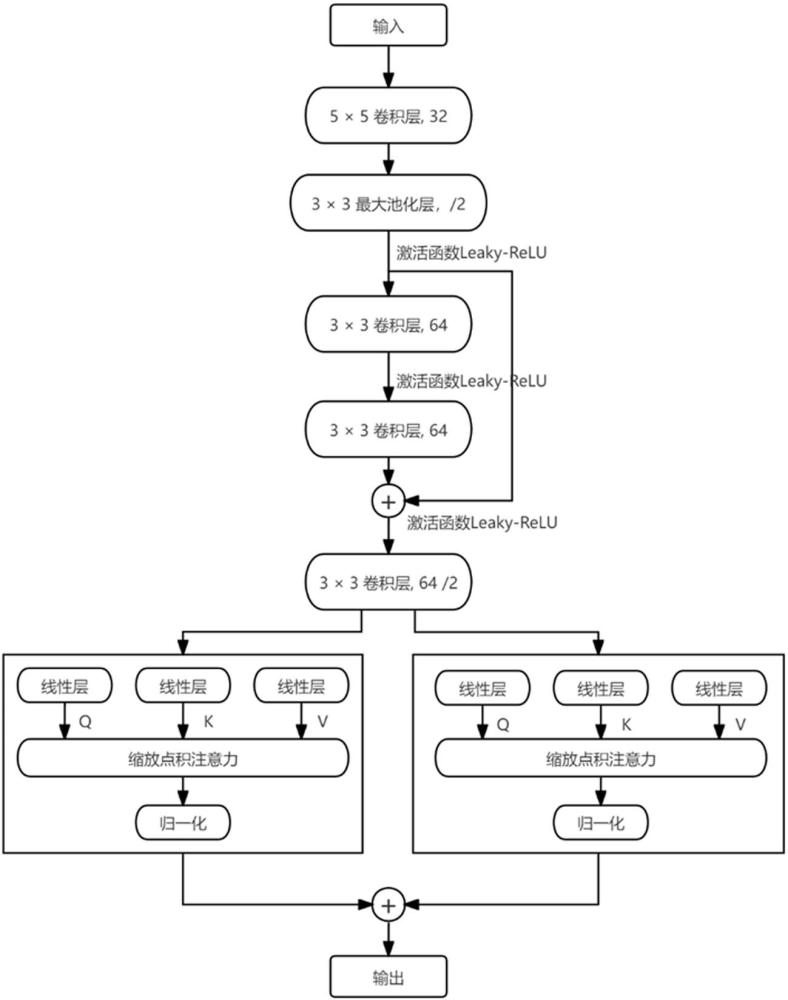
20、。
21、优选的,所述动作空间a基于改变信号灯相位的方式表示,所述动作相位包括4种,分别为{0,1,2,3},其中0表示为南北方向直行右转绿灯;1表示为南北方向左转绿灯;2表示为东西方向直行右转绿灯;3表示为东西方向左转绿灯。
22、优选的,采用累积奖励数据来构建所述动作选择策略ε的动作选择策略函数ε( g),所述动作选择策略函数ε( g)的具体表达式如下:
23、;
24、策略表达式π(a | s)的具体公式为:
25、;
26、其中, g i为第 i次选择所获取的累积奖励, a为学习率, a*为最佳学习率, k为修正系数。
27、优选的,所述奖励函数 r是基于车辆等待时间t以及队列长度l作为对智能体行动后对其进行奖励与惩罚的标准,对奖励函数 r进行系数修正,修正后奖励函数 r t的具体公式为:
28、;
29、其中, t i是第 i次行动后车辆等待的时间, li是第 i次行动后队列的长度值, α∈(0,1), β∈(0,1), α和 β均为修正参数。
30、优选的,步骤s2中的神经网络结构包括输入层、隐藏层和输出层;
31、所述隐藏层的第一层为5×5的卷积层,卷积核32个;第二层为3×3的最大池化层;第三层为3×3的卷积层,卷积核64个;第四层为3×3的卷积层,卷积核64个;第五层为3×3的卷积层,卷积核64个;
32、所述输出层设有两路不同的分支,一个输出分支用于输出状态值函数,另一个输出分支用于状态相关的动作优势函数,最后通过将输出状态值函数和结果和动作优势函数的结果进行合并后输出。
33、优选的,所述神经网络的输入为当前状态值s,输出为对原q值分解的状态值函数和结果和动作优势函数的结果的合并值;
34、所述原q值的计算公式如下:
35、;
36、目标q值q’的更新的具体公式如下:
37、;
38、对所述神经网络的训练通过随机梯度下降算法,通过计算最小化实际𝑄值𝑄(𝑠,𝑎, 𝜃)和目标𝑄值𝑄′的差值来表示损失函数,损失函数的具体公式为:
39、。
40、优选的,步骤s2的具体训练过程如下:
41、s21:初始化神经网络q(s, a; θ) 、目标网络q’(s’, a; θ-) 、经验池e和动作选择策略ε;
42、s22:获取当前时间的当前环境下的状态值 s t;
43、s23:根据当前网络q(s, a;θ) 和选取策略π( a|s) 获取当前行动 a t;
44、s24:执行行动 at,通过环境获取回报 rt和t+1时刻的状态s t+1;
45、s25:将(st, at,rt, st+1) 储存在经验池e中,并获取经验池e中数据的数量 n;
46、s26:使用动作选择策略函数ε( g)来优化动作选择策略ε;
47、s27:从经验池e中采样m个数据{(st, at, rt,st+1)}进行训练。
48、优选的,步骤s2中的将当前神经网络q(s’, a;θ-)的参数更新到目标网络q’(s’, a;θ-) 具体过程如下:
49、采用目标网络q’(s’, a;θ-) 来计算目标q值q’,最小化损失函数并更新神经网络q(s, a;θ),将当前神经网络q(s, a; θ) 的参数更新到目标网络q’(s’, a; θ-) 中。
50、本发明的有益效果包括:
51、本发明提供的基于改进的深度强化学习单交叉口路口交通灯控制方法,获取当前被控制单交叉路口的当前车辆的密度、当前车辆速度以及当前车辆等待时间,并基于当前车辆的密度、当前车辆速度以及当前车辆等待时间定义智能体状态值s,动作空间a,动作选择策略ε和奖励函数 r;创建神经网络和目标网络和经验池e,将智能体状态值s,动作空间a,动作选择策略ε和奖励函数 r存储于经验池e中,并从中采样一个批次对创建的神经网络进行训练;将训练后的神经网络的参数更新至目标网络;基于训练后的神经网络和参数更新的目标网络对单交叉口路口交通灯进行控制。
52、首先,通过优化动作选择策略ε,在探索新策略和利用已有知识之间取得平衡,避免过早收敛于局部最优解。同时引入了经验回放机制,可以重复的利用过往的经验,提高了样本的利用率,从而加快了学习速度,让模型能够更快的收敛。
53、其次,通过优化q值神经网络,在特征提取方向,引入resnet结构能够获取更深更全面的特征信息,通过引入attention模块,加强了结果稳定和准确的输出能力,在交通流量模式中基本保持了优秀的控制效果,在各方向车辆到达率极度不平衡的交通流量模式下,依旧能快速降低车辆等待时间和以及队列长度,相比单独的深度强化学习具有更稳定的优化效果与更好的泛化能力。
54、再次,改进后的深度强化学习算法不仅能够处理实时的数据,同样能够在离线数据上进行训练,这使其在需要处理大量历史数据时更为有效。
55、最后,通过对深度强化学习的神经网络进行改进,特征提取部分由单残差结构组成,在获取深度特征的基础上保留了原有特征,防止部分特征消失,两个分支分别由两个self-attention结构组成,最后将两个结果组合起来以产生一个输出q函数,增加了神经网络模型获取固定信息的能力。
- 还没有人留言评论。精彩留言会获得点赞!