基于强化学习的模型确定方法、装置、设备、介质及产品与流程
本公开涉及人工智能和智能交通,具体涉及基于强化学习的模型确定方法、装置、设备、介质及产品。
背景技术:
1、随着经济的迅速发展,人民生活水平日渐提高,居民出行意愿大幅增加。机动车持有量随着出行需求的增大呈现爆发式增长,使得出行更加便利、灵活。交通的迅速发展不仅促进了社会进步,改善了人民生活,还推动了科技进步。然而,现有的城市交通资源无法很好地满足交通需求,机动车的爆发式增长加剧了城市交通的供需不平衡,导致交通拥堵问题日益严重,同时伴随交通堵塞产生的尾气也加剧了环境污染。
2、针对上述问题,相关技术通常采用以下三种方法:(1)定时红绿灯控制方法;(2)基于非学习控制算法的红绿灯控制方法;(3)基于强化学习的红绿灯控制方法。目前业界普遍认为基于强化学习的红绿灯配时方法在减少车辆延误时间、提高通行效率等方面优于其他的传统方法,但其仍存在一些问题,主要体现在:(1)强化学习需要大量的训练数据和训练时间来学习适应复杂环境;(2)强化学习需要大量的计算资源来处理复杂的状态和动作空间,对硬件和计算能力提出了较高的要求;(3)在训练过程中,探索和试错可能会导致智能体的行为不稳定,同时可能会出现收敛性问题,使得算法的不确定性增加。
3、因此,相关技术中的基于强化学习的红绿灯控制方法存在训练成本高,算力需求高,以及训练收敛性和稳定性差的问题。
技术实现思路
1、有鉴于此,本公开提供了一种基于强化学习的模型确定方法、装置、设备、介质及产品,以解决相关技术中的基于强化学习的红绿灯控制方法存在训练成本高,训练收敛性和稳定性差,以及算力需求高的问题。
2、第一方面,本公开提供了一种基于强化学习的模型确定方法,该方法包括:
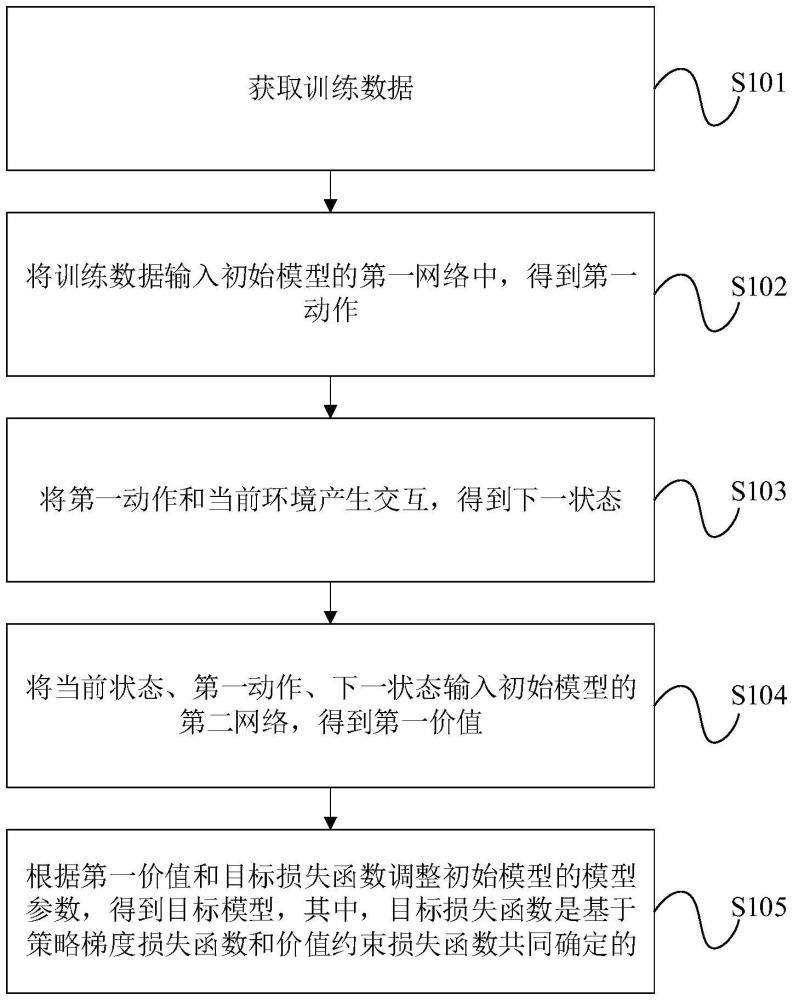
3、获取训练数据;
4、将训练数据输入初始模型的第一网络中,得到第一动作;
5、将第一动作和当前环境产生交互,得到下一状态;
6、将当前状态、第一动作、下一状态输入初始模型的第二网络,得到第一价值;
7、根据第一价值和目标损失函数调整初始模型的模型参数,得到目标模型,其中,目标损失函数是基于策略梯度损失函数和价值约束损失函数共同确定的。
8、在本公开实施例中,通过获取训练数据;将训练数据输入初始模型的第一网络中,得到第一动作;将第一动作和当前环境产生交互,得到下一状态;将当前状态、第一动作、下一状态输入初始模型的第二网络,得到第一价值;根据第一价值和目标损失函数调整初始模型的模型参数,得到目标模型,其中,目标损失函数是基于策略梯度损失函数和价值约束损失函数共同确定的。由于本公开实施例基于第一网络得到第一动作,基于当前状态、第一动作、下一状态以及第二网络得到第一价值,之后基于第一价值、策略梯度损失函数和价值约束损失函数共同确定目标损失函数,调整模型参数,实现基于训练数据动态约束第一网络,降低第一网络的训练成本和算力需求,提高第一网络的收敛性、稳定性和跨场景泛化能力。
9、在一种可选的实施方式中,获取训练数据,包括:
10、获取示教数据,其中,示教数据为初始模型在训练过程中对模型参数停止调整时的参考数据,示教数据包含在训练数据内;
11、将示教数据加载到第一缓冲区;
12、获取当前环境产生交互后得到的实时数据,实时数据包含在训练数据内;
13、将实时数据加载到第二缓冲区。
14、在本公开实施例中,通过在第一网络的训练过程中引入示教数据来动态约束训练过程,提高第一网络的收敛性和稳定性。同时由于在第一网络的训练过程中加入了示教数据,使得第一网络无需大量的训练数据和训练时间来适应复杂环境,降低了第一网络的训练成本和算力需求。
15、在一种可选的实施方式中,将训练数据输入初始模型的第一网络中,得到第一动作,包括:
16、从第一缓冲区中获取第一预设数量个第一采样数据,从第二缓冲区中获取第二预设数量个第二采样数据;
17、将第一采样数据和第二采样数据输入第一网络中,得到第一动作。
18、在本公开实施例中,从第一缓冲区中选取第一采样数据主要用于约束第一网络训练过程,使其保持较好的稳定性;从第二缓冲区中选取第二采样数据主要用于提高第一网络在未见场景中的泛化能力,解决示教数据无法覆盖所有场景的问题,使第一网络能够适用于通用场景。
19、在一种可选的实施方式中,在根据第一价值和目标损失函数调整初始模型的模型参数,得到目标模型之前,方法还包括:
20、根据示教数据和第二网络,得到第二价值;
21、比较第一价值和第二价值,确定价值约束损失函数;
22、根据策略梯度损失函数和价值约束损失函数确定目标损失函数。
23、在本公开实施例中,通过比较第一价值和第二价值,进而确定价值约束损失函数,可以在防止预训练策略出现灾难性遗忘的同时,实现稳定的策略提升。
24、在一种可选的实施方式中,比较第一价值和第二价值,确定价值约束损失函数,包括:
25、在第一价值大于第二价值的情况下,确定第一价值约束损失函数,并将第一价值约束损失函数作为价值约束损失函数;
26、在第一价值小于或者等于第二价值的情况下,确定第二价值约束损失函数,并将第二价值约束损失函数作为价值约束损失函数。
27、在本公开实施例中,通过判断第一价值和第二价值的比较结果,能够判断第一动作相比于示教数据的优劣,设置相应的价值约束损失函数,对第一网络训练过程进行引导,在防止预训练策略出现灾难性遗忘的同时,实现稳定的策略提升。
28、在一种可选的实施方式中,根据策略梯度损失函数和价值约束损失函数确定目标损失函数,包括:
29、获取策略梯度损失函数和价值约束损失函数之和,确定目标损失函数。
30、在本公开实施例中,通过在目标损失函数中加入价值约束损失函数,提高第一网络训练的收敛性和稳定性,能够平衡第一网络的训练收敛性和训练效率。
31、第二方面,本公开提供了一种基于强化学习的模型确定装置,该装置包括:
32、第一获取模块,用于获取训练数据;
33、第一得到模块,用于将训练数据输入初始模型的第一网络中,得到第一动作;
34、第二得到模块,用于将第一动作和当前环境产生交互,得到下一状态;
35、第三得到模块,用于将当前状态、第一动作、下一状态输入初始模型的第二网络,得到第一价值;
36、第四得到模块,用于根据第一价值和目标损失函数调整初始模型的模型参数,得到目标模型,其中,目标损失函数是基于策略梯度损失函数和价值约束损失函数共同确定的。
37、第三方面,本公开提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面或其对应的任一实施方式的基于强化学习的模型确定方法。
38、第四方面,本公开提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的基于强化学习的模型确定方法。
39、第五方面,本公开提供了一种计算机程序产品,包括计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的基于强化学习的模型确定方法。
- 还没有人留言评论。精彩留言会获得点赞!