一种有声读物逐句同步展示方法与流程
本发明属于有声读物技术领域,特别涉及一种有声读物逐句同步展示方法。
背景技术:
传统的有声读物主要是以唱片、磁带或广播的形式进行传播,由于不能将文字与音频同步播放,也不能实现具体段落或语句的点选,有听不清楚的地方无法快速对比阅读,也难以反复收听确认,使用时会受到较大限制。随着科技的高速发展,当代的有声读物越来越多地借助网络和智能电子设备,使得播放音频的同时可以同步查看相应的文本,也可以点选特定的段落或语句进行播放,以提高有声读物的使用体验。
授权公告号为CN102324191B的发明专利公开了一种有声读物逐字同步显示方法及系统,通过读取语速、计算每个文字所需的时间,使文字和语音得以实现逐字同步播放,适用于儿童读物,可以方便儿童识字。然而该方法需要计算每个文字的起始时间和终止时间,工作量过大,对服务器配置要求较高,对于非儿童读物来说增加了不必要的成本,并且不能点选所需的段落或语句。因此,在尽可能节约成本的基础上,开发出一种既能实现文字和视频同步显示、同时还能实现点读选读的播放方法,成为本领域技术人员急需解决的技术问题。
技术实现要素:
为了解决上述技术问题,本发明提供了一种有声读物逐句同步展示方法。
本发明具体技术方案如下:
本发明一方面提供了一种有声读物逐句同步展示方法,包括如下步骤:
S1:将有声读物的文本文件进行分句并标记时间戳,制成LRC文件;
S2:将所述LRC文件提交至服务器并进行储存,以供客户端查询获取;
S3:客户端选择有声读物的音频文件后,访问服务器端,查询并获取对应的LRC文件,将所述LRC文件中的所有时间戳转换成链接锚点并组成锚点数组;基于当前播放时间和锚点数组,实现一个获取当前句子的算法函数getCurrentSentence(),以及一个获取后序句子时间锚点的算法函数getNextSentencePosition(),在播放音频文件的同时调整LRC的播放进度。
进一步地,其特征在于,所述步骤S1的具体方法如下:
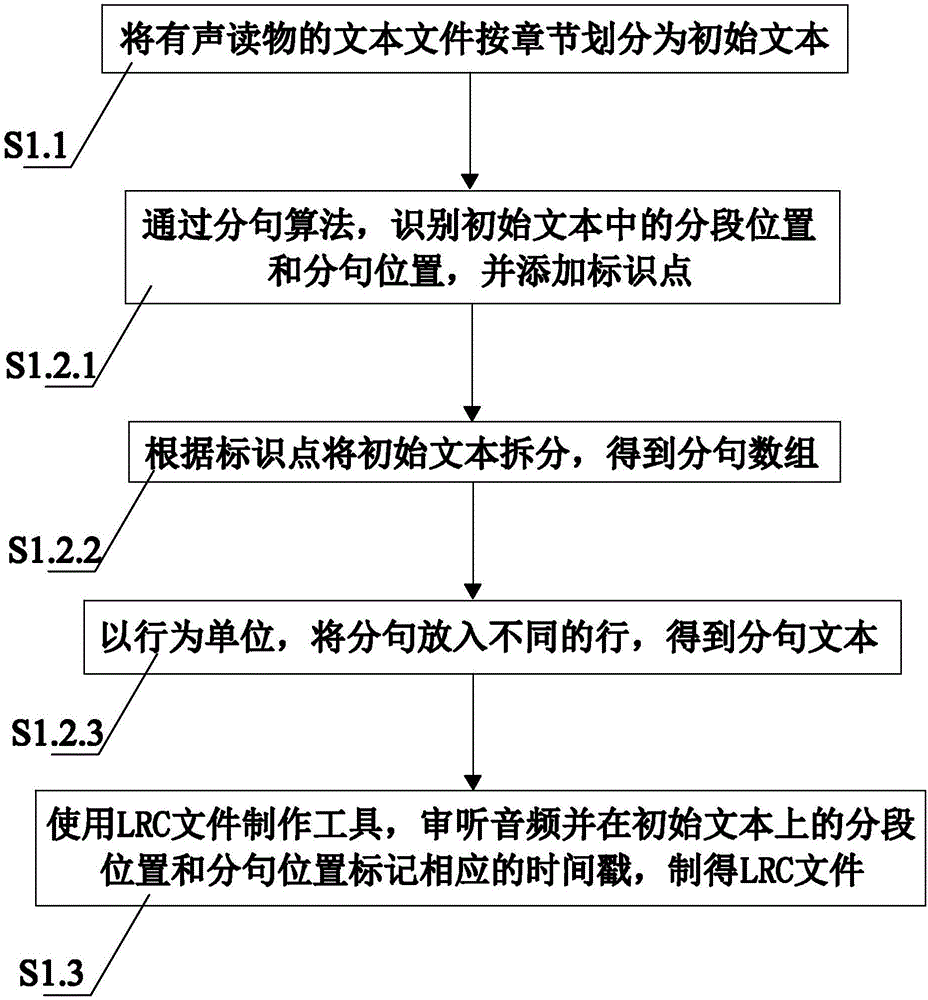
S1.1:获取有声读物对应的文本文件,按章节划分为若干初始文本;
S1.2:使用文本分句模块11,将各章节的初始文本转换为分句文本;
S1.3:使用LRC文件制作模块,审听音频的同时在初始文本上的分段位置和分句位置标记相应的时间戳,制得LRC文件。
进一步地,所述步骤S1.2的具体方法如下:
S1.2.1:通过分句算法,识别初始文本中的分段位置和分句位置,并添加标识点;
S1.2.2:根据标识点将初始文本拆分,得到分句数组;
S1.2.3:以行为单位,将分句重新放入不同的行,得到分句文本。
进一步地,所述步骤S2的具体方法如下:
S2.1:在服务器中添加有声读物的基本信息和章节信息,;
S2.2:将制作好的LRC文件上传至服务器中,并与对应的章节信息进行关联。
进一步地,所述步骤S3的具体方法如下:
S3.1:用户在客户端点播指定的书籍,客户端的网络交互模块向服务器发送请求,以获取此书的详细数据;获取到详细数据后,在书籍详情页面,展示出书籍的标题、简介等详细信息,并提供播放按钮;
S3.2:客户端对章节信息进行加载,同时将相应的LRC文件下载到本地并进行加载;
S3.3:加载完成后,客户端进入监听状态,将所述LRC文件中的所有时间戳转换成链接锚点并组成锚点数组;基于当前播放时间和锚点数组,实现一个获取当前句子的算法函数getCurrentSentence(),以及一个获取后序句子时间锚点的算法函数getNextSentencePosition(),在播放音频文件的同时调整LRC的播放进度,以实现LRC文件中的文本与音频的逐句同步显示。
进一步地,所述步骤S3.3的具体方法如下:
S3.3.1:将LRC文件中的文本以行作为单位进行合并,生成完整的电子文本;
S3.3.2:将文本中的时间戳转换成链接锚点,并隐藏其显示;
S3.3.3:抽取文本中的所有时间戳锚点,并保存成锚点数组;
S3.3.4:客户端基于锚点数组和当前时间,实现一个获取当前句子的算法函数getCurrentSentence();
S3.3.5:客户端基于锚点数组和当前时间,实现一个获取后序句子时间锚点的算法函数getNextSentencePosition();
S3.3.6:客户端监听当前音频文件的播放进度,当播放进度更新时, 调用getNextSentencePosition()函数,获取后序句子切入的时间戳位置,如果当前进度小于此时间戳位置,则保持当前句子的高亮显示;如果当前进度已经大于或等于此时间戳位置,则调用getCurrentSentence()函数,获取要切换显示的句子,在客户端更新高亮显示。
进一步地,所述步骤S3还包括如下步骤:
S3.4:当用户点击文本时,客户端获取对应的句子,读取句首的链接锚点,解析出其中的时间戳信息;根据时间戳的值,控制音频的播放进度到相应的位置,以实现文本的选句点读功能。
本发明另一方面提供了一种有声读物逐句同步展示系统,包括文件源、服务器以及客户端,所述文件源用于将有声读物对应的文本文件制作成LRC文件,包括:
文本分句模块,用于将初始文本转换为分句文本;
LRC文件制作模块,用于将分句文本制作成LRC文本;
所述服务器用于存储有声读物的基本信息、章节信息和LRC文件,接收客户端索要有声读物的请求,并将相应文件发送给客户端,包括:
书籍管理模块,用于管理有声读物的基本信息、音频信息和LRC文件,并将所述LRC文件与所述章节信息进行关联;
所述客户端用于对有声读物的音频文件和LRC文件进行播放和进度调整,以实现LRC文件与音频文件的逐句同步显示以及选句点读功能,包括:
网络交互模块,用于向所述服务器发送索要有声读物的请求,并接收相应信息;
播放器,用于同步播放有声读物的音频文件和LRC文件。
进一步地,所述服务器包括:
章节信息管理子模块,用于根据章节添加有声读物所包含的基本信息和音频信息;
LRC文件管理子模块,用于上传LRC文件,并将LRC文件与各章节的基本信息和音频信息进行关联。
进一步地,所述播放器包括文本同步展示模块,所述文本同步展示模块用于加载LRC文件,并调整LRC的播放进度,以实现LRC文件中的文本与音频的逐句同步显示。
本发明的有益效果如下:本发明提供的有声读物逐句同步展示方法和系统首先将文本文件转换为分句文件,再将分句文件制作成LRC文件,并添加相应的时间戳;播放音频时将LRC文件与音频文件设置关联,并分别生成用于选取当前句子和后续句子的函数,使得播放时可以根据音频的播放进度准确定位相应的句子,以此实现音频和文字的同步播放,并且分句比分字工作量大大减少,避免增加不必要的成本。同时,由于每个句子均添加有对应的链接锚点,并且与有声读物的音频文件以及其他信息相关联,因此当选择特定的句子时,可通过链接锚点解析出相应的时间戳,并将音频定位到相应位置,由此实现点播选播的功能。
附图说明
图1为实施例1所述的一种有声读物逐句同步展示方法的流程图;
图2为实施例2所述的一种有声读物逐句同步展示方法中步骤S1的流程图;
图3为实施例3所述的一种有声读物逐句同步展示方法的流程图;
图4为实施例4所述的一种有声读物逐句同步展示方法中步骤S3的流程图;
图5为实施例4所述的一种有声读物逐句同步展示方法中步骤S3.3的流程图
图6为实施例4所述的一种有声读物逐句同步展示方法中LRC文件示意图;
图7为实施例5所述的一种有声读物逐句同步展示系统的结构示意图;
图8为实施例6所述的一种有声读物逐句同步展示系统的结构示意图。
其中:1、文件源;11、文本分句模块;12、LRC文件制作模块;2、服务器;21、书籍管理模块;211、章节信息管理子模块;212、LRC文件管理子模块;3、客户端;31、网络交互模块;32、播放器;321、文本同步展示模块。
具体实施方式
下面结合附图和以下实施例对本发明作进一步详细说明。
实施例1
如图1所示,本发明实施例1提供了一种有声读物逐句同步展示方法,包括如下步骤:
S1:将有声读物的文本文件进行分句并标记时间戳,制成LRC文件;
S2:将所述LRC文件提交至服务器2端并进行储存,以供客户端3查询获取;
S3:客户端3选择有声读物的音频文件后,访问服务器2端,查询并获取对应的LRC文件,将所述LRC文件中的所有时间戳转换成链接锚点并组成锚点数组;基于当前播放时间和锚点数组,实现一个获取当前句子的算法函数getCurrentSentence(),以及一个获取后序句子时间锚点的算法函数getNextSentencePosition(),在播放音频文件的同时调整LRC的播放进度。
本实施例提供的有声读物逐句同步展示方法首先将文本文件转换为分句文件,再为每一分句添加相应的时间戳,将分句文件制作成LRC;用户在使用客户端时,点选某本书籍,此时客户端的网络交互模块会向服务器管理平台的书籍管理模块发送请求,以获取此书的详细数据。获取到详细数据后,在书籍详情页面,展示出书籍的标题、简介等详 细信息,并提供播放按钮、核实实际顺序。播放音频时将LRC文件与音频文件设置关联,并生成用于选取当前句子或下一句子锚点的函数,使得播放时可以根据音频的播放进度准确定位相应的句子,以此实现音频和文字的同步播放,并且分句比分字工作量大大减少,避免增加不必要的成本。
实施例2
如图2所示,实施例2在实施例1的基础上公开了一种有声读物逐句同步展示方法,该实施例2进一步限定了所述步骤S1的具体方法如下:
S1.1:获取有声读物对应的文本文件,按章节划分为若干初始文本;
S1.2:使用文本分句模块11,将各章节的初始文本转换为分句文本;
S1.3:使用LRC文件制作模块12,审听音频的同时在初始文本上的分段位置和分句位置标记相应的时间戳,制得LRC文件。
其中所述步骤S1.2的具体方法如下:
S1.2.1:通过分句算法,识别初始文本中的分段位置和分句位置,并添加标识点;
S1.2.2:根据标识点将初始文本拆分,得到分句数组;
S1.2.3:以行为单位,将分句重新放入不同的行,得到分句文本。
本实施例中所述的文本分句模块11可以是Python或Java Demo或其他任何可以用于文本分句的软件,所述LRC文件制作模块12可以是千千静听或酷狗音乐或其他任何LRC编辑器。
首先根据章节将有声读物的文本文件拆分,并分别将每一章节制成LRC文件,使用者可以根据需要获取相应章节的LRC文件,不需要一次下载全部文件,节约存储空间且使用更加方便;通过将文本文件 分句并添加相应的时间戳,将各个句子与音频进行对应,可以精确定位句子播放时间,同时分句比分字工作量大大减少,避免增加不必要的成本;将不同的句子放入不同的行中进行排列,即每一行为一个句子,使用时可以直接通过调取行来选取指定句子,使用更加精确、方便。
实施例3
如图3所示,实施例3在实施例1的基础上公开了一种有声读物逐句同步展示方法,该实施例3进一步限定了所述步骤S2的具体方法如下:
S2.1:在服务器2中添加有声读物的基本信息和章节信息,;
S2.2:将制作好的LRC文件上传至服务器2中,并与对应的章节信息进行关联。进行关联的具体方法如下:
有声读物的基本信息包括标题、简介、作者、演播、章节信息等,其中章节信息又包括章节标题、章节序号、章节简介、相关音频文件、音频文件时长、音频文件大小等信息。将LRC文件与相应的章节信息进行对应,当选择某个章节时,即可同时调出该章节对应的全部信息,包括基本信息、相关的音频信息和LRC文件,获取信息更加方便、准确。
实施例4
如图4所示,实施例4在实施例1的基础上公开了一种有声读物逐句同步展示方法,该实施例4进一步限定了所述步骤S3的具体方法如下:
S3.1:用户在客户端3点播指定的书籍,客户端3的网络交互模块31向服务器2发送请求,以获取此书的详细数据;获取到详细数据后,在书籍详情页面,展示出书籍的标题、简介等详细信息,并提供播放按钮;
S3.2:客户端3对章节信息进行加载,同时将相应的LRC文件下载到本地并进行加载;
S3.3:加载完成后,客户端3进入监听状态,将所述LRC文件中的所有时间戳转换成链接锚点并组成锚点数组;基于当前播放时间和锚点数组,实现一个获取当前句子的算法函数getCurrentSentence(),以及一个获取后序句子时间锚点的算法函数getNextSentencePosition(),在播放音频文件的同时调整LRC的播放进度,以实现LRC文件中的文本与音频的逐句同步显示。
S3.4:当用户点击文本时,客户端3获取对应的句子,读取句首的链接锚点,解析出其中的时间戳信息;根据时间戳的值,控制音频的播放进度到相应的位置,以实现文本的选句点读功能。
如图5所示,所述步骤S3.3的具体方法如下:
S3.3.1:将LRC文件中的文本以行作为单位进行合并,生成完整的电子文本;
S3.3.2:将文本中的时间戳转换成链接锚点,并隐藏其显示;
S3.3.3:抽取文本中的所有时间戳锚点,并保存成锚点数组;
S3.3.4:客户端3基于锚点数组和当前时间,实现一个获取当前句子的算法函数getCurrentSentence();
S3.3.5:客户端3基于锚点数组和当前时间,实现一个获取后序句子时间锚点的算法函数getNextSentencePosition();
S3.3.6:客户端3监听当前音频文件的播放进度,当播放进度更新时,调用getNextSentencePosition()函数,获取后序句子切入的时间戳位置,如果当前进度小于此时间戳位置,则保持当前句子的高亮显示;如果当前进度已经大于或等于此时间戳位置,则调用getCurrentSentence()函数,获取要切换显示的句子,在客户端3更新高亮显示。
具体实现方法如下:
将文本中的时间戳转换成链接锚点,并全部抽取组成锚点数组,由此可获取全部时间戳信息;客户端3基于锚点数组和当前播放时间,分别生成获取当前句子和后续句子时间锚点的算法函数,并通过生成的函数获取相应的句子,同时对选取的句子进行高亮显示,由此实现音频和文字的同步播放。同时由于每个句子均添加有对应的链接锚点,并且与有声读物的音频文件以及其他信息相关联,因此当选择特定的句子时,可通过链接锚点解析出相应的时间戳,并将音频定位到相应位置,由此实现点播选播的功能。
实施例5
如图6所示,本发明实施例5提供了一种有声读物逐句同步展示 系统,包括文件源1、服务器2以及客户端3,所述文件源1用于将有声读物对应的文本文件制作成LRC文件,包括:
文本分句模块11,用于将初始文本转换为分句文本;
LRC文件制作模块12,用于将分句文本制作成LRC文本;
所述服务器2用于存储有声读物的基本信息、章节信息和LRC文件,接收客户端3索要有声读物的请求,并将相应文件发送给客户端3,包括:
书籍管理模块21,用于管理有声读物的基本信息、音频信息和LRC文件,并将所述LRC文件与所述章节信息进行关联;
所述客户端3用于对有声读物的音频文件和LRC文件进行播放和进度调整,以实现LRC文件与音频文件的逐句同步显示以及选句点读功能,包括:
网络交互模块31,用于向所述服务器2发送索要有声读物的请求,并接收相应信息;
播放器32,用于同步播放有声读物的音频文件和LRC文件。
本实施例提供的有声读物逐句同步展示系统中,首先由文件源1将文本文件转换为分句文件,再将分句文件制作成LRC文件,并添加相应的时间戳;服务器2接收LRC文件,并将LRC文件与音频文件设置关联;客户端3的网络交互模块31从服务器2获取所需的音频文件和相应的LRC文件,根据LRC文件的锚点数组生成用于选取相应句子的函数播放器32在播放音频时可以根据音频的播放进度准确定位相应时间点的句子,以此实现音频和文字的同步播放。
实施例6
如图7所示,实施例6在实施例5的基础上公开了一种有声读物逐句同步展示方法,该实施例6进一步限定了所述服务器2包括:
章节信息管理子模块211,用于根据章节添加有声读物所包含的基 本信息和音频信息;
LRC文件管理子模块212,用于上传LRC文件,并将LRC文件与各章节的基本信息和音频信息进行关联。
所述播放器32包括文本同步展示模块321,所述文本同步展示模块321用于加载LRC文件,并调整LRC的播放进度,以实现LRC文件中的文本与音频的逐句同步显示。
文件同步展示组件321加载完成全部数据后,将文本中的时间戳转换成链接锚点,并全部抽取组成锚点数组,获取全部时间戳信息;然后基于锚点数组和当前播放时间,分别生成获取当前句子和后续句子时间锚点的算法函数,并通过生成的函数获取相应的句子,同时对选取的句子进行高亮显示,由此实现音频和文字在播放器32的同步播放。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!