一种精准获取LLR信息的应用方法与流程
本发明涉及信息存储领域,尤其涉及一种精准获取nandflash的llr信息的应用方法。
背景技术:
目前的nandflash控制器nfc(nandflashcontroler)中已经开始使用低密度奇偶校验码ldpc(low-densityparity-check)码作为纠错码。与bch码(bose、ray-chaudhuri与hocquenghem的缩写,bch码是用于校正多个随机错误模式的多级、循环、错误校正、变长数字编码)相比,ldpc码在纠错能力方面有更大的优势,尤其是多bitldpc。从nandflash中获取对数似然比llr(loglikelihoodratios)信息的精准度直接影响ldpc译码的效果。目前是根据nandflash厂商提供的llr进行译码,或者不断尝试用不同的llr进行译码,并没有一套有效获取llr的解决方案,获取的llr的精度都不高,因此也影响了ldpc的译码效果。
技术实现要素:
针对以上缺陷,本发明目的在于如何精准的获取nandflash中的llr信息,进而实现估算多bitllr信息的。
为了实现上述目的,本发明提供了一种精准获取llr信息的应用方法,其特征在于包括统计样本选取,计算每个样本的optimalvref,通过设置多级多bit的读电压,将cell电压分布分为多个区域,计算每个区域对应的llr信息,并进行多bitldpc译码,通过比较不同读电压对应的多bitldpc译码的迭代次数和译码结果,将迭代次数最少且译码正确的读电压记录为多bit的最优读电压,对应的llr信息为该批次产品的初始llr信息,该批次产品默认有限采用该最优读电压读取数据,采用所述初始llr信息对数据进行译码。
所述的精准获取llr信息的应用方法,其特征在于当对某个字线的数据读取时,采用初始llr信息对数据进行译码失败时,则增加数据恢复操作,所述数据恢复操作包括选取出现译码失败字线的同一个物理块中可以译码成功的其它字线作为恢复参考样本,计算恢复参考样本的optimalvref,通过设置多级多bit的读电压,将cell电压分布分为多个区域,计算每个区域对应的llr信息,并进行多bitldpc译码,通过比较不同读电压对应的多bitldpc译码的迭代次数和译码结果,将迭代次数最少且译码正确的读电压记录为该字线对应的多bit的最优恢复读电压,对应的llr信息为恢复llr信息,采用所述恢复llr信息和最优恢复读电压对译码失败的字线进行读取和译码。
所述的精准获取llr信息的应用方法,其特征在于多bit同一个存储单元的电压根据存储不同数据其电压落入不同的电压区域,在计算llr信息时,将统计样本或者恢复参考样本中具体物理存储单元分为低页、中间页和高页,在计算llr信息时根据不同页的物理特性进行不同的电压区域合并。
本发明通过增加统计获取经验值,作为正常译码时的参数,保证正常的读写nand的效率,当正常译码失败需要进行数据恢复时,该方案可以估计更准确的多bitllr信息,降低误码率,实现数据恢复。
附图说明
图1是统计阶段和数据恢复阶段流程图;
图2是从nand获取精准llr信息原理说明图;
图3是最优读电压的理论值示意图;
图4是获取写入到各个区域的cell电压分布图;
图5是通过统计法计算llr信息流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1是统计阶段和数据恢复阶段流程图;主要包括两部分,统计阶段和数据恢复阶段,统计阶段的目的是获取普遍适用于同一批次nandfalsh读取的电压和译码的llr信息。
统计阶段,对于同一批次的nand,由于其工艺物理条件等是相同的,所以随机选取的样本是具有代表性的;因此在需要统计的nandflash中随机抽取样本,计算每个样本的optimalvref,通过设置多级多bit的读电压,将cell电压分布分为多个区域,计算每个区域对应的llr信息,并进行多bitldpc译码,通过比较不同读电压对应的多bitldpc译码的迭代次数和译码结果,将迭代次数最少且译码正确的读电压记录为多bit的最优读电压,对应的llr信息为该批次产品的初始llr信息,该批次产品默认有限采用该最优读电压读取数据,采用所述初始llr信息对数据进行译码。
数据恢复阶段,其目的在于使用过程中实际优先采用了统计阶段获取的初始llr信息和最优读电压对数据进行读取和译码。当对某个字线的数据读取时,采用初始llr信息对数据进行译码失败时,则增加数据恢复操作。由于同一个block中的字线word_line的pecycle(一次program和erase称为一次pecycle)和retention(滞留时间,即nand中数据存放的时间)是差不多的,所以可以通过译码正确的word_line估计译码失败word_line。统计阶段和数据恢复阶段只是样本不同,使用的原理方法是一样的。数据恢复操作选取出现译码失败字线的同一个物理块中可以译码成功的其它字线作为恢复参考样本,计算恢复参考样本的optimalvref,通过设置多级多bit的读电压,将cell电压分布分为多个区域,计算每个区域对应的llr信息,并进行多bitldpc译码,通过比较不同读电压对应的多bitldpc译码的迭代次数和译码结果,将迭代次数最少且译码正确的读电压记录为该字线对应的多bit的最优恢复读电压,对应的llr信息为恢复llr信息,采用所述恢复llr信息和最优恢复读电压对译码失败的字线进行读取和译码
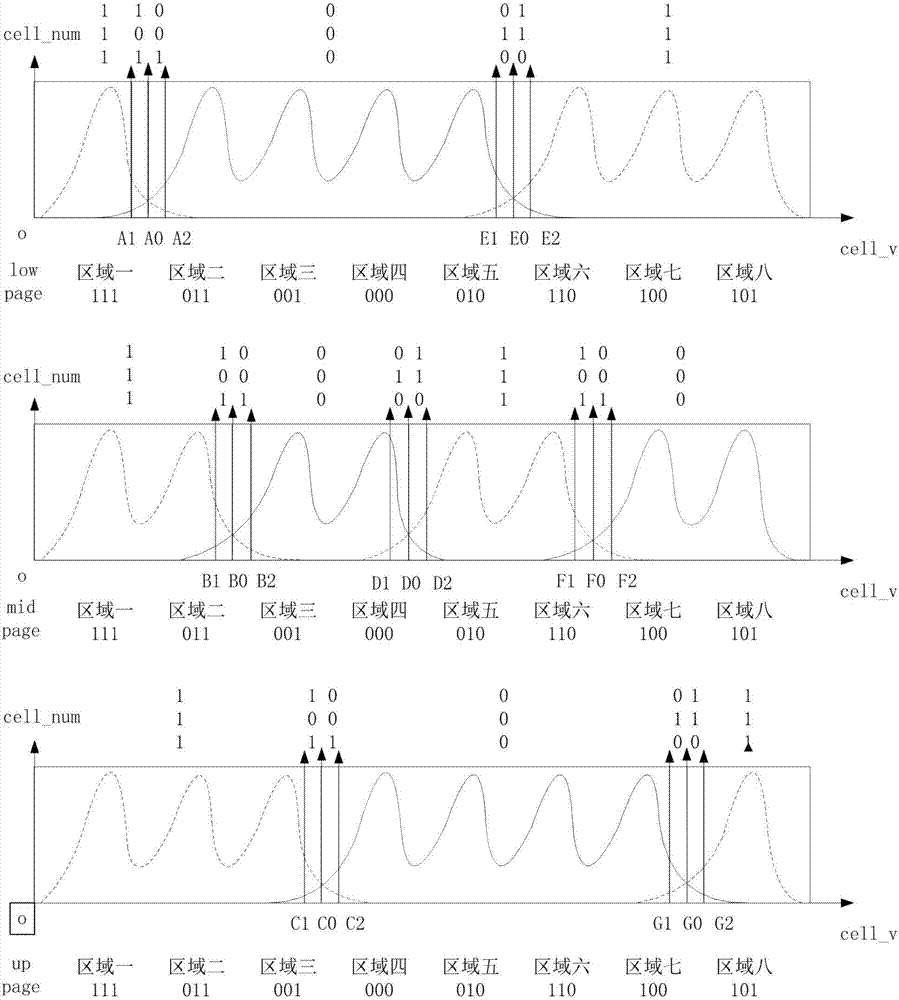
图2是从nand获取精准llr信息原理说明图;以tlc类型的nandflash为例进行说明,根据tlc原理,可将存储单元分为高页uppage、中间页midpage和低页lowpage类型,以每个存储单元可存储3bit信息为例,需要存储3bit信息,存储单元需设有7档读电压,将存储单元的电压划分为8个区域,分别为区域一、区域二、区域三、区域四、区域五、区域六、区域七和区域八,其中实线表示program写入为0时在各个区域的分布,虚线表示当写入为1时在各个区域的分布。区域划分方法是可变的,同时该方案适用于各种celltype的nandflash(例如slc、mlc、tlc、qlc以及未来单个cell存储容量更大的nandflash等。
图4是获取写入到各个区域的cell电压分布图,当program的时候,曲线表示program到各个区域的cell电压分布。npx_ry表示program到区域x读出在区域y的数据个数。
图3是最优读电压的理论值示意图,横坐标表示cell的电压值,纵坐标表示cell的个数,曲线w1表示写入数据为1的cell的电压分布图,曲线w0表示写入数据为0的cell的电压分布图,vref1、vref2和vref3分别为3种读电压vref,cell电压值小于读电压vref的cell被读成1,大于的读成0。因此无论如何选取vref,总会存在0被误读为1和1被误读为0的情况,显而易见只有当vref选择为曲线w1与曲线w0的交叉点对应的电压即vref=vref3时整体出现误读的错误最少,这个值就是理论上的最优读电压。
图5是通过统计法计算llr信息流程图,以tlc类型nandflash为例,采用3组读电压获取多bitllr信息为例进行说明:
llr的原始计算公式为:
其中s表示program的原始数据,r表示读出来的数据
经推导得:
llr的最终表达式为:
其中nxy表示program为x读出为y的cell个数,公式物理意义为:
llr(0):ln(0变0的cell个数/1变0的cell个数);
llr(1):ln(0变1的cell个数/1变1的cell个数)。
通过统计的方式计算获得llr(0)和llr(0):首先进行初始化准备:将相关变量进行初始化工作,如:last_npx_ry=0;n=0;read_num=3;abcdefg=a0b0c0d0e0f0g0;分别在3种电压下分别:循环按照如下流程进行数据采集,直到n=read_num条件成立退出统计计算:读low、mid、uppage的数据,统计proagram到区域x读出在区域y的数据个数npx_ry;统计proagram到区域一读出在an和an-1之间的cell个数;cellnum=np1_r1-last_np1_r1...统计proagram到区域八读出在an和an-1之间的cell个数;cellnum=np8_r1-last_np8_r1;统计proagram到区域一读出在bn和bn-1之间的cell个数;cellnum=(np1_r1+np1_r2)-(last_np1_r1+last_np1_r2)...统计proagram到区域八读出在bn和bn-1之间的cell个数;cellnum=(np8_r1+np8_r2)-(last_np8_r1+last_np8_r2)...统计proagram到区域一读出在gn和gn-1之间的cell个数;cellnum=(np1_r1+…+np1_r7)-(last_np1_r1+…+last_np1_r7)...统计proagram到区域八读出在gn和gn-1之间的cell个数;cellnum=(np8_r1+…+np8_r7)-(last_np8_r1+…+last_np8_r7);ast_npx_ry=npx_ry;n=n+1;abcdefg=anbncndnenfngn。
当数据采集完成后,按low、mid、uppage进行合并统计计算,当统计低页时,区域一、区域六、区域七和区域八进行合并计算,区域二、区域三、区域四和区域五进行合并计算;当统计中间页时,区域一、区域二、区域五和区域六进行合并计算,区域三、区域四、区域七和区域八合并计算;当统计高页时,区域一、区域二、区域三和区域八合并计算,区域四、区域五、区域六和区域七合并计算。
以上所揭露的仅为本发明一种实施例而已,当然不能以此来限定本之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!