一种基于磁随机存储器的支持通用计算的存内计算系统的制作方法
本发明属于通用存内计算领域,特别涉及一种基于自旋转移力矩磁随机存储器(stt-mram)的面向通用计算的存内计算系统及计算方法。
背景技术:
在过去的几十年里,数据集的大小随着时间指数增长,对数据分析应用程序的计算需求越来越大。然而,对于传统的冯诺依曼架构,处理器和内存单元之间的数据通信开销导致了巨大的性能下降和能源消耗,称为冯诺依曼瓶颈。
为了克服数据通信瓶颈,一种广泛被认可的方法是将处理器嵌入到内存中,即存内计算。一些研究提出了基于sram和dram的存内计算方案,虽然大大减少了数据通信开销,但是作为易失性存储器,sram和dram的静态功耗成为影响其性能的重要因素,令其很难满足将来基于大数据的应用场景的超低功耗的需求。
近年来,大量的研究表明新兴的非易失性存储器(nvms),如电阻式随机存取存储器/忆阻器(rram)、相变存储器(pcm)、stt-mram等基于电阻的存储机制提供了固有的逻辑计算功能,从而能够在内存中嵌入高效的逻辑计算能力。同时这些非易失性存储器件具有非易失性、低功耗、高密度等的优势。以上优点使得基于非易失性存储器的存内计算架构有望从根本上革新计算和内存之间的关系。
目前基于非易失性存储器件的存内计算方案大多只能执行一些特定于应用程序的逻辑功能,例如,有些研究利用忆阻器件的交叉横杆结构可以有效地进行矩阵-向量相乘的特点,提出神经网络推理/训练处理器或加速器;有些研究利用非易失性存储器电阻器件的条件切换特性,提出架构支持布尔逻辑运算、定点加法和乘法计算等。然而,目前的神经网络不仅仅需要逻辑运算和定点运算,因此支持通用计算的存内计算架构更有意义。
技术实现要素:
为此,本发明一种磁随机存储器的支持通用计算的存内计算系统及计算方法,可以可重构地支持数据存取、逻辑运算、定点计算、浮点计算,并且降低功耗。
本发明提供了一种基于磁随机存储器的支持通用计算的存内计算系统,包括gcim架构,所述gcim架构包括自旋转移力矩磁随机存储器阵列、移位器和连接器、行译码器、列译码器、位线驱动器、计算字线数模转化器、预充电感应放大器、第五代精简指令集处理器、指令解析器和寄存器;
所述自旋转移力矩磁随机存储器阵列包括多个子阵列,每个子阵列由m行n列个存储单元组成,每个存储单元由2个晶体管和1个垂直磁各向异性磁隧道结组成;
所述移位器和连接器包括移位器和连接器,所述移位器包括桶形移位器和预充电感应放大器,所述预充电感应放大器连接所述自旋转移力矩磁随机存储器阵列的源线sls和存取位线mbls,用于读取判断数据和输出数据,将判断数据存储到所述寄存器,或者将输出数据发送至所述第五代精简指令集处理器;所述判断数据或输出数据是所述源线sls和所述存取位线mbls之间磁隧道结和参考磁隧道结的电阻大小;所述连接器用于连接所述移位器和相邻两个子阵列,可重构地调节所述多个子阵列的工作状态;
所述第五代精简指令集处理器用于向所述指令解析器发送工作命令,以控制可重构地调节所述多个子阵列的工作状态;同时接收所述预充电感应放大器和所述寄存器中的数据;
所述行译码器连接所述自旋转移力矩磁随机存储器阵列的存取字线mwls,用于在存取模式激活对应行的存储单元;所述列译码器连接所述位线驱动器用来同时激活相邻8个位线驱动器;所述位线驱动器连接所述自旋转移力矩磁随机存储器阵列的源线sls、存取位线mbls以及计算位线cbls,用于给不同字线提供相应电压;
所述计算字线数模转换器连接所述自旋转移力矩磁随机存储器阵列的计算字线cls,用于在计算模式为其提供相应电压;
所述指令解析器用于解析所述第五代精简指令集处理器的指令并相应地将其传输给所述移位器和连接器、所述行译码器、所述列译码器、所述位线驱动器、所述计算字线数模转化器和所述预充电感应放大器。
进一步,所述多个子阵列包括4个子阵列,每个子阵列由32行128列个存储单元组成。
进一步,所述可重构地调节所述多个子阵列的工作状态包括:两个子阵列之间连接移位器来实现移位操作;两个子阵列连接,像一个阵列一样工作;两个子阵列不连接,各自独立工作。
进一步,每列存储单元中,连接移位器和上下两个相邻存储单元的连接器由6个晶体管组成。
进一步,所述计算字线数模转换器由一个2比特数模转换器和2个晶体管组成,其为计算字线cls提供5种电压值:vnor,vnand,vnot,vmin和gnd。
本发明的有益效果:
1)本发明不仅可以在内存中实现存储,而且可以在内存进行计算操作;
2)本发明可有效支持通用计算(包括逻辑计算、定点计算、浮点计算等),充分利用多个子阵列结构和改进的移位器和连接器,可以提高本发明的通用存内计算架构(general-purpose-computing-in-memory,gcim)架构的可重构性和计算并行度,提高计算效率;
3)利用本发明所提出的gcim架构,能够实现一个8位浮点加法计算只需要426ns的时间和85.853pj的能量;实现一个8位无符号定点加法计算只需要136ns的时间和21.037pj的能量;同时如果利用本发明多个子阵列设计带来的并行度优势,4个子阵列可同时分别进行计算,由此平均每个8位无符号定点加法计算所需的时间会减少3/4。
附图说明
图1为本发明实施例的gcim架构整体示意图;
图2为本发明实施例的每个子阵列的结构示意图;
图3为本发明实施例的每个存储单元的结构示意图;
图4为本发明实施例的垂直磁各向异性磁隧道结的原理图;
图5为本发明实施例的改进的移位器和连接器的结构示意图;
图6为本发明实施例的改进的移位器的结构示意图;
图7为本发明实施例的预充电感应放大器的结构示意图;
图8为本发明实施例的计算字线数模转化器的结构示意图;
图9为本发明的两输入逻辑计算的原理图;
图10为图9的简化图;
图11为本发明实施例的4比特乘法计算过程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
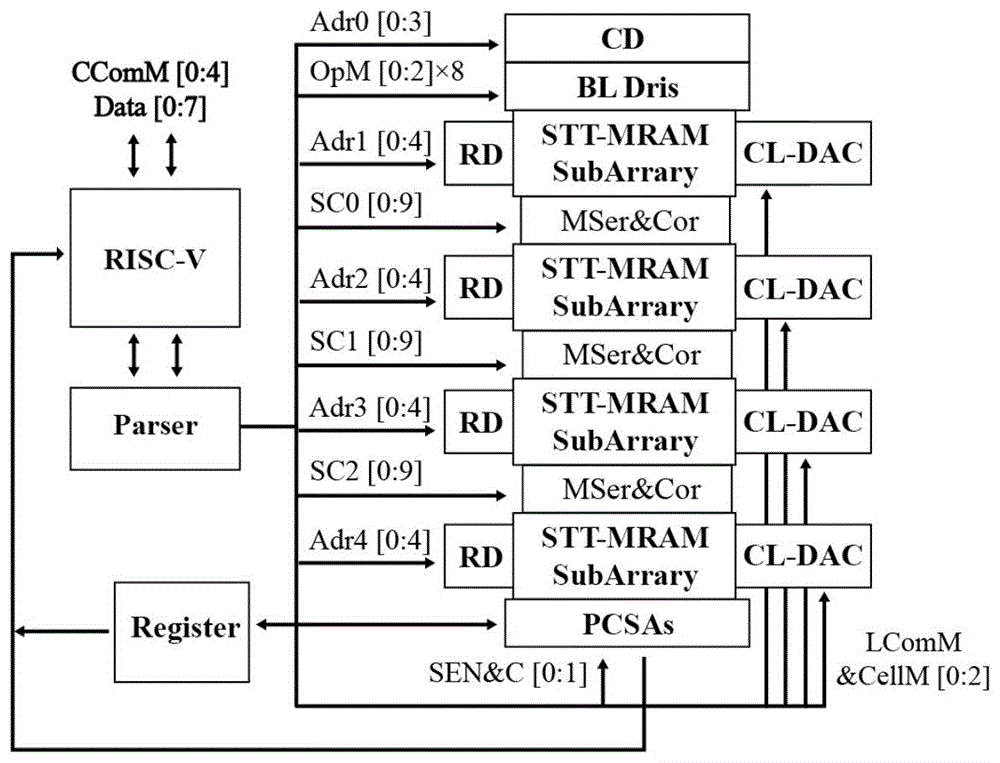
本实施例提出的基于自旋转移力矩磁随机存储器的面向通用计算的存内计算系统,包括自主设计的gcim架构。图1是本实施例的gcim架构整体示意图,其包括基于2晶体管1磁隧道结的自旋转移力矩磁随机存储器阵列(2t1mtjstt-mramarrary)、改进的移位器和连接器mser&cor(modifiedshifterandconnector)、行译码器rd(rowdecoder)、列译码器cd(columndecoder)、位线驱动器bldri(bitlinedriver)、计算字线数模转化器cl-dac、第五代精简指令集处理器rsic-v、指令解析器(parser)和寄存器(register)。
其中,自旋转移力矩磁随机存储器阵列包括4个子阵列,如图2所示,每个子阵列由32(行)x128(列)个存储单元组成,每个存储单元由2个晶体管和1个垂直磁各向异性磁隧道结组成。如图3所示,其中,源线sl既工作在存取模式,又工作在计算模式;存取字线mwl和存取位线mbl只工作在存取模式;计算字线cl和计算位线cbl只工作在计算模式。
图4示出了垂直磁各向异性磁隧道结的原理图,存储单元的垂直磁各向异性磁隧道结包括两个铁磁层(cofeb)以及两者之间氧化层(mgo)。其中,一个铁磁层的磁化方向是固定的,被称为参考层(referencelayer),另一个铁磁层的磁化方向可以与参考层的磁化方向相同(平行)或者相反(反平行),被称作自由层(freelayer)。如果自由层和参考层的磁化方向是相同的,则磁隧道结呈现低阻态(p),其电阻值rp较低,代表二进制数据“0”;如果自由层和参考层的磁化方向相反,则磁隧道结呈现高阻态(ap),其电阻值rap较高,代表二进制数据“1”。利用自旋转移力矩的机制,可以通过给磁隧道结施加极化电流来改变其状态,如果所施加的极化电流ip→ap从磁隧道结的自由层流向参考层,并且大小大于临界翻转电流ic0,则经过一定时间后,磁隧道结会从p状态变为ap状态;相反,如果所施加的极化电流iap→p从磁隧道结的参考层流向自由层,则磁隧道结会从ap状态变为p状态。
特别地,每列存储单元均利用由6个晶体管组成的连接器,连接改进的移位器(下文详细说明)和上下两个相邻存储单元。例如图5中所示第i列存储单元中,源线sli和存取位线mbli之间连接了3个nmos和3个pmos,并且pmos之间连接了改进的移位器,连接器信号c1、c2的逻辑值控制这6个晶体管导通或断开,进而控制相邻两个存储单元的连接状态,每列都是如此,则连接器信号c1、c2控制了上下两个子阵列的连接状态,从而可重构地调节多个子阵列的工作状态。具体地,连接器信号c1、c2的逻辑值为00,则两个子阵列之间连接改进的移位器来实现移位操作;连接器信号c1、c2的逻辑值为11,则两个子阵列连接,像一个阵列一样工作;连接器信号c1、c2的逻辑值为10,则两个子阵列不连接,各自独立工作。由此,本发明既可以支持移位操作,为计算需要移位的复杂操作(如乘法操作)提供方便,又提高了gcim架构的可重构性和计算并行度,提高了计算效率并降低了功耗。
本实施例改进的移位器如图6所示,由传统的桶形移位器和预充电感应放大器(pcsa)组成。桶形移位器上的信号s0、s1、s2、s3、s4……表示数据移动的位数,比如,如果信号s2为高电平,其他信号si(i=0,1,3,4……)信号为低电平,则数据会移动2位,从上方子阵列中由源线sl、存取位线mbl连接的存储单元,移动到下方子阵列中由存取位线mbl’连接的存储单元。
本发明通过预充电感应放大器可读取存储单元所存储的数据。如图7所示,本实施例中预充电感应放大器包括四个pmos、三个nmos和一个参考磁隧道结,该参考磁隧道结的电阻值(即参考电阻)为rref=(rp+rap)/2。如果源线sl和存取位线mbl之间的电阻大于参考电阻rref,则qm输出0而
特别地,计算字线数模转化器cl-dac如图8所示,其由一个2比特模数转化器和两个晶体管组成,用于在不同情况下向存储单元的计算字线cl传输相应的电压。图8中,计算字线数模转化器cl-dac的输入信号d1、d2的逻辑值00、01、10、11分别代表逻辑操作与非nand、或非nor、非not、求数量最少数min。根据输入信号d1和d2的输入,数模转化器dac输出相应的电压vnand、vnor、vnot、vmin。本发明的计算字线数模转化器cl-dac的输入信号cellm的逻辑值0,代表当前存储单元为操作数单元,存储了操作数,则计算字线cl输出dac依据输入信号d1、d2输出的电压值;输入信号cellm的逻辑值1,代表当前存储单元为结果单元,用来存储计算结果,则输出计算字线cl电压为0。
使用本发明的存内计算系统进行的所有复杂计算都是以数据存取和逻辑计算为基础,下面结合图3、9和10说明本发明的2晶体管1磁隧道结磁随机存储器的存取操作原理和逻辑计算原理:
1)存取操作原理:阵列工作在存取模式,图3中的源线sl和存取位线mbl与存取字线mwl及其连接的nmos工作,计算字线cl与计算位线cbl及其连接的nmos不工作。根据前述磁隧道结的翻转原理,在存取字线mwl为高电平,即存取字线mwl与存取位线mbl连接的nmos导通的情况下,通过给源线sl和存取位线mbl之间加一个合适的偏压来改变磁隧道结的状态,即写入“1”或“0”。源线sl和存取位线mbl连接到预充电感应放大器,便可通过预充电感应放大器的qm读出其存储的数据,通过
2)逻辑计算原理:图9是两输入逻辑计算的原理图,图10是图9的简化图。两个输入单元的磁隧道结input1和input2并联,然后和结果单元的磁隧道结result并联。在计算模式只有源线sl和计算字线cl与计算位线cbl及其连接的nmos工作,存取位线mbl与存取字线mwl及其连接的nmos不工作。根据计算类型,通过计算字线数模转化器cl-dac将两个输入单元的磁隧道结input1和input2中的计算字线cl0和cl1设置为相同的高压vop,并将结果单元的计算字线cl2电压设置为ground。经过一段时间后,可以将计算结果写入结果单元(计算前将结果单元初始化为低阻状态)。
本发明的这种内存计算机制在计算时将结果写入存储阵列,然后可以通过常规的读操作输出结果,其不同于现有的某些存内计算机制,即通过感应放大器计算结果,同时输出结果。有利地,本发明所采用的存内计算方法在计算有大量中间结果需要用于后续计算的复杂计算时,十分有优势,因为本发明不需要读出并重新写入中间结果,而是直接利用中间结果进行后续计算。下面表1-表3分别给出了nor、nand和not三种逻辑操作时计算字线cl电压的真值表和高压vop,其中,vnor表示或非操作所需要的计算字线cl电压);rp//rp是两个rp的并联电阻,rp//rp=(rp*rp)/(2rp);rap//rp是rap和rp的并联电阻,rap//rp=(rap*rp)/(rap+rp)。
表1.nor操作的真值表
表2.nand操作的真值表
表3.not操作的真值表
本发明利用所设计的gcim架构完成存取操作和通用计算,通用计算包括逻辑计算、全加计算(fa)、向前进位加法计算(rca)(完成无符号定点加法计算的一种方式)、有符号定点加法计算、有(无)符号定点减法计算、浮点加法计算、定点(浮点)乘法计算等。上面结合本实施例详细说明了存取操作,下面将详细说明如何利用本发明提出的gcim架构进行通用计算:
1.全加计算
根据下面的式(1)和式(2),本发明提出的gcim架构可以作为一个全加器(fa)工作。
cout=(min(a+b+cin))′(1)
s=axnorbxnorcin(2)
其中,cout表示输出的进位;s表示输出的和;a、b分别表示操作数;cin表示输入的进位。本发明通过2步操作(min和not)便可计算出进位cout,然后通过两个xnor操作便可计算出和s。下面表4示出了利用本发明的gcim架构,通过3步得到异或操作结果r=xnor(a,b)的过程,其中,存储单元ua和ub存储输入操作数a和b,存储单元ur0和ur分别用来存储中间结果和最终的异或操作结果,应该注意,在计算之前需要将存储单元ur0和ur初始化为0。具体包括:步骤1):对操作数a和b进行与非操作,设其结果为操作数r0,r0=nand(a,b),计算同时,结果写入存储单元ur0;步骤2):对操作数r0进行非操作not(r0),结果写入存储单元ur,此时存储单元ur存储了操作数a和b的与结果and(a,b);步骤3):以存储单元ua和ub为操作数单元,以存储单元ur为结果单元,进行或非操作,之后存储单元ur便得到了异或操作值xnor(a,b)。
表4.异或操作xnor(a,b)的计算过程
2.无符号定点加法计算
本发明提出的gcim架构也可以作为向前进位加法器(rca)工作,可以根据下式(3)和式(4)来完成无符号定点加法计算。
ci+1=(min(ai+bi+ci))′(3)
si=aixnorbixnorci(4)
其中,i代表操作数的第i个元素。
表5示出了计算一个8位无符号定点加法a+b的步骤。在表格中,row0和row1存储了8比特操作数a和b,row2用来存储进位数据ci,对row0,row1和row2中数据进行min操作的结过存储在row3。具体地,在步骤1)完成min操作得到ci+1’,并从pcsa的
表5.8比特定点加法计算a+b的计算步骤
3.有符号定点加法计算和减法计算
利用本发明的gcim架构,可以依据下式(5)和式(6)计算有符号定点加法和有(无)符号定点减法。
[d+e]补码=[d]补码+[e]补码(5)
[d-e]补码=[d]补码+[-e]补码(6)
其中,d、e为操作数。
具体地,通过以下3个步骤完成8比特有符号定点加法d+e:
步骤1):分别计算操作数d和e的补码。由于正数和负数计算补码的规则不同,首先用gcim架构中的pcsa读出操作数的符号位并存入寄存器,然后利用rsic-v依据符号位值决定是否对操作数进行“求反”和“+1”。gcim架构根据以下规则进行“+1”:从操作数的低位到高位读出数据,当读出的数据首次出现“0”,便在该位上写入“0”,并在其低位写入“1”,其他位保持不变。
步骤2):依据前述“2.无符号定点加法计算”方法计算无符号定点加法[d]complement+[e]complement。
步骤3):通过对步骤2)的结果求补码得到d+e的结果。
特别地,8比特有(无)符号定点减法d-e需要在步骤1)之前对操作数e的符号位求反,其他步骤与8比特有符号定点加法操作步骤相同。
4.浮点加法
一个浮点数n可以表示为
步骤1):根据前述“3.有符号定点加法计算和减法计算”提出的方法,将两个操作数的指数位xe和ye相减(xe-ye)。
步骤2):读出步骤1)的结果并且存储在寄存器为下一步的判断做准备。
步骤3):根据xe-ye结果的符号位,第五代精简指令集处理器rsic-v决定结果re的指数位,并决定哪个操作数的尾数位需要移动和移动的位数。例如:如果xe>ye,gcim架构会复制xe作为结果的尾数位re,并且在第五代精简指令集处理器rsic-v的控制下,将ym右移|xe-ye|位。为了方便后面的描述,令mm表示y的尾数ym右移之后的值。特别地,由于本发明的多个子阵列和改进的移位器和连接器的设计,上述移位操作可直接在存储阵列上完成。
步骤4):将mm和xm相加,其相加结果为r的尾数位rm,根据前述“2.无符号定点加法计算”中描述的向前进位加法,可以很容易得到rm。
另外,如果操作数是有符号数,在步骤4)中,将x和y的符号位分别作为mm和xm的符号位,进行有符号加法计算便可。
5.定点乘法和浮点乘法
图11是4x4华莱士树乘法点阵图,本发明提出的gcim架构可以根据图11中所示点阵图规则完成定点乘法,一个全加操作,即fa操作,需要三个1位输入,分别是a,b,cin,有两个1位输出s和cout,图中每个点表示1位,虚线框里a,b,cin的四个点,表示并行进行4个fa操作。
首先,gcim架构作为全加器(fa)计算出前三个部分积的和输出s和进位输出cout,如虚线方框所示;然后,gcim架构仍然作为全加器(fa)计算出已计算出的和输出s、进位输出cout和第四个部分积的和输出s与进位输出cout,如实线方框所示;最后,gcim架构作为向前进位加法器(rca)计算出最终结果。
综上,本发明的多个子阵列设计和改进的移位器和连接器设计,可以实现通过移动数据来对齐相应的位来保证全加计算和向前进位加法计算的结果的正确性。
此外,根据以上描述,本发明的gcim架构也可以很容易地计算浮点乘法:首先,对两个操作数的符号位进行异或操作得到结果的符号位;然后,对操作数的指数位进行有符号加法计算得到结果的符号位;最后,对两个操作数的尾数位进行定点乘法计算来得到结果的尾数位。
对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以对本发明的实施例作出若干变型和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!