存内计算装置及用于执行MAC操作的方法与流程
存内计算装置及用于执行mac操作的方法
技术领域
1.本技术一般涉及存算一体(compute-in-memory,cim)装置,以及更具体地,涉及可以执行乘法和累加(multiply and accumulate,mac)操作的cim装置。
背景技术:
2.深度学习、机器学习、神经网络和其它基于矩阵的可微程序用于解决各种问题,包括自然语言处理和图像中的目标识别。解决这些问题通常涉及基于矩阵向量乘法执行计算。例如,在具有多个神经元的神经网络中,输入到神经元的激活值可被视为输入激活向量,而来自神经元的输出激活值可被视为输出激活向量。该神经网络的计算通常涉及输入激活向量与权重矩阵的矩阵向量乘法,以计算输出激活向量。通常,权重矩阵可以是矩形的(rectangular),输出激活向量的长度不一定与输入激活向量的长度相同。神经网络的计算通常涉及对数据值(包括输入/输出激活向量和权重)执行的乘法和累加(multiply and accumulate,mac)操作的计算。mac操作是指两个值之间的乘法运算,以及,随后将一系列乘法结果累加以提供输出mac值。
3.大型深度神经网络的计算涉及许多不同数据值的大规模并行计算。计算操作(例如,算术或逻辑运算)通常由处理器基于处理器与存储装置(例如,存储器阵列)之间的数据传输进行。随着大规模并行神经网络的数据吞吐量要求增加,快速处理器与存储器的较慢数据传输有时可能成为机器学习应用的瓶颈。
4.内容可寻址存储器(content-addressable memory,cam)是一种为搜索密集型应用设计的计算器存储器。由于其并行特性,cam的搜索速度比随机存取存储器(random access memory,ram)架构快得多。cam通常用在互联网络由器和交换机中,它们可以提高路由查找、数据包分类和数据报转发的速度。三元cam或tcam被设计为使用三种不同的输入(0、1和x)来存储和查询数据。“x”输入(通常被称为“无关”或“通配符”状态)使得tcam基于模式匹配执行更广泛的搜索,而不是三元cam,其中,三元cam仅使用0和1执行精确的匹配搜索。
技术实现要素:
5.本发明提出了一种存内计算装置及用于执行mac操作之方法,以实现更高的计算吞吐量和更高的性能。
6.第一方面,本发明提供了一种存内计算装置,包括:存储器阵列,包括被布置成多个行的多个三态内容可寻址存储器tcam位单元,其中,每个tcam位单元包括两个静态随机存取存储器sram,每个sram被配置为将存储在其中的权重应用于输入激活以产生输出值;以及多条激活线,每条激活线互连到该多个行中的相应行的tcam位单元,且被配置为从位于该相应行内的每个tcam位单元中的两个sram接收输出值。
7.在一些实施例中,该存内计算装置还包括:加法器,具有多个加法器输入,每个加法器输入耦接到该多条激活线中的相应激活线,该加法器被配置为基于该两个sram的输出
值产生乘法累加mac值。
8.在一些实施例中,该多个tcam位单元中的每个tcam位单元包括:被配置为从第一条搜索线接收输入激活的第一sram和被配置为从第二条搜索线接收输入激活的第二sram。
9.在一些实施例中,该存内计算装置还包括多个反相器,其中,每条激活线经由该多个反相器中的相应反相器耦接到相应的加法器输入。
10.在一些实施例中,该存储器阵列内的tcam位单元是16晶体管16-t tcam位单元。
11.在一些实施例中,该存储器阵列被配置为接收输入激活向量和权重矩阵。
12.在一些实施例中,该输入激活向量的输入激活被提供给两个或更多个不同行的tcam位单元。
13.在一些实施例中,该输入激活向量是被以时分复用方式接收的。
14.在一些实施例中,在每个sram内,该输出值是基于该权重和该输入激活的乘积产生的。
15.在一些实施例中,该存储器阵列位于第一层中,该第一搜索线位于与该第一层平行的第二层中,以及,该多条激活线包括位于第三层中的导体,该第三层与该第二层平行且与该第二层偏离开。
16.在一些实施例中,该多个tcam位单元被布置在多个列中,以及,该存内计算装置还包括:路由电路,位于该多个列中的一个列的旁边,且被配置为将输入激活路由到该多个tcam位单元中的一些或全部。
17.在一些实施例中,该存内计算装置还包括:sram边缘单元,位于该多个tcam位单元的一行的旁边。
18.在一些实施例中,该存储器阵列包括:第一子阵列和沿列方向位于该第一子阵列下方的第二子阵列,该sram边缘单元位于该第一子阵列和该第二子阵列之间。
19.在一些实施例中,该存内计算装置还包括:路由电路,位于该多个行中的一行的旁边,且被配置为将输入激活路由到该多个tcam位单元中的一些或全部。
20.在一些实施例中,该存储器阵列包括:第一子阵列和沿列方向位于该第一子阵列下方的第二子阵列,以及,在该第一子阵列和第二子阵列之间没有sram边缘单元。
21.第二方面,本发明提供了一种用于执行乘法和累加mac操作的方法,其特征在于,该方法通过操作三态内容可寻址存储器tcam单元阵列来对输入激活向量和权重矩阵执行该mac操作,该tcam单元阵列中的多个tcam位单元被布置成多个行且每个tcam位单元包括两个静态随机存取存储器sram,以及,该方法包括:将多个权重存储在该tcam单元阵列内的多个sram中;利用该多个sram将输入激活向量与该多个权重相乘以产生多个输出值;利用激活线收集来自该多个行中的相应行的每个tcam位单元中的两个sram的输出值;以及对来自该激活线的输出值求和以产生mac值。
22.在一些实施例中,对来自该激活线的输出值求和包括:将该激活线耦接到加法器树。
23.在一些实施例中,该乘法的动作是以时分复用的方式执行的。
24.在一些实施例中,该乘法的动作包括:为tcam位单元中的第一sram提供来自该tcam单元阵列的第一搜索线的输入激活向量的第一输入激活;以及为该tcam位单元中的第二sram提供来自该tcam单元阵列的第二搜索线的输入激活向量的第二输入激活。
25.在一些实施例中,该乘法的动作还包括:向该多个行的两行或多个不同行的tcam位单元中的sram提供第一输入激活。
26.本领域技术人员在阅读附图所示优选实施例的下述详细描述之后,可以毫无疑义地理解本发明的这些目的及其它目的。详细的描述将参考附图在下面的实施例中给出。
附图说明
27.通过阅读后续的详细描述以及参考附图所给的示例,可以更全面地理解本发明,其中:通过阅读后续的详细描述和实施例可以更全面地理解本发明,该实施例参照附图给出。应当理解,附图不一定按比例绘制。出现在多个附图中的项目在它们出现的所有附图中由相同的附图标记表示。
28.图1是说明mac操作的示例性神经网络表示的示意图,该mac操作是利用本文公开的cim装置执行的。
29.图2是根据发明一些实施例示出的用在cim装置中以执行mac操作的示例性16晶体管(16-transistor,16-t)tcam位单元的示意图。
30.图3a是根据本发明第一实施例示出的使用tcam位单元阵列的cim装置架构的示意图。
31.图3b是示出图3a所示的相同cim装置的示意性电路图,并详细介绍了每个tcam位单元内的sram电路和输入激活总线架构。
32.图4a是根据本发明第二实施例示出的cim装置架构(在该架构中,以时分复用方式执行加法)的示意图。
33.图4b是根据本发明一些实施例示出的用于操作图4a所示的cim装置200的示例性时序示意图。
34.图5是根据本发明第三实施例示出的具有多个块(tiles)的cim装置的示意图。
35.图6是根据本发明第四实施例示出的具有带转置输入激活线路由方案的多个块的cim装置的示意图。
36.图7是根据本发明第五实施例示出的具有连续块架构的cim装置的另一变体的示意图。
37.图8是示出说明性计算装置1000的框图示意图。
38.在下面的详细描述中,为了说明的目的,阐述了许多具体细节,以便本领域技术人员能够更透彻地理解本发明实施例。然而,显而易见的是,可以在没有这些具体细节的情况下实施一个或多个实施例,不同的实施例可根据需求相结合,而并不应当仅限于附图所行举的实施例。
具体实施方式
39.以下描述为本发明实施的较佳实施例,其仅用来例举阐释本发明的技术特征,而并非用来限制本发明的范畴。在通篇说明书及权利要求书当中使用了某些词汇来指称特定的元件,所属领域技术人员应当理解,制造商可能会使用不同的名称来称呼同样的元件。因此,本说明书及权利要求书并不以名称的差异作为区别元件的方式,而是以元件在功能上的差异作为区别的基准。本发明中使用的术语“元件”、“系统”和“装置”可以是与计算机相
关的实体,其中,该计算机可以是硬件、软件、或硬件和软件的结合。在以下描述和权利要求书当中所提及的术语“包含”和“包括”为开放式用语,故应解释成“包含,但不限定于
…”
的意思。此外,术语“耦接”意指间接或直接的电气连接。因此,若文中描述一个装置耦接于另一装置,则代表该装置可直接电气连接于该另一装置,或者透过其它装置或连接手段间接地电气连接至该另一装置。
40.其中,除非另有指示,各附图的不同附图中对应的数字和符号通常涉及相应的部分。所绘制的附图清楚地说明了实施例的相关部分且并不一定是按比例绘制。
41.文中所用术语“基本”或“大致”是指在可接受的范围内,本领域技术人员能够解决所要解决的技术问题,基本达到所要达到的技术效果。举例而言,“大致等于”是指在不影响结果正确性时,技术人员能够接受的与“完全等于”有一定误差的方式。
42.本发明公开了用于执行mac操作的装置和方法,其利用tcam阵列作为存算一体(compute-in-memory,cim)装置。cim(存算一体)或存内计算(in-memory computation,或可互换地称为“存储器内计算”)是一种利用位于存储器阵列内的内部电路对数据执行计算而无需将此类数据发送至处理器的技术,与利用位于存储器阵列外部的处理器的计算相比,cim或存内计算可以实现更高的计算吞吐量和更高的性能。由于减少了外部处理器和存储器之间的数据移动,因此,cim还可以减少能源消耗(energy consumption)。在本发明实施例中,存算一体装置和存内计算装置的称呼是可互换的。
43.一些实施例涉及一种cim装置,其包括被布置成行(row)和列(column)的tcam位单元(tcam bit cells)的阵列(亦可互换地为tcam位单元阵列或tcam单元阵列,其包括被布置成行和列的多个tcam位单元)。每个tcam位单元具有两个静态随机存取存储器(static random-access memory,sram),如图2中示出的6-t sram+2个晶体管。权重矩阵中的权重可以作为电荷存储在tcam位单元的每个sram中。每个sram(如图2所示,这里描述的sram包括图2中标注的“6t sram”和对应的两个晶体管)可以作为乘法器(multiplier)操作,该乘法器执行存储的权重与施加到tcam位单元阵列中的搜索线的输入激活值之间的乘法(multiplication)。tcam位单元内的两个sram可以独立地操作以在它们各自的(respective)选择线上独立地接收两个输入激活值,并利用存储在每个各自的sram中的权重来执行乘法操作。可以理解地,本领域普通技术人员应当理解16-t tcam位单元的结构,其是熟知的,故本文不再详细描述tcam位单元的具体结构及功能。
44.在一些实施例中,同一行(same row)内的多个tcam位单元与激活线互连在一起,以接收输出值,该输出值为由一行tcam位单元内的sram执行的乘法的结果。针对mac操作的求和(summing)由耦接到激活线的加法器树(adder tree)提供。在一些实施例中,每行tcam位单元设置有相应的激活线,以从该行接收来自tcam位单元的输出乘法值。激活线耦接到用于mac操作的加法器树。
45.根据本发明的一方面,由于用于一行tcam单元的激活线与用于该行内的多个tcam位单元的多个选择线(其是在列方向上延伸的)相交(intersecting),因此,为了避免激活线和选择线之间的短路,激活线可以由导体(conductor)来实现,该导体被设置(disposed)在与用于tcam位单元阵列的基板内的选择线所处层/平面不同的层(layer)/平面(plane)中,例如,位于较高的金属层中。一个或多个垂直通孔结构可以被提供,以将激活线耦接到相应的tcam位单元来接收输出值。
46.一些方面涉及cim装置执行mac计算的操作。一方面涉及基于要执行的mac操作将权重矩阵中的权重编程到tcam位单元阵列的sram中。在一些实施例中,输入激活向量中的输入激活值被提供给不同行的tcam位单元。由于每个tcam位单元提供两个sram存储两个权重,因此,与两个权重的乘法运算可以是以时分复用的方式执行的。在一示例中,控制器可以使得两个乘法运算是在一个时钟周期内的不同的非重叠时期(different non-overlapping phases)执行的,以产生时间复用输出值。在这样的示例中,可以在完成乘法之后的时钟周期中执行该时间复用输出值的加法。
47.在一些实施例中,cim装置包括tcam位单元阵列的多个子阵列(sub-arrays)或组(tiles)。在第一实施例中,第一块沿列方向位于第二块之上,cim装置包括将这两个块分开的sram边缘单元(sram edge cell),以使得相邻的第一块和第二块之间的搜索线可以用于独立地提供不同的输入激活向量。在这样的实施例中,输入激活向量通过沿一列tcam位单元的路由/布线电路(routing circuit)可以沿块的一侧水平地布线/路由。在另一实施例中,输入激活向量的路由可以是利用跨不同块的列来提供的。在这样的实施例中,由于搜索线能够跨相邻块共享,因此,相邻块之间不需要sram边缘单元且可以实现更高的阵列效率。
48.一些方面可以利用针对tcam位单元的现有代工厂设计而没有硬件改变或做较少的硬件改变,这可以降低所公开的cim装置的设计和制造成本。
49.本文公开的实施例可用于人工智能(artificial intelligence,ai)应用中的神经网络的计算,下面详细描述一些示例。应当理解的是,本发明实施例还可以用于其它应用,例如但不限于图像处理、图像分类和利用相机捕获的图像人脸识别。在一些实施例中,cim装置是移动设备的一部分。
50.下文进一步描述上述方面和实施例,以及附加方面和实施例。这些方面和/或实施例可以被单独使用、一起使用或以两个或更多个的任意组合使用,本发明对此不做限制。
51.图1是示例性神经网络表示的示意图,其示出了利用本文公开的cim装置执行的mac操作。图1示出了输入激活向量(a0,a1,a2,a3),它可以表示来自前一层的四个输入激活值。神经网络应用权重矩阵其中,每个权重w
i,j
分别表示用于相应的输入激活和神经元的权重。神经网络基于输入激活向量与权重矩阵的向量矩阵乘法(vector-matrix multiplication)产生输出激活向量(n0,n1,n2,n3),其具有用于下一层(next layer)的四个相应神经元的四个输出值n0...n3。向量矩阵乘法可以是利用mac运算执行的。应该理解的是,虽然图1示出的是4x4的方形权重矩阵,但这仅用于说明目的,本发明并不限于此示例。可以理解地,前一层(previous layer)的神经元的数量可与下一层的神经元的数量不同,以及,输入激活向量和输出激活向量可以具有任何合适的大小(size,亦可互换地称为“尺寸”)和/或维度(dimension)。
52.图2是根据一些实施例示出的可以用在cim装置中用于执行mac操作的示例性16晶体管(16-transistor,16-t)tcam位单元的示意图。图2示出了包括第一sram 101和第二sram 102的tcam位单元110。tcam位单元110是16-t tcam位单元,其中,sram 101、102中的每一个可被实现为6-t sram加2个相应的晶体管。应当说明的是,现在已知或未来开发的tcam位单元的任何代工设计均可以用于tcam位单元110,本发明在这方面不受任何限制。
53.如图2所示,用于对tcam位单元110进行编程的任何已知技术可用于在sram 101、102上存储电荷q0和q1,其中,q0和q1的位值(bit value)可表示权重矩阵的两个权重值。第一sram 101从第一搜索线(search line)sl接收第一输入值,而sram 102从第二搜索线slb接收第二输入值b。在本发明实施例中,sram 101、102中的每一个可以作为输入值与存储电荷的独立乘法器来操作,其中,输出值被提供在sram 101和sram 102共享的公共输出节点(common output node)103处。例如,反相输出节点mult通过反相器130耦接到公共输出节点103。本领域普通技术人员应当理解,tcam位单元110相当于是对存储的权值q0与从第一搜索线sl接收到的第一输入值相乘然后再反相,从而,tcam位单元110的输出值经由反相器130后的mult相当于是q0与第一输入值的乘积。也就是说,tcam位单元110相当于执行了乘法操作和反相操作,本领域普通技术人员可以理解,其也是属于乘法器操作。如图2中的真值表1011所示,mult的位值表示第一输入值a与第一sram的权重q0的乘积。例如,当第一输入值a和权重q0都为1时,mult才为1。如图2中的真值表1021所示,mult的位值表示第二输入值b与第二sram的权重q1的乘积。尽管图2的真值表示出了具有单个位(single bit)权重q0和q1的乘法,但多位乘法也是适用的,例如,通过将多个位值存储在sram中的电容器中。
54.根据一方面,当tcam 110用在cim装置中时,输入值a和b独立地应用于sl和slb,从而使得sram 101、102两者可以执行独立的乘法。此操作不同于某些使用tcam的非cim操作,例如,存储或搜索,其中,sl和slb彼此不是独立操作的。可以使用用于独立控制将不同输入值路由到sl和slb的任何合适技术。在一示例中,输入值可以被顺序地提供,或者,以时间复用的方式提供,以使得在一时间段内,只有一个乘法操作在tcam 110内执行。
55.图2还示出了跨两个搜索线sl和slb且水平延伸的激活线120,以将公共输出节点103互连到反相器130的输入。在一些实施例中,为了避免激活线120与搜索线sl、slb之间的短路,激活线120被实施为在金属层中延伸的导体ml,其中,该金属层位于偏离(offset)于搜索线sl和slb所在的层/平面的不同层/平面(在本发明中“层”和“平面”可互换地使用)中,且平行于tcam 110的半导体基板(substrate)的表面。在非限制性示例中,激活线120被设置在/位于(is disposed in)m3金属层中。换句话说,在一些实施例中,存储器阵列、搜索线以及激活线分别位于不同的金属层。在tcam 110使用现有代工厂tcam设计的实施例中,激活线120被添加而不显著增加整个存储器阵列的电路设计的成本或复杂性。
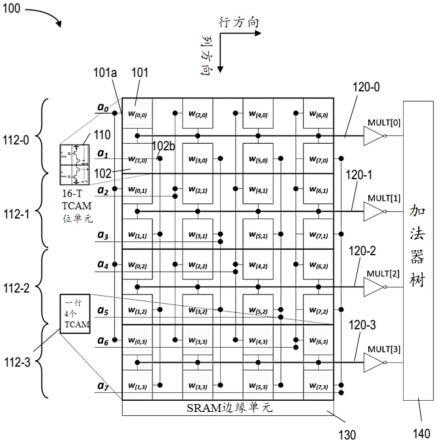
56.图3a是根据本发明第一实施例的利用tcam位单元阵列的cim装置架构的示意图。图3a示出了cim装置100,其包含排列成四行四列的tcam位单元阵列110。在第一行112-0内,四个tcam位单元的输出节点一起互连到激活线120-0,激活线120-0是沿行方向延伸的。激活线120-0通过反相器耦接到加法器树(adder tree)140,并将反相输出mult[0]提供给加法器树140。
[0057]
图3a说明了将权重矩阵的权重加载到tcam位单元阵列的不同sram位置以及输入激活值的路由(routing)的示例,以在8位输入激活向量(a0,a1,
……
a7)与8x4权重矩阵之间执行向量矩阵乘法。图3a中的tcam位单元阵列被配置为采用8个不同的输入激活值a0、a1、
……
a7,它们沿着最左边的列进行路由。例如,利用第一行112-0,第一输入激活值a0被提供在第一sram 101的搜索线101a处,第一sram 101将a0与权重w(0,
0)相乘。第二输入激活值a1被提供在第二sram 102的搜索线102b处,第二sram 102将a1与权重w(1,0)相乘。来自两个sram 101、102的乘法的结果作为输出值提供给激活线120-0作为mult[0]。加法器树140被配置为从mult[0]接收乘积a0
·
w(0,0)和a1
·
w(1,0)并相应地执行累加操作。
[0058]
仍然参考图3a中的第一行112-0,其说明了第一行内的8个sram中的每一个如何分别耦接到8个输入激活值a0、a1、
……
a7中的其中一个的激活总线架构。在操作期间,每次提供8个输入激活值。例如,路由电路可以仅激活对应于其中一个输入激活值的搜索线,而禁用其余7个输入激活值的搜索线。第一行112-0中的四个tcam位单元中的sram的8个乘积被表示在mult[0]中。加法器树140基于a0
·
w(0,0)+a1
·
w(1,0)+a2
·
w(2,0)+a3
·
w(3,0)+a4
·
w(4,0)+a5
·
w(5,0)+a6
·
w(6,0)+a7
·
w(7,0)累积mult[0]中的乘积,以提供mac值n0。
[0059]
仍参考图3a,其示出了tcam位单元的剩余三行112-2、112-2、112-3中的每一行经由对应的激活线120-1、120-2、120-3耦接到加法器树140。值得注意的是,每个输入激活值仅被提供给每行内的其中一个sram,以及,输入激活值被提供给四行中的每一行。因此,可以在四个行中同时执行四个乘法运算,以产生四个mult值,且四个mult值可并行地输出到加法器树140。
[0060]
图3b是示出图3a所示的相同cim装置的示意性电路图,并详细介绍了每个tcam位单元内的sram电路和输入激活总线架构。例如,图3b示出了左上tcam位单元的第一sram耦接到第一搜索线(search line)101a,而同一tcam位单元的第二sram耦接到第二搜索线102b。
[0061]
基于tcam的cim装置100可以提供若干优点。cim阵列架构具有高度的可扩展性,以给具有不同矩阵和向量大小要求的跨不同技术代的应用提供灵活性。例如,虽然图3a示出了具有8x4权重矩阵的mac操作,但cim装置100可以被扩展为能够适应任何大小的权重矩阵。例如,通过增加更多的4行tcam位单元,可以使用8
×
8权重矩阵。类似地,可以通过将四行中的每一行扩展到具有8个列来计算16
×
4权重矩阵。激活线120-0的长度可以沿着行方向增加以容纳额外的列。可以基于现在已知或未来开发的任何合适的sram/tcam读/写电路架构来提供大量乘法器单元,以受益于tcam位单元阵列的高存储密度。例如,可以通过使用阵列内的更多位单元列和行,和/或通过使用如下所述的一组子阵列来提供缩放。
[0062]
返回参考图3a,在行112-3下方提供有sram边缘单元(edge cell)130。边缘单元130可以提供四行112-0、112-1(第二行)、112-3(第三行)、112-3(第四行)与附加电路(例如,位于图3a所示的边缘单元130下方的不同块中的附加行tcam位单元)之间的电隔离。
[0063]
图4a是根据本发明第二实施例示出的在cim装置架构中以时分复用方式执行加法运算的示意图。图4a示出了具有两行212-0、212-1的cim装置200,其中,每行具有4个tcam位单元。在第一行212-0中,激活线220-0耦接到每个tcam位单元,以将输出值mult[0]提供给加法器树240。
[0064]
cim装置200允许一个输入激活值(例如,a0)与不同权重的时间复用乘法。如图所示,与a0的乘积被配置为分两个阶段执行。例如,a
0_p1
被提供给sram201中的w(0,0),而a
0_p1
被提供给与sram 201位于相同行212-0内的sram 202中的w(0,2)。乘法a0
·
w(0,0)和a0
·
w(0,2)可以在不同的时间执行,例如,在两个不重叠的阶段。这在图4b中进行说明,图4b为根据一些实施例的用于操作图4a所示的cim装置200的示意性时序图。
[0065]
图4b示出了乘积a0
·
w(0,0)和a0
·
w(0,1)可以在时钟周期262的第一时期264的期间并行执行,在第一时期264中,a
0_p1
是有效的(active)而a
0_p2
是被禁用的(disabled)。可以在时钟周期262的第二时期266的期间执行乘积a0
·
w(0,2)和a0
·
w(0,3),在第二时期266中,a
0_p2
是有效的而a
0_p1
是被禁用的。时钟周期262可以是由cim装置200内的电路提供的时钟信号clk,但本发明并不限于此,即可以使用任何合适的时序信号。
[0066]
在图4a所示的第二实施例中的权重矩阵映射(以适应时分复用操作)还与图3a所示的第一实施例中的权重矩阵映射是不同的。因此,不同于cim装置100,在cim装置200中,一个输入激活值a0与不同权重的乘法输出值通过单个激活线互连,而不是cim装置100中的多个激活线。例如,在图4a中,a0
·
w(0,0)和a0
·
w(0,2)这两者都通过第一行中的激活线220-0互连到mult[0],而该相同的乘积需要图3a中的两行mult[0]和mult[2]。因此,第二实施例可以提供优于第一实施例的一些优点。由于需要更少的行数,可以使半导体基板沿列方向上的加法器高度更紧凑,从而提高半导体基板上的面积利用率。作为另一个优点,由于针对w(0,0)和w(0,2)的sram在不同的时间阶段切换,因此,在给定时间处切换的位单元数量更少。因此,随着时间的推移,开关电流可以更均匀地分布,从而降低平均开关电流并降低局部电阻性ir压降。同时,由于第二实施例并行进行的计算更少,因此与第一实施例相比,计算更慢。
[0067]
图5是根据本发明第三实施例示出的具有多个组(tiles,或可互换地称为“块”)的cim装置的示意图。如图5所示,cim装置300包括四个块(或子阵列)301、302、303、304的tcam位单元。每个块在很多方面类似于图3a中所示的tcam位单元阵列。激活输入值a0提供给块301是通过位于块301左边缘且平行于列方向的路由电路351进行路由的(routed)。激活输入值a1提供给块302是通过位于块302的左边缘且平行于列方向的路由电路352进行路由的。块302位于块301下方,并通过一个或多个sram边缘单元130与块301分隔开,以切断一个块中的选择线延伸到不同块中,从而在不同的激活输入之间提供电隔离。该块可以是利用图3a所示的第一实施例,图4a所示的第二实施,两个实施例的组合,或tcam位单元阵列的任何其它合适的布置实现的。
[0068]
在图5中,路由电路351可以是解复用器(demultiplexer),用于基于例如从控制器(未示出)传输到解复用器的3位(3-bit)控制输入信号将a0引导到用于输入激活值的八个不同输入之一。应当理解的是,可以使用用于将信号路由到另一电路的多个输入的任何合适的译码电路(decoding circuitry)。在一示例中,路由电路351可以包括字线译码器(word-line decoder)。
[0069]
图6是根据本发明第四实施例示出的利用转置的(transposed)输入激活线路由方案以及包括多个块的cim装置的示意图。如图6所示,cim装置400与图5中的cim装置300不同,不同之处在于:利用位于阵列401底行(bottom row)旁边的路由电路451,输入激活值是从阵列401下方路由的。由于输入线的这种垂直路由,tcam位单元的阵列401可以垂直延伸成多行(例如,如图6所示的64个sram行),而不被分解为8位或4位子阵列(这些子阵列由sram边缘单元分隔开以进行隔离)。由于行之间没有sram边缘单元占用空间,本实施例可以大大提高区域利用效率。
[0070]
权重矩阵阵列401的配置可以相对于输入激活值的路由进行编程,类似于图3a所示的第一实施例,图4a所示的第二实施例,两个实施例的组合,或tcam位单元阵列的任何其
它合适的布置,以提供输入激活向量与权重矩阵的mac操作。
[0071]
在图6中,每行tcam位单元的输出值通过沿行方向的水平激活线互连到4位加法器440,4位加法器440又连接到加法器树442,加法器树442被配置为对加法器树接收到的值进行累加。可以理解地,加法器的作用是进行相邻两个激活值运算结果(4-bit)求和,而加法器树则是将加法器的输出进行累加。二者的功能相同,但结构有所不同,后者会在多级累加的过程中优化逻辑,减小面积,延时和功耗,本领域普通技术人员应当理解加法器和加法器树的结构,因此,本文不再详细描述。
[0072]
图7是根据本发明第五实施例示出的具有连续块架构的cim装置的另一变体的示意图。在图7中,cim装置500包括在行和列方向上延伸的连续的tcam位单元阵列501、502。输入激活向量的路由由位于阵列501下方并在阵列501的底行旁边的路由电路551提供。类似于图6中的实施例,输入数据的这种垂直布线允许存储器块沿列方向堆叠以针对每条位线提供32、64、128、256行或更多行。关于输出,可以提供4位加法器540的阵列且其沿列方向排列,以及,累加运算进一步由加法器/累加器542提供。由于sram边缘单元的使用被最小化,因此,与图5中的第三实施例相比,图7的连续块架构可以实现显著的面积利用效率。
[0073]
图8是示出其中可以实践一些实施例的说明性计算装置1000的框图示意图。在图8中,计算装置1000可以是台式计算器、服务器或诸如机器学习加速器之类的高性能计算系统。计算装置1000也可以是便携式、手持或可穿戴式电子装置。在一些实施例中,计算装置1000可以是智能手机、个人数字助理(personal digital assistance,pda)、平板计算机、智能手表。计算装置1000可以由诸如可充电电池的电池供电。计算装置1000也可以是通用计算器,因为本技术的方面不限于便携式装置或电池供电的装置。计算装置1000可以是能够根据本文公开的任何实施例执行mac操作的cim装置。
[0074]
计算装置1000包括具有一个或多个处理器的中央处理单元(central processing unit,cpu)12,具有一个或多个图形处理器的图形处理单元(graphics processing unit,gpu)14以及存储器(例如,非暂时性计算器可读存储介质)16,例如,其包括易失性和/或非易失性存储器。存储器16可以存储一个或多个指令以对cpu 12和/或gpu 14进行编程以执行本文所描述的任何功能。存储器16可以包括一个或多个tcam位单元阵列,其可以执行根据本文上述公开的mac操作。存储器16还可包括路由电路及一个或多个存储器控制器,其被配置为路由输入激活值和加法器树的编程操作。
[0075]
计算装置1000可以具有一个或多个输入设备和/或输出装置,例如,如图8所示的用户输入接口(user input interface)18和输出接口(output interface)17。这些装置可用于呈现用户界面。可用于提供用户界面的输出接口的示例包括用于视觉呈现输出的打印机或显示屏、用于输出声音的扬声器或其它声音生成装置,以及用于呈现触觉输出的振动或机械运动发生器。可用于用户界面的输入界面的示例包括键盘和指示装置,例如鼠标、触摸板或用于笔、触笔或手指触摸输入的数字化仪。作为另一示例,输入接口18可以包括用于捕捉音频信号的一个或多个麦克风、一个或多个相机和用于捕捉视觉信号的光传感器,以及,输出接口17可以包括用于视觉呈现的显示屏和/或扬声器,以向计算装置1000的用户30呈现有声的图像或文本。
[0076]
如图8所示,计算装置1000可以包括一个或多个网络接口19,以实现经由各种网络(例如,通信网络20)的通信。该网络的示例包括局域网或广域网,例如,企业网络或互联网。
这样的网络可以基于任何合适的技术且可以根据任何合适的协议进行操作以及可以包括无线网络、有线网络或光纤网络。网络接口的示例包括wi-fi、wimax、3g、4g、5g nr、白色空间(white space)、802.11x、卫星、蓝牙、近场通信(near field communication,nfc)、lte、gsm/wcdma/hspa、cdma1x/evdo、dsrc、gps等),虽然图中未示出,但计算装置1000还可以包括一个或多个高速数据总线(其与图8所示的组件互连)以及电力子系统(为这些组件提供电力)。
[0077]
上面描述的各方面和各实施例,可以单独使用、一起使用或以两个或更多个的任意组合使用,因为本技术在这方面不受限制。
[0078]
已经如此描述了本发明的至少一个实施例的一些方面,应当理解,本领域技术人员将容易想到各种改变、修改和改进。这样的改变、修改和改进旨在成为本公开的一部分,并且旨在落入本发明的精神和范围内。此外,尽管指出了本发明的优点,但应当理解,并非本文描述的技术的每个实施例都将包括所描述的每个优点。
[0079]
此外,本发明可以体现为一种方法,本发明提供了该方法的示例。作为该方法的一部分执行的动作可以以任何合适的方式排序。因此,可以构造以不同于图标的顺序执行动作的实施例,这可以包括同时执行一些动作,即使在说明性实施例中被示为顺序动作。
[0080]
在一些实施例中,术语“大约”、“基本上”和“大约”可以用来表示在目标值的
±
20%之内,在一些实施例中,也可用来表示在目标值的
±
10%之内;在一些实施例中,可用来表示在目标值的
±
5%之内。在一些实施例中,可用来表示在目标值的
±
2%以内。术语“大约”和“大约”可以包括目标值。
[0081]
在权利要求书中使用诸如“第一”,“第二”,“第三”等序数术语来修改权利要求要素,其本身并不表示一个权利要求要素相对于另一个权利要求要素的任何优先权、优先级或顺序,或执行方法动作的时间顺序,但仅用作标记,以使用序数词来区分具有相同名称的一个权利要求要素与具有相同名称的另一个元素要素。
[0082]
虽然本发明已经通过示例的方式以及依据优选实施例进行了描述,但是,应当理解的是,本发明并不限于公开的实施例。相反,它旨在覆盖各种变型和类似的结构(如对于本领域技术人员将是显而易见的),例如,不同实施例中的不同特征的组合或替换。因此,所附权利要求的范围应被赋予最宽的解释,以涵盖所有的这些变型和类似的结构。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1