一种基于运算树GPU并行加速模型的电力系统潮流计算方法与流程
本发明涉及电力系统潮流计算,尤其涉及一种基于运算树并行加速模型的电力系统潮流计算方法。
背景技术:
电力系统潮流计算通过给定的电网结构、参数和发电机、负荷等元件的运行条件得到全网功率分布,进而确定系统运行状态,是电力系统稳定计算的基础。随着电网规模不断扩大和“省地一体化”调度模式的发展,为满足实时计算的要求,亟需提高潮流计算的计算效率。目前潮流计算中广泛应用的方法是牛顿法,该方法迭代次数少,收敛速度快,但在迭代过程中需要多次生成雅可比矩阵,计算量非常庞大。当系统规模较大时,使用传统的串行生成方法难以满足实时性需求。
技术实现要素:
本发明要解决的技术问题是对现有技术方案进行完善与改进,提供基于运算树并行加速模型的电力系统潮流计算方法,以提高整体计算效率。为此,本发明采取以下技术方案。
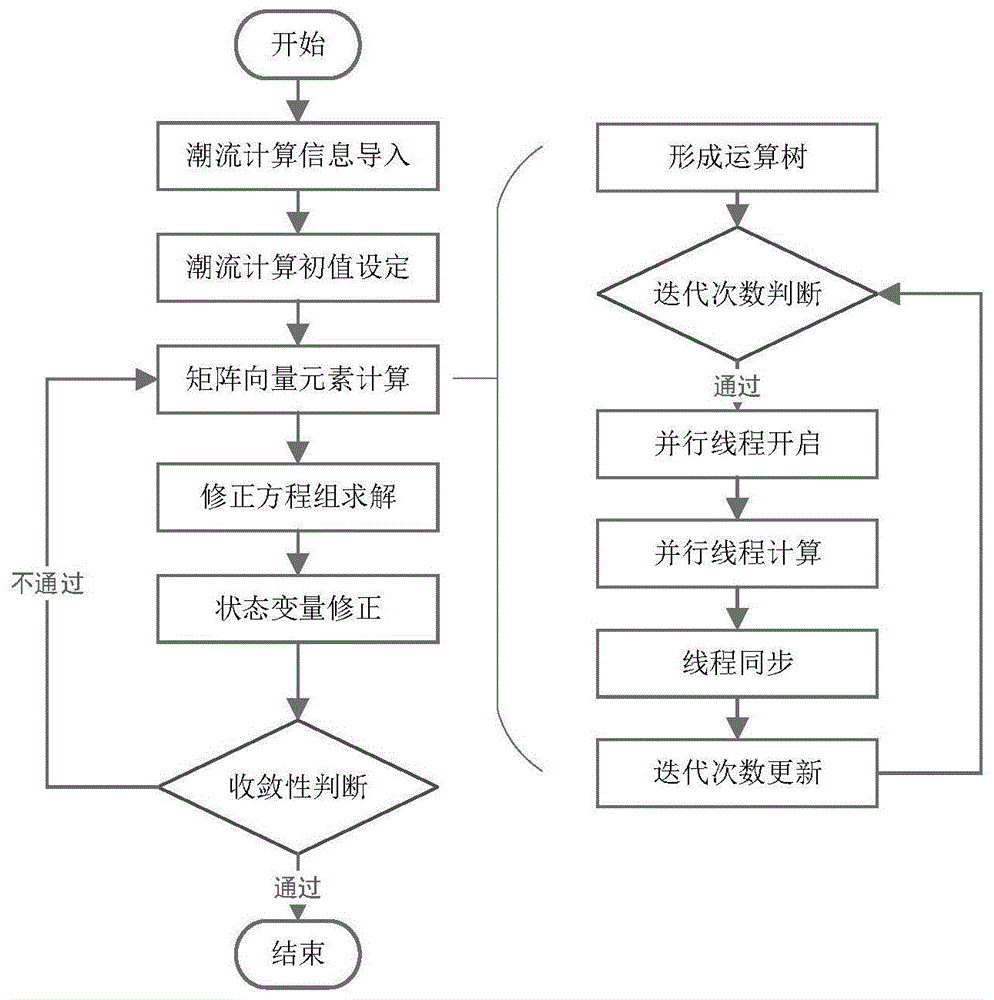
本发明技术方案的主要实现步骤包括潮流计算信息导入、潮流计算初值设定、矩阵向量元素计算、修正方程组求解、状态变量修正、收敛性判断共六个子步骤。
一种基于运算树gpu并行加速模型的电力系统潮流计算方法,具体包括如下步骤:
(1)潮流计算信息导入:导入量测信息(节点电压、节点注入功率)、网络拓扑结构、线路参数信息,形成量测向量z、节点导纳矩阵y。
(2)潮流计算初值设定:状态变量的迭代值为xk,设定算法初始迭代步数k等于0,则状态变量的迭代初值为x0、收敛精度ε。
(3)矩阵向量元素计算:基于运算树gpu并行加速模型,根据量测向量z、节点导纳矩阵y和当前状态变量迭代值xk计算当前迭代步的雅可比矩阵j(xk)和量测修正量b(xk)。
(4)修正方程组求解:求解下式中表示的线性方程组得到修正量δxk。
δxk=j(xk)-1b(xk)
(5)状态变量修正:按下式计算
xk+1=δxk+xk
(6)收敛性判断:若下式满足(即修正量的无穷范数小于收敛精度ε),则算法收敛,结束;否则令当前迭代步数k加1,然后返回步骤(3)。
||δxk||∞≤ε。
上述技术方案中,进一步地,所述的步骤(3)中,矩阵向量元素计算包含以下六个子步骤:
(301)形成运算树:针对所有雅可比矩阵j(xk)和量测修正量b(xk)的非零元运算式,根据每个运算式的后缀表达式生成运算树。将生成的所有的运算树根节点对齐,形成运算森林。设定当前迭代层数i为运算森林的深度。
(302)迭代次数判断:若i≤1,则结束步骤(3)进入步骤(4),否则进入步骤(303)。
(303)并行线程开启:对于运算森林的第i层,若一共有p(i)对兄弟节点,则开启p(i)个gpu线程。
(304)并行线程计算:每一个gpu线程负责处理每一对兄弟节点,获取兄弟节点的数值以及其父节点的运算符进行数值计算,并将计算得出的值写入父节点中。
(305)线程同步:等待所有线程完成计算和更新。
(306)迭代次数更新:令迭代层数i加1,然后返回步骤(302)。
本发明的有益效果在于:
本发明利用运算树gpu并行加速模型来加速电力系统潮流计算中的雅可比矩阵和量测修正量的生成,在系统规模较大时,能显著提高计算效率,满足潮流计算的实时性需求。同时,该方法编程简单,逻辑清晰直观,易于实现。
附图说明
图1是本发明的流程图。
图2是本发明中针对某运算森林进行并行计算的示意图。
具体实施方式
以下结合说明书附图对本发明的技术方案做进一步的详细说明。
如图1所示,本发明方法主要包括潮流计算信息导入、潮流计算初值设定、矩阵向量元素计算、修正方程组求解、状态变量修正、收敛性判断共六个子步骤。
步骤1:潮流计算信息导入:导入量测信息(节点电压、节点注入功率)、网络拓扑结构、线路参数信息,形成量测向量z、节点导纳矩阵y。
步骤2:潮流计算初值设定:设定潮流计算状态变量的初值x0、收敛精度ε。
步骤3:矩阵向量元素计算:基于运算树gpu并行加速模型,根据量测向量z、节点导纳矩阵y和当前状态变量迭代值xk计算当前迭代步的雅可比矩阵j(xk)和量测修正量b(xk)。
步骤4:修正方程组求解:求解下式中表示的线性方程组得到修正量δxk。
δxk=j(xk)-1b(xk)
步骤5:状态变量修正:按下式计算
xk+1=δxk+xk
步骤6:收敛性判断:若下式满足(即修正量的无穷范数小于收敛精度ε),则算法收敛,结束;否则令当前迭代步数k加1,然后返回步骤3。
||δxk||∞≤ε
其中,如图1所示,步骤3包含六个子步骤:
步骤301:形成运算树:针对所有雅可比矩阵j(xk)和量测修正量b(xk)的非零元运算式,根据每个运算式的后缀表达式生成运算树。将生成的所有的运算树根节点对齐,形成运算森林。设定当前迭代层数i为运算森林的深度。
步骤302:迭代次数判断:若i≤1,则结束步骤3,否则进入步骤(303)。
步骤303:并行线程开启:对于运算森林的第i层,若一共有p(i)对兄弟节点,则开启p(i)个gpu线程。
步骤304:并行线程计算:每一个gpu线程负责处理每一对兄弟节点,获取兄弟节点的数值以及其父节点的运算符进行数值计算,并将计算得出的值写入父节点中。
步骤305:线程同步:等待所有线程完成计算和更新。
步骤306:迭代次数更新:令迭代层数i加1,然后返回步骤302。
结合实例说明:
以下结合图2详细解释步骤3,采用本发明方案对某种运算森林进行并行加速。
假设需要计算的雅可比矩阵非零元素和量测修正量元素为a×b+sinc和e-f,将元素按照根节点对齐的方式,形成运算树森林。cpu控制整个算法自底向上开始迭代,每一层迭代过程中,每个gpu线程读取对应兄弟节点的数值和父节点的运算符,计算后将结果写入父节点,直至整个运算森林只剩根节点为止。
特别的,第一次迭代时,gpu线程1计算运算式a×b并将结果写入父节点×,gpu线程2计算运算式sinc并将结果写入父节点sin。第二次迭代时,gpu线程1计算运算式a×b+sinc并将结果写入父节点+,gpu线程2计算运算式e-f并将结果写入父节点-。最终,运算森林只剩下根节点,则所有根节点值为矩阵向量元素。
- 还没有人留言评论。精彩留言会获得点赞!