新能源电站弃电存储辅助决策方法与流程
1.本发明涉及集中式新能源电站与储能电站的协同调峰领域,特别是涉及基于数据挖掘的协同能力的指导方法。
背景技术:
2.近年来为了实现“双碳”目标,电力能源构成发生较大调整,随着电网格局、电源结构的快速变化,国家电网面临着新的挑战。新能源的接入比例逐年增高,新能源发电有其波动性和随机性,新能源的接入给电网的有功、无功调整带来了困难。目前电网调峰几乎全部由常规火电机组承担,但随着碳减排任务的不断加剧,传统火电机组必然会逐步减少。
3.新能源发电通常会受到地理位置和天气情况的很大影响,以最常见的风力发电为例:风力发电受到季节的影响,风力和风向变化很大,发电波动很大,而这个波动周期又是不可控的,如果在电网负荷小的时候发出的电大量被弃,造成极大浪费;而负荷大时,有可能正好无风,没法提供出力。可见如果想提升新能源的渗透率,必须解决其波动性大的特点。
4.储能电站是近年来发展较快的电站形式,其与传统电站最大的差别在于,其实他并不真实发电,而是通过将电能转换成其他型式的能源型式(如化学能、势能等),在需要时再由这些其他能源转换为电能向电网供电,储能电站的调节峰谷能是其最大特点。
5.当前的国家电网的调度方式还是以火力发电为主要出力的方式,调峰调谷也是以具备调峰能力的火电机组为主。通常是根据当前负荷情况调度各场站的出力,使用的是传统的调度方法,缺乏通过精准的预测数据支撑的全盘性绿色能源消纳思考,不利于提升清洁能源的渗透率。要考虑如何能提升新能源的消纳比例,提升我们的发电清洁度,使我们的电网更加安全可靠,是整个电力系统的最终追求。
技术实现要素:
6.为了解决现有技术中的问题,本发明旨在通过数据挖掘,分析历史用电及新能源发电数据,建立电力负荷模型及新能源发电模型,提升新能源的渗透比例与参与调峰的能力。
7.本技术通过以下技术方案来实现上述效果:
8.新能源电站弃电存储辅助决策方法,所述辅助决策方法包括以下过程:
9.建立新能源发电模型、储能释放模型,采用蒙特卡洛模拟进行预测;
10.根据所述新能源发电模型、储能释放模型的预测结果,得到新能源电站弃电存储辅助决策;
11.所述新能源电站弃电存储辅助决策根据各类储能的共性及特点,结合储能类型的指标,得到电站可存储电量的辅助决策建议。
12.进一步的,所述电站可存储电量的辅助决策建议具体为:可存储电量的公式为:
13.e
store
=e
v-e
upload
14.当e
store
≥e
all-can-store
时:
15.当e
store
<e
all-can-store
时:e
store
=e
store
16.式中e
store
为可用于存储的新能源电量,e
all-can-release
为所有储能电站可释放容量,e
all-can-store
为所有储能电站可存储容量。
17.进一步的,所述建立新能源发电模型、储能释放模型具体过程为:
18.获取新能源电站与储能电站发电、用电的历史数据,所述历史数据包含新能源发电数据、新能源场站发电设备信息及实时监测数据、储能场站储能设备信息及实时监测数据;
19.对所述历史数据进行分割分析,得到影响新能源发电的第一制约条件,再根据所述第一制约条件以及获取新能源发电量数据,使用时间序列法和离散数据采样法得到所述新能源发电模型;
20.根据储能类型的特性进行聚类分析,确定在设定时刻,储能场站能够接收存储的电量以及可向电网释放的出力,建立储能释放模型。
21.进一步的,建立所述新能源发电模型为:
22.按时间序列将所述历史数据分割为以设定时长为单位时间的时间片,并给分隔后的数据加入设定的附加属性,得到处理后的历史数据;
23.对所述处理后的历史数据按照不同的属性进行数据提取,分析其分布情况,得到影响新能源发电的第一制约条件,再根据所述第一制约条件以及获取新能源出力数据,得到所述新能源发电模型:
[0024][0025]
其中x为按照附加属性条件从数据库中检索到的出力数据序列,fi为出力权重值,β为冗余系数,l、s、t、w为附加属性。
[0026]
进一步的,建立所述储能释放模型为:
[0027]
按储能类型将发电过程分为抽水蓄能、电池储能、氢储能、压缩空气储能;
[0028]
根据储能类型的特性进行聚类分析,确定在设定时刻,储能场站能够接收存储的电量以及可向电网释放的出力,建立储能释放模型。
[0029]
更进一步的,所述储能释放模型为:
[0030]
根据新能源发电模型、储能释放模型的输出结果,各类储能的共性及特点,根据储能类型的指标算出其可存储的电量和可释放的电量
[0031]
其中erate是存储单元的额定容量,p是存储单元当前电量百分比,ez是存储单元最小保留容量;
[0032]
对所有可存储电量进行汇总,得到电站可存储电量的辅助决策建议:
[0033]
和
[0034]
根据实时当前储量数据及新能源预测数据算出可用于上网的上限及可用于存储的电量。
[0035]
作为本技术的一种优选实施方案,所述附加属性为l:经纬度坐标,s:季节,t:气温,w:所处时段。
[0036]
作为本技术的一种优选实施方案,采用蒙特卡洛模拟进行预测具体为:使用蒙特卡洛模拟分析第一制约条件变化新能源发电产生的影响,绘制变化趋势曲线。
[0037]
有益效果
[0038]
基于数据挖掘的新能源电站与储能电站的协同削峰填谷策略的优势在于,可以在确保电网安全运行的前提下,尽可能提高绿色新能源渗透率的,减少碳排放;本技术提供的新能源电站弃电存储辅助决策方法综合使用新能源发电模型及储能释放模型,可以了解当时并网新能源情况,再结合当前储能存量百分比,可以尽可能将不能并网的电力,存储于储能电站中,只有当储能电站全满时,才真正弃电,这样可以最大限度的使用新能源发出的电力,实现效益最大化。
附图说明
[0039]
构成本技术的一部分的说明书附图用来提供对本技术的进一步理解,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定:
[0040]
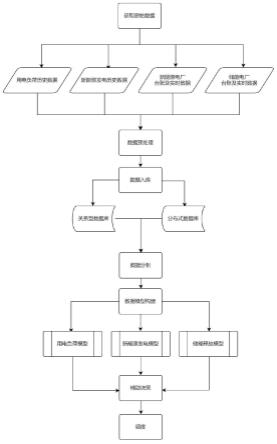
图1为本发明模型构建过程的流程示意图。
具体实施方式
[0041]
下面结合附图对本发明作进一步阐述:
[0042]
新能源电站弃电存储辅助决策方法,所述辅助决策方法包括以下过程:
[0043]
建立新能源发电模型、储能释放模型,采用蒙特卡洛模拟进行预测;
[0044]
根据所述新能源发电模型、储能释放模型的预测结果,得到新能源电站弃电存储辅助决策;
[0045]
所述新能源电站弃电存储辅助决策根据各类储能的共性及特点,结合储能类型的指标,得到电站可存储电量的辅助决策建议。
[0046]
进一步的,所述电站可存储电量的辅助决策建议具体为:可存储电量的公式为:
[0047]estore
=e
v-e
upload
[0048]
当e
store
≥e
all-can-store
时:
[0049]
当e
store
<e
all-can-store
时:e
store
=e
store
[0050]
式中e
store
为可用于存储的新能源电量,e
all-can-release
为所有储能电站可释放容量,e
all-can-store
为所有储能电站可存储容量。
[0051]
技术方案的操作流程如附图1所示,其具体步骤描述如下:
[0052]
新能源发电模型
[0053]
基本思路:采集某新能源场站的实时发电量数据,按时间序列对数据进行分割,将时切片上的负荷数据与此时间切片上的天气等重要因素数据进行结合存储,使用离散分析同等条件下发电量数据的正态分布情况,确定主要关注点,制定取值方案,建立新能源发电模型,此模型的目的是输入指定影响因素,得到发电量预测值。模型用于预测未来同等条件下的新能源发电量。用于辅助决策。
[0054]
举例说明:
[0055]
1.例如已获得某光伏场站所有光伏电池组的装机容量、投运时间、转化率等基础数据以及此光伏场站各机组近三年是实时发电量数据(此数据是以5秒为间隔不断变化);
[0056]
2.按时间序列将其分割为5秒为单位的时间片(时间片只能大于等于最小数据采样频率,时间间隔越小,数据越便于利用),那么一个时间片会有其基本属性(例如:日期、季节、时间区间等),有一些直接关联属性(例如气象类的:天气、气温、气压、光照、风速、风向等),有一些间接关系属性(例如:场站经纬度坐标、电池组故障率、场站电能质量指标、场站高低压穿越能力、场站防孤岛能力、并网逆变器转化率、场站并网电量、场站控制系统用电量等),还有一些附加属性(例如:是否工作时段、是否维护期间等);
[0057]
3.现在有了3*365*24*60*(60/5)个时间片对应的实时发电量,这些时间片又有各自的属性。.
[0058]
4.可以按照不同的属性数据进行数据提取,分析其分布情况(例如:可以按照经纬度、季节、天气、时段这四个维度对数据进行采样分析),选取坐标为北纬31度东经121度为中心点、冬季、多云、傍晚16-17时的时间片进行发电量分析,通过过滤条件,提取到n个离散分布的发电量数据,使用集中趋势、离散程度、形状等数学方法进行数据分布分析,根据数据实际分布情况决定使用何种参数建立新能源发电模型。此模型会根据数据粒度及考虑条件的不同,拥有不同的型式,为了便于理解,以以上四个属性输入为例(l:经纬度坐标,s:季节,t:气温,w:时段)使用加权均值的方式,做抽象示例,此模型可以归结为的形式,其中x为按照以上检索条件从数据库中检索到的发电量数据序列,f为发电量权重值,β为冗余系数(通常小于1),之前的分析过程就是为了确定其加权值的选取,及分析冗余系数如何选取;
[0059]
5.当模型建立完成后,输入l、s、t、w得到f(l,s,t,w)即此条件下的发电量预测值;根据f(l,s,t,w),可以将未来情况(如天气预报等)作为输入参数,得出未来时间点的发电量预测值;
[0060]
6.通过反复调用这个模型,可以产生未来n个小时发电量预测曲线,通过绘制预测曲线,可分析未来发电量变化的趋势,及时调整策略。
[0061]
储能释放模型
[0062]
基本思路:采集所有投运储能场站的储能指标数据,根据储能类型的特性进行聚类分析,确定在某一时刻,储能场站能够接收存储的电量以及可向电网释放的发电量,建立储能释放模型,此模型的目的是输入场站类型、当前存量后,能得到可存储电量和可释放电
量的输出,用于新能源发电的是直接并网还是存储以备后用的辅助决策。为了描述方便,本模型未将由新能源场站传输至储能场站传输电路上的线损纳入考虑范围,也未考虑储能场站储存电能过程中造成的能量损耗。
[0063]
举例说明:
[0064]
1.例如已经获取到某市所有储能场站的储能类型、装机容量、投运时间、转化率、额定功率、最大输出功率等基础数据以及这些场站各储能模块的当前储电数据(此数据是以5秒为间隔不断变化);
[0065]
2.按储能类型归类为抽水蓄能、电池储能、氢储能、压缩空气储能等;
[0066]
3.根据各类储能的共性(如装机容量、额定功率、最大输出功率)及特点(如抽水蓄能不需要逆变,电池储能有随时间变化的衰减、各类型转化率不同等),进行对应分析,根据储能类型的指标算出其可存储的电量和可释放的电量
[0067]
其中erate是存储单元的额定容量,p是存储单元当前电量百分比,ez是存储单元最小保留容量
[0068]
4.对所有可存储电量进行汇总,得出全市可存储电量模型和
[0069]
5.在储能电站调峰辅助决策时可根据实时当前储量数据及新能源预测数据算出可用于上网的上限及可用于存储的电量。
[0070]
新能源电站弃电存储辅助决策
[0071]
存储或弃电辅助决策其实相对简单,可存储电量的公式为:
[0072]estore
=e
v-e
upload
[0073]
当e
store
≥e
all-can-store
时:
[0074]
当e
store
<e
all-can-store
时:e
store
=e
store
[0075]
式中e
store
为可用于存储的新能源电量,e
all-can-release
为所有储能电站可释放容量,e
all-can-store
为所有储能电站可存储容量。
[0076]
目前调度对新能源的调度策略是由新能源电站提供的未来15min~4h的短期功率预测系统结合实时电网负荷调度新能源出力,预测值的时间分辨率是15min。首先此预测值的粒度过大,由于新能源的波动性,15min内可能会发生很大的变化;再者此预测只能体现对新能源出力的预测,并未综合考虑用电负荷的变化趋势以及储能的现状,一旦此预测值准确性发生了变化,那将导致较大的波动,正因为如此,一般调度为了保证电网安全,不允
许新能源参与度过高,造成大量新能源发出的电被弃用。如果新能源发出的电力被弃用,是极大的能源浪费,本来可以节约化石燃料,减少二氧化碳排放的,但实际并没有产生期望的效果。结合新能源场站的建设也需要投入很大的成本,如何能把新能源发出的电力尽可能利用起来,才是我们的最终目的。当前新能源电场发出的电力如果不能上网时,多数电力就浪费了,而综合使用新能源发电模型及储能释放模型,可以了解当时并网新能源情况,再结合当前储能存量百分比,可以尽可能将不能并网的电力,存储于储能电站中,只有当储能电站全满时,才真正弃电,这样可以最大限度的使用新能源发出的电力,实现效益最大化。
[0077]
需要说明的是,实际模型的建立过程是一个可以相对简单,限于数据量有限或对预测精度要求不高,也可以非常复杂,在数据非常充分,考虑的因素很多,对预测的精度要求很高的过程,由于篇幅有限,各使用者需求不尽相同,所以此处只做简单描述,只在说明思路和步聚,最终采集的历史数据越多,粒度越细,考虑的相关属性越多,模型建立的越精确,后期预测就越准确。对辅助决策的帮助就越大,可靠性也越高。模型的建立过程是一个迭代的过程,可以通过历史数据分析建立初步模型,为了验证模型的准确性,可以借助机器学习的相关技术,通过带入若干历史数据进行模拟,分析其汇总值、均值与实际数据的差距,不断调整建模参数,以使最终模型更具代表性。
[0078]
上述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和调整,这些改进和调整也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1