一种电-热-气综合能源系统双层协同控制方法与流程
1.本发明属于综合能源系统优化控制领域,具体涉及一种电-热-气综合能源系统双层协同控制方法。
背景技术:
2.在“双碳”的国家战略下,2021年9月国家发改委印发《完善能源消费强度和总量双控制方案》,对“能耗双控”提出了更为完善的指标设置和落实机制,坚决管控高耗能高排放项目。在能源转型趋势下,综合能源系统(integrated energy system,ies)的能源主体也会发生改变。一方面,在能源侧风电、光伏、天然气等多种清洁能源的接入,增大了供电、供热等方面的不确定性;在负荷侧电动汽车、智能家居以及其他形式的能源负荷等可深度参与能源互动的新型负荷也给需求侧注入了新的不确定性因素。另一方面,综合能源系统整合区域内煤炭、石油、天然气、电能、热能等多种能源,而现有市场投资主体不断增加,意味着现有市场环境下,电网公司已经从能源网络建设的主导者变成了能源网络建设的重要参与者。不同于传统综合能源协同从整体角度出发的决策,综合能源系统的面向多个竞争主体,不同主体之间存在显著的博弈关系。在此背景下,如何在综合能源系统中考虑多元化投资主体的博弈关系,研究提出一种面向综合能源系统的控制策略,已成为一个亟待解决的问题。
3.另外,考虑到综合能源系统中电力、天然气等不同能源网络存在密切的耦合关系,综合能源系统的控制策略求解问题是一个非线性、非凸的优化问题,仅依赖于传统数学建模的方法难以进行求解。近年来,强化学习(reinforce learning,rl)在数据解析度、学习力和计算力方面有很大突破,被应用于智能制造、智慧医疗等领域,表现出良好的应用效果。但是,一方面,对于多智能体强化学习,随着智能体的增多,状态空间会变大,动作空间也会随之呈指数增长,这就会导致多智能体系统维度非常大,计算复杂;另一方面,多智能体系统中每个智能体彼此之间会存在相互耦合影响,奖励设计的优劣会直接影响学习到的策略好坏,因此奖励函数的设定是多智能体强化学习的难点。
技术实现要素:
4.本发明的目的是针对现有技术存在的上述问题,提供一种能够简化奖励函数设计、提高模型收敛性的电-热-气综合能源系统双层协同控制方法。
5.为实现以上目的,本发明的技术方案如下:
6.一种电-热-气综合能源系统双层协同控制方法,依次包括以下步骤:
7.步骤a、构建双层决策控制模型,所述双层决策控制模型包括位于上层的多智能体强化学习模型、位于下层的潮流计算模型,其中,所述多智能体强化学习模型中的多智能体包括电网智能体、热网智能体、气网智能体;
8.步骤b、将采集的综合能源系统的历史状态信息数据输入双层决策控制模型中进行迭代训练,其中,所述状态信息数据包括电负荷需求量、热负荷需求量、气负荷需求量、可
再生能源发电功率、实时售电单价以及购气单价;
9.步骤c、采集综合能源系统的实时状态信息数据,并将其输入训练好的双层决策控制模型中,得到最优的综合能源系统出力,即热电联供机组的电出力、燃气锅炉的热出力、燃气轮机的电出力、电网向系统输送的电功率以及天然气网向系统输送的天然气量。
10.步骤a中,所述多智能体强化学习模型的奖励函数为:
11.r=(γf-r
pun
)
[0012][0013][0014][0015]ccost
(t)=(c
be
p
buy
(t)+c
bgvbuy
(t))
[0016][0017]
ih(t)=c
shhsell
(t)
[0018]
ig(t)=c
sgvsell
(t)
[0019]
上式中,r为奖励值,γ为奖励缩放系数,f为目标函数,r
pun
为越线惩罚系数,当多智能体强化学习模型的动作出现潮流越线时,其值取设定正整数m,否则其值取0,i(t)、c(t)分别为系统在t时段的能源售出成本、运行成本,t为时段总数,ie(t)、ih(t)、ig(t)分别为电力、热力和天然气的售出成本,c
cost
(t)为系统在t时段购买能源的成本,n为智能体个数,c
be
、c
bg
分别为电力、天然气的购买单价,p
buy
(t)为t时段电网向系统输送的电功率,v
buy
(t)为t时段天然气网向系统输送的天然气量,c
se
、c
sh
、c
sg
分别为电力、热力和天然气的售出单价,为t时段系统向用户输送的电功率,h
sell
(t)为t时段系统向用户供热的热功率,v
sell
(t)为t时段用户所需的天然气体积。
[0020]
步骤a中,所述多智能体强化学习模型的智能体动作为:
[0021][0022][0023][0024][0025][0026]
[0027]
p
gt
(t)=η
gtvgt
(t)
[0028][0029][0030]
p
grid
(t)+p
res
(t)+p
gt
(t)+p
chp
(t)-p
eb
(t)=p
load
(t)
[0031]hchp
(t)+h
gb
(t)+h
eb
(t)=h
load
(t)
[0032]
上式中,a
t
为智能体动作的集合,分别为电网智能体热电联供机组、热网智能体燃气锅炉、气网智能体燃气轮机的动作,p
chp
(t)、h
gb
(t)、p
gt
(t)、p
eb
(t)分别为t时段热电联供机组的电出力、燃气锅炉的热出力、燃气轮机的电出力、电锅炉的电出力,h
chp
(t)、h
gb
(t)、h
eb
(t)分别为t时段热电联供机组、燃气锅炉、电锅炉的热出力,η
chp
、η
ge
分别为热电联供机组的定热点比、气转电效率,v
chp
(t)、v
gb
(t)、v
gt
(t)分别为t时段热电联供机组、燃气锅炉、燃气轮机的天然气消耗量,δt为每个时段的时长,q
lhv
为天然气低热值,η
gt
、η
gh
、η
eb
分别为燃气轮机的气电转换系数、燃气锅炉的气转热效率、电锅炉的电热转换系数,p
grid
(t)为t时段电网向系统输送的电功率,p
res
(t)为t时段可再生能源的输出功率,p
load
(t)、h
load
(t)分别为t时段的电负荷需求量、热负荷需求量。
[0033]
步骤a中,所述潮流计算模型包括电力潮流计算模型和气网潮流计算模型;
[0034]
所述电力潮流计算模型为:
[0035][0036][0037]
上式中,δp、δq分别为线路的有功、无功损失,p、q分别为线路的有功、无功功率,u为节点电压,r、x分别为线路的电阻、电抗;
[0038]
所述气网潮流计算模型为:
[0039][0040]wij,t
+w
ji,t
=0
[0041][0042][0043]
ψ
min
≤ψ
i,t
≤ψ
max
[0044]wij,min
≤w
ij,t
≤w
ij,max
[0045]
上式中,c
be
、c
bg
分别为电力、天然气的购买单价,p
buy
(t)为t时段电网向系统输送的电功率,v
buy
(t)为t时段天然气网向系统输送的天然气量,w
j,t
为t时段管道节点j的注入气流,w
ij,t
、w
ji,t
分别为t时段管道节点i向j、j向i传输的气流,w
jk,t
为管道节点j到节点k流
通的气流,z(j)、v(j)分别为以节点j为末节点和以节点j为首节点的管道集合,为t时段气源点j的注入气流,为t时段管道节点j处多智能体的天然气消耗量,为t时段管道节点j的气负荷量,c
ij
为管道ij与管道长度、运行温度以及节点间的气压差有关的常数,ψ
i,t
、ψ
j,t
分别为t时段管道节点i、j的气压,ψ
min
、ψ
max
分别为管道节点的气压下、上限,w
ij,min
、w
ij,max
分别为管道ij传输的气流下、上限。
[0046]
所述步骤b依次包括以下步骤:
[0047]
步骤b1、先将采集的综合能源系统的历史状态信息数据输入多智能体强化学习模型中,随后多智能体强化学习模型基于其策略网络计算得到多智能体动作方案,其中,所述多智能体动作方案包括电网智能体热电联供机组的电出力、热网智能体燃气锅炉的热出力以及气网智能体燃气轮机的电出力;
[0048]
步骤b2、潮流计算模型接收多智能体动作方案后对其进行能流计算,并判定是否出现潮流越线,若是,则将该判定结果反馈至多智能体强化学习模型;若否,则将该判定结果与计算得到的电网向系统输送的电功率以及天然气网向系统输送的天然气量数据反馈至多智能体强化学习模型;
[0049]
步骤b3、多智能体强化学习模型根据接收到的反馈信息、通过奖励函数计算奖励值,并将其输入、输出数据以及奖励值存储至经验池中;
[0050]
步骤b4、循环重复步骤b1-步骤b3,直至损失函数和奖励函数达到稳定。
[0051]
所述多智能体强化学习模型为maddpg框架算法下的深度强化学习模型。
[0052]
所述步骤c通过将实时状态信息数据与经验池中的数据进行匹配,以一段时间内平均奖励值最大的动作方案作为最优的综合能源系统出力。
[0053]
与现有技术相比,本发明的有益效果为:
[0054]
1、本发明一种电-热-气综合能源系统双层协同控制方法先构建由上层多智能体强化学习模型和下层潮流计算模型构成的双层决策控制模型,再将采集的综合能源系统的历史状态信息数据输入双层决策控制模型中进行迭代训练,随后采集综合能源系统的实时状态信息数据,并将其输入训练好的双层决策控制模型中,得到最优的综合能源系统出力,一方面,该方法将下层潮流计算模型的能流计算结果反馈至上层多智能体强化学习模型计算奖励值,当上层多智能体强化学习模型输出的动作出现潮流越线时,在奖励函数中增加越线惩罚系数,从而可以降低多智能体强化学习模型输出动作违反约束时的奖励函数设计复杂性;另一方面,该方法在下层潮流计算模型中加入了平衡机组,即电网向系统输送的电功率以及天然气网向系统输送的天然气量的计算,将其反馈至上层多智能体强化学习模型中可进一步降低奖励函数的设计复杂性;该下层潮流计算模型的引入可避免因设计奖励函数惩罚项的失误而导致的模型收敛慢或难以收敛情况问题。因此,本发明有效简化了奖励函数的设计,提高了模型的收敛性。
[0055]
2、本发明一种电-热-气综合能源系统双层协同控制方法中多智能体强化学习模型的智能体动作设计考虑了综合能源设备之间的耦合和平衡关系,基于该关系可有效加对强智能体动作的约束,减小动作空间,进而降低了计算的复杂性。因此,本发明降低了计算的复杂性。
附图说明
[0056]
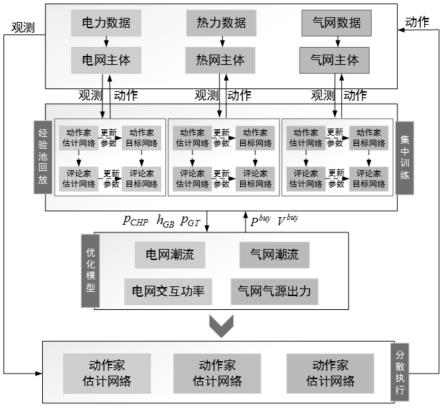
图1为本发明中双层决策控制模型的机制图。
[0057]
图2为实施例1的综合能源系统图。
[0058]
图3为实施例1中综合能源系统的耦合网络图。
具体实施方式
[0059]
下面结合具体实施方式以及附图对本发明作进一步详细的说明。
[0060]
本发明提供了一种电-热-气综合能源系统双层协同控制方法,该方法基于由上层多智能体强化学习模型和下层潮流计算模型构成的双层决策控制模型,下层模型为上层模型提供综合能源系统的能流数据,上层模型根据下层模型提供的数据对智能体的决策行为进行奖励,该方法可以提高模型的收敛性和训练速度,有效解决了复杂耦合网络中存在的高维非线性优化问题。
[0061]
在深度强化学习中,奖励函数的设计至关重要,奖励能够引导智能体挖掘状态信息中的决策相关因素并经过提炼后用于动作空间中进行动作选取。在多智能体强化学习模型学习综合能源系统优化调度策略时,可能会选择不符合系统运行约束条件的动作。面对这种情况下,通常需要定义智能体在采取越线动作时的惩罚,也就是在奖励函数中增加惩罚项的方式来引导智能体做出正确的决策。综合能源系统中的约束和潮流、耦合情况都十分复杂,若仅通过设置奖励函数惩罚项来引导,很有可能因为一个错误或者不合适的惩罚项,导致智能体学习策略的速度很慢,甚至整个模型难以收敛。因此本发明采取了上、下双层模型,通过下层模型对综合能源的平衡约束,出力限制、潮流情况等方面进行计算,避免了因为设计奖励函数惩罚项的失误而导致模型收敛慢、难以收敛的情况。
[0062]
本发明中多智能体强化学习模型采用maddpg框架算法下的深度强化学习模型,maddpg能够通过分布式多智能体建立完全合作型混合博弈过程,其对每个智能体都建立由策略网络(actor)和值函数网络(critic)构成的优化模块,多智能体的观测状态量为综合能源系统中的电力负荷、热力负荷和气负荷等,其控制动作为各能源设备的出力,奖励值函数基于综合能源系统的成本和收益进行设计。通过传感器与通信网络获取本地观测量,基于策略网络计算动作方案,动作后系统更新运行状态并反馈奖励值。通过“集中训练-分散执行”的训练和部署框架,每个智能体根据得到的奖励信号对策略进行评价,循环往复过程,最终得到使长期奖励最大的策略。随着多智能体强化学习算法的不断训练与更新,其动作奖励曲线不断提高并最终趋向于收敛,能够对综合能源的时变状态和管控策略进行决策。
[0063]
实施例1:
[0064]
参见图1,一种电-热-气综合能源系统双层协同控制方法,依次按照以下步骤进行:
[0065]
1、构建双层决策控制模型,所述双层决策控制模型包括位于上层的多智能体强化学习模型、位于下层的潮流计算模型,所述多智能体强化学习模型为maddpg框架算法下的深度强化学习模型,其将综合能源系统的出力决策问题建模为马尔科夫决策过程,并利用drl求解此问题。
[0066]
1.1奖励函数设计
[0067]
本系统的控制目标是通过控制可控设备的出力,使其系统在周期t内的净利润最大,采用如下目标函数:
[0068][0069][0070][0071]ccost
(t)=(c
be
p
buy
(t)+c
bgvbuy
(t))
[0072][0073]
ih(t)=c
shhsell
(t)
[0074]
ig(t)=c
sgvsell
(t)
[0075]
上式中,f为目标函数,i(t)、c(t)分别为系统在t时段的能源售出成本、运行成本,t为时段总数,ie(t)、ih(t)、ig(t)分别为电力、热力和天然气的售出成本,c
cost
(t)为系统在t时段购买能源的成本,n为智能体个数,c
be
、c
bg
分别为电力、天然气的购买单价,p
buy
(t)为t时段电网向系统输送的电功率,v
buy
(t)为t时段天然气网向系统输送的天然气量,c
se
、c
sh
、c
sg
分别为电力、热力和天然气的售出单价,为t时段系统向用户输送的电功率,h
sell
(t)为t时段系统向用户供热的热功率,v
sell
(t)为t时段用户所需的天然气体积。
[0076]
对于热网来说,其发电量由综合能源系统内部进行输送,不从外部购买,其成本由已有气源出力和电力出力部分转换,因此,奖励函数设计如下:
[0077]
r=(γf-r
pun
)
[0078]
上式中,r为奖励值,γ为奖励缩放系数,r
pun
为越线惩罚系数,当多智能体强化学习模型的动作出现潮流越线时,其值取设定正整数200,否则其值取0。
[0079]
1.2动作空间设计
[0080]
ies中的动作可以由电网智能体热电联供chp、热网智能体燃气锅炉gb以及气网智能体燃气轮机gt三种设备的出力情况表示。当chp电出力p
chp
(t)确定后,可以根据公式确定chp热出力h
chp
(t)和气消耗v
chp
(t);当gb的热出力h
gb
(t)确定后,可以确定gb的气消耗v
gb
(t),此时也可以确定eb热出力h
eb
(t)以及eb电消耗p
eb
(t)。因此,可以将智能体动作表示为:
[0081][0082][0083][0084][0085]
对于chp机组来说,其输出电功率与热功率之间具有耦合关系,根据其电热比是否
变化分为定热点比和变热电比两种类型,本发明设为定热点比,用η
chp
表示:
[0086][0087][0088]
燃气轮机通过燃烧天然气产生电能,其表达式如下:
[0089]
p
gt
(t)=η
gtvgt
(t)
[0090]
电锅炉以负荷的形式接在电网上,其数学模型如下:
[0091][0092]
燃气锅炉以负荷的形式接在气网上,其数学模型如下:
[0093][0094]
在t时段,可通过电功率平衡约束和热功率平衡约束确定电锅炉消耗的电功率值:
[0095]
p
grid
(t)+p
res
(t)+p
gt
(t)+p
chp
(t)-p
eb
(t)=p
load
(t)
[0096]hchp
(t)+h
gb
(t)+h
eb
(t)=h
load
(t)
[0097]
上式中,a
t
为智能体动作的集合,分别为电网智能体热电联供机组、热网智能体燃气锅炉、气网智能体燃气轮机的动作,p
chp
(t)、h
gb
(t)、p
gt
(t)、p
eb
(t)分别为t时段热电联供机组的电出力、燃气锅炉的热出力、燃气轮机的电出力、电锅炉的电出力,h
chp
(t)、h
gb
(t)、h
eb
(t)分别为t时段热电联供机组、燃气锅炉、电锅炉的热出力,η
chp
、η
ge
分别为热电联供机组的定热点比、气转电效率,v
chp
(t)、v
gb
(t)、v
gt
(t)分别为t时段热电联供机组、燃气锅炉、燃气轮机的天然气消耗量,δt为每个时段的时长,q
lhv
为天然气低热值,η
gt
、η
gh
、η
eb
分别为燃气轮机的气电转换系数、燃气锅炉的气转热效率、电锅炉的电热转换系数,p
grid
(t)为t时段电网向系统输送的电功率,p
res
(t)为t时段可再生能源的输出功率,p
load
(t)、h
load
(t)分别为t时段的电负荷需求量、热负荷需求量。
[0098]
所述潮流计算模型包括电力潮流计算模型和气网潮流计算模型,所述电力潮流计算模型为:
[0099][0100][0101]
上式中,δp、δq分别为线路的有功、无功损失,p、q分别为线路的有功、无功功率,u为节点电压,r、x分别为线路的电阻、电抗;
[0102]
所述气网潮流计算模型为:
[0103]
f=min(c
be
p
buy
(t)+c
bgvbuy
(t))
[0104][0105]wij,t
+w
ji,t
=0
[0106][0107][0108]
ψ
min
≤ψ
i,t
≤ψ
max
[0109]wij,min
≤w
ij,t
≤w
ij,max
[0110]
上式中,f为目标函数,c
be
、c
bg
分别为电力、天然气的购买单价,p
buy
(t)为t时段电网向系统输送的电功率,v
buy
(t)为t时段天然气网向系统输送的天然气量,w
j,t
为t时段管道节点j的注入气流,w
ij,t
、w
ji,t
分别为t时段管道节点i向j、j向i传输的气流,w
jk,t
为管道节点j到节点k流通的气流,z(j)、v(j)分别为以节点j为末节点和以节点j为首节点的管道集合,为t时段气源点j的注入气流,为t时段管道节点j处多智能体的天然气消耗量,为t时段管道节点j的气负荷量,c
ij
为管道ij与管道长度、运行温度以及节点间的气压差有关的常数,ψ
i,t
、ψ
j,t
分别为t时段管道节点i、j的气压,ψ
min
、ψ
max
分别为管道节点的气压下、上限,w
ij,min
、w
ij,max
分别为管道ij传输的气流下、上限。
[0111]
2、先将采集的综合能源系统的历史状态信息数据输入多智能体强化学习模型中,随后多智能体强化学习模型基于其策略网络计算得到多智能体动作方案,其中,所述状态信息数据包括电负荷需求量、热负荷需求量、气负荷需求量、可再生能源发电功率、实时售电单价以及购气单价,所述多智能体动作方案包括电网智能体热电联供机组的电出力、热网智能体燃气锅炉的热出力以及气网智能体燃气轮机的电出力。
[0112]
3、潮流计算模型接收多智能体动作方案后对其进行能流计算,并判定是否出现潮流越线,若是,则将该判定结果反馈至多智能体强化学习模型;若否,则将该判定结果与计算得到的电网向系统输送的电功率以及天然气网向系统输送的天然气量数据反馈至多智能体强化学习模型。
[0113]
4、多智能体强化学习模型根据接收到的反馈信息、通过奖励函数计算奖励值,并将此时段的状态与下一时刻段的状态以及动作都存储至经验池中。
[0114]
5、循环重复步骤2-步骤4,直至损失函数l(θ)和奖励函数达到稳定:
[0115][0116]
上式中,s为每回合训练采样数,yj为目标q值,θ为估值网络参数值,q
μ
(sj,aj)为值函数网络值。
[0117]
6、采集综合能源系统的实时状态信息数据,并将其输入训练好的双层决策控制模型中,通过将实时状态信息数据与经验池中的数据进行匹配,以一段时间内平均奖励值最大的动作方案作为最优的综合能源系统出力,即热电联供机组的电出力、燃气锅炉的热出力、燃气轮机的电出力、电网向系统输送的电功率以及天然气网向系统输送的天然气量,同
时将输入的状态数据与匹配的动作存储至经验池中,使策略能够不断进行更新。
[0118]
本实施例采用的综合能源系统由33节点的电力系统和20节点的天然气系统组成(系统图参见图2,耦合网络图参见图3),热网转换为电负荷的形式连接在电网上,电力系统包含2个chp电源、2个风力电源和1个光伏电源,供热系统包括有4个热源(1台电锅炉、3台燃气锅炉),天然气系统拥有6个气源。系统调度时长为24h,相邻2个时段的间隔为1h。为测试所提模型应对系统不确定性的能力,考虑ies中的电热气负荷以及可再生能源出力。不确定性的存在导致进行ies控制时会遇到海量不同场景,本实施例通过一年的可再生能源(风力机组与光伏)、电负荷数据、热负荷数据以及气负荷数据传入模型中进行策略结果验证。搜索时间步数为24,设置50000个回合。
[0119]
仿真结果显示,运用上述双层模型对综合能源系统进行控制,初期由于智能体的动作策略探索不全面,智能体会选择牺牲利润保证运行约束得到满足,从而造成了奖励函数值偏低。通过后期通过大量的学习,智能体对不同的状态场景能够做出有效决策,奖励函数不断增加,直至大约26000个回合时收敛。
[0120]
以上结果表明,通过本发明提出的双层模型,在充分考虑电、热、气三个主体的动态博弈下,可以有效提高综合能源系统的能源利用效率。此外,模型结合了数据驱动的多智能体强化学习方法和传统潮流算法,具有更高的求解效率,可以实现综合能源系统的协同控制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1