基于Transformer模型的电力变压器负荷预测方法与流程
基于transformer模型的电力变压器负荷预测方法
技术领域
1.本发明属于电力计量数据处理的技术领域,具体涉及一种电力变压器负载的预测方法。
背景技术:
2.智能电网通过先进的传感和测量技术及先进的控制系统,实现电网的可靠、安全、经济、高效、环境友好运行。电力变压器是电网建设中的重要设备,根据其历史运行规律数据信息,对其负荷做出准确长期的预测是构建智能电网的重要条件。电力变压器负载预测是以历史时间序列数据作为数据源,利用数据挖掘、深度学习等技术建立电力变压器负载预测数学模型,并根据建立的模型,对电力变压器负载做出预测,有利于实现合理的电力分配,减少电力浪费。
3.随着风电装机容量的不断增长,风电并网对主电网所带来的技术和经济影响越来越大,对变压器数据处理提出了更大的挑战。因为风电场的并网运行对电网的电能质量、电压稳定、电网安全等诸多方面会带来负面的影响,准确地预测电力变压器负载才能有效提高电能质量和电压的稳定程度。因此,如何对电力变压器负载做出合理的估计可以有效减少不必要的电力浪费,充分发挥智能电网的辅助决策作用。
4.电力变压器具有结构复杂、材料参数呈非线性变动的特点。在电力调配过程中,往往只能够对变压器进行相对保守的调整。现实中要想实现对电力变压器负载的预测是十分困难,因为它受天气、温度、季节、环境等多种因素的影响,从而呈现出复杂的变化特性。目前已提出的电力变压器负载预测方法大体可以分为两类,一类是以arima、prophet等为代表的统计学模型,另一类是以rnn为代表的自回归模型。这些方法往往根据单个或多个变量进行短期预测,其预测时长短,精度低,难以处理现实应用中高维的大量数据和复杂时序关系,不适合实际应用。
技术实现要素:
5.为解决现有技术存在的不足之处,本发明的目的在于提供一种基于交互式多头注意力transformer模型的电力变压器负荷预测方法,以transformer模型的编码器-解码器架构为基础,利用深度可分离卷积实现传统多头注意力不同子空间的信息交互,提高模型对数据的拟合能力,同时,利用最大池化层对时序数据进行蒸馏,减少模型训练过程中的内存开销,实现对电力变压器负荷的精确预测。
6.本发明的第二个目的是提出使用上述预测方法的应用。
7.本发明的第三个目的是提出使用上述预测方法的设备。
8.实现本发明上述目的的技术方案为:
9.一种基于transformer模型的电力变压器负荷预测方法,包括步骤:
10.s1:采集电力变压器的负荷数据,将采集的电力变压器负荷数据按时间进行排列得到序列样本数据集xi表示i时刻观测变量的值,l
x
表示观
测的时间序列长度,d
x
表示观测变量数目;
11.对该序列样本数据集进行归一化处理,使样本数据数值处于[0,1]之间,得到数据集作为监督学习的样本;
[0012]
s2:将归一化处理的数据集划分为训练集、测试集和验证集,并保证每个数据集采样周期(采集的间隔时间)能代表同一时段的特征变化样本;
[0013]
s3:定义和建立基于交互式多头注意力transformer模型,并初始化网络内部参数及学习率;原始数据经过嵌入层和位置编码层后将会转化为带有位置信息的特征向量,其中,时序编码包括全局时序编码和局部时序编码,全局时序编码由数据时间戳中的年月周信息组成,局部时序编码公式则如下所示:
[0014][0015][0016]
式中,pe表示position encoding,pos表示位置,j表示维度,
[0017]
s4:所述transformer模型由编码器和解码器组成,在编码器中,采用多头注意力层和多头注意力交互层进行特征提取,包括:将上述带有时序信息的向量输入到多头注意力层中从而获得中间值:
[0018][0019]
其中wq,wk,wv为权重矩阵,q,k,v为输入向量;
[0020]
由多个部分组成,每个部分表示一个子空间:
[0021][0022]
使用深度可分离卷积实现在不同子空间上的信息交互;
[0023][0024]
其中,conv1和conv2分别表示depth-wise convolution和point-wise convolution,elu表示激活函数;
[0025]
然后使用线性变化层进行特征维度转换,最后通过池化层进行下采样获得输出:
[0026][0027]
s5:采用多头注意力层和多头注意力交互层构建三层解码器;首先利用来自多头注意力交互层的特征f1和来自残差连接的特征f2计算权重比例其中表示权重矩阵,bg表示偏置,sigmoid表示激活函数。然后基于该比例,对上述两个特征f1和f2进行加权求和
[0028]
fusion(f1,f2)=g
⊙
f1+(1-g)f2[0029]
s6:采用多头注意力层和多头注意力交互层构建解码器。其中,掩码多头注意力负责将解码器的输入转换为query矩阵,而上述编码器的输出则作为key矩阵和value矩阵,由多头注意力层负责对query矩阵和key矩阵作内积运算得出贡献度得分,然后将所得贡献度得分和value矩阵相乘得到特征向量。多头注意力交互层负责对形成的特征向量进行子空
间的信息交互,最后由线性变化层输出最终预测序列。
[0030]
s1中数据点按时间排列,取样可以有1小时间隔或15min,1min间隔的,越短时间间隔的数据越精细。s4特征提取部分,传统的多头注意力机制是将特征分成几块,没有考虑不同子空间的信息交互,这限制了模型对时序数据的特征提取能力。本发明对模型里注意机制进行改进;用卷积处理,各块有相互联系,能预测更长时间的数据。本发明在多头注意力机制的基础上,引入了多头注意力交互层,使用深度可分离卷积实现在不同子空间上的信息交互。本方法降低了模型训练过程中的内存开销。能够自适应选择特征并过滤掉冗余的信息。
[0031]
其中,用测温元件、电流表、电压表,传感器采集电力变压器的与负荷相关的数据,所述数据包括负载、油温、位置、气候、需求中的一种或多种。
[0032]
进一步地,在s4步骤中:
[0033]
由多头注意力层生成的输出向量
[0034]
经过多头注意力交互层进行信息交互,该多头注意力交互层由深度可分离卷积,线性变化层以及最大池化组成;对于多头自注意力机制形成的输出张量先利用1x1的pointwise卷积在通道维度上进行信息聚合;经过elu激活函数后使用depthwise卷积在空间维度上进行信息交互,以同时学习空间上的相关性和通道间的相关性;最后,利用步长为2的最大池化层实现对时间序列的蒸馏操作。本操作使其在经过每一层编码器后,在时间维度上长度减半,过滤了冗余的信息,从而减少了训练过程中的内存消耗。
[0035]
其中,s2:将预处理好的数据集按照7:2:1的比例分别划分为训练集、测试集和验证集,并保证每个数据集采样周期能代表同一时段的特征变化样本(“同一时段”是采集的间隔时间)。
[0036]
进一步地,在s4步骤中:
[0037]
解码器的输入部分表示为其中,来自encoder输入的后k个时间步的值,作为需要预测的目标序列的占位符(用0填充);最后,全连接层用于输出预测值,其维度取决于需要预测的变量数目。
[0038]
其中,所述的步骤s4网络收敛过程中,使用平均绝对误差(mse)损失函数和随机梯度下降的adam算法。
[0039]
本方法一方面动态的修改各参数的学习率,另一方面引入动量法,使得参数更新有更多的机会跳出局部最优,加速和优化网络收敛。
[0040]
训练过程是输入模型,梯度下降过程中迭代,以减少误差的过程。
[0041]
所述的基于transformer模型的电力变压器预测方法,还包括s7:对模型过拟合评估,在训练过程中,使用earlystopping防止模型过拟合;对于每一轮训练后的模型,使用步骤s2得到的验证集进行验证,随着训练轮次的增加,如果在验证集上发现测试误差上升,则停止训练;将停止之后的权重作为网络的最终参数。
[0042]
所述的基于transformer模型的电力变压器预测方法的应用,用模型进行预测:模型评估验证后,将步骤s2中获得的测试集数据输入到经过步骤s7验证好的模型中对未来时间值进行预测。
[0043]
本方法可用于风力发电场或其他具有类似特征设施,优选用于风力发电场的变压
器负荷预测。
[0044]
本基于交互式多头注意力transformer的电力变压器负荷预测模型,接受历史负荷序列作为输入,预测未来多个时间步的负荷数值;通过对实现多头注意力之间的信息交互,提高了模型对长序列数据的特征提取能力,从而实现对电力变压器负荷的高精度长期预测。
[0045]
一种设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现所述的方法步骤。
[0046]
本发明的有益效果在于:
[0047]
本发明提出的一种基于交互式多头注意力transformer模型的电力变压器负荷预测方法,与现有的预测方法相比,其优点在于:传统的时间序列预测方法无法对长序列数据作出准确的预测,本预测方法在transformer的基础上引入交互式多头注意力,用于增强模型对序列数据的特征抽取能力,同时,为了减少模型训练过程中内存开销,利用最大池化层实现了对序列数据的蒸馏操作。
[0048]
本发明提出的电力变压器负荷预测方法,可以更好地捕捉长序列数据之间依赖关系,从而实现对电力变压器负荷的精确预测,在智能电网建设中具有一定的实用性。
[0049]
本预测方法利用最大池化层对时序数据进行蒸馏,减少模型训练过程中的内存开销,实现对电力变压器负荷的精确预测。
附图说明
[0050]
图1为本发明的基于交互式多头注意力transformer模型的电力变压器负荷预测的流程图;
[0051]
图2为本发明基于交互式多头注意力transformer模型的电力变压器负荷预测的模型图;
[0052]
图3展示了本发明提出的预测方法imahn相较于真实数据的预测效果。
具体实施方式
[0053]
以下实施例用于说明本发明,但不用来限制本发明的范围。
[0054]
如无特别说明,说明书中采用的技术手段均为本领域已知的技术手段。
[0055]
以下结合附图及实施例对本发明作进一步详细说明,本发明的一种基于交互式多头注意力transformer模型的电力变压器负载预测方法。
[0056]
实施例使用的训练数据集收集了从2016年至2018年中国同一省两个不同地区的电力变压器的负载情况。每个数据点每分钟记录一次(用m标记),命名为ett-small-m1。该数据集包含2年
×
365天
×
24小时
×
4=70,080数据点。此外,本数据集还提供一个小时级别粒度的数据集变体使用(用h标记),即ett-small-h1和ett-small-h2。每个数据点均包含8维特征,包括数据点的记录日期、预测值“油温”以及6个不同类型的外部负载值,分别是高有效负载(high useful load)、高无效负载(high useless load)、中有效负载(middle useful load)、中无效负载(middle useless load、低有效负载(low useful load)、低无效负载(low useless load)。
[0057]
实施例1:
[0058]
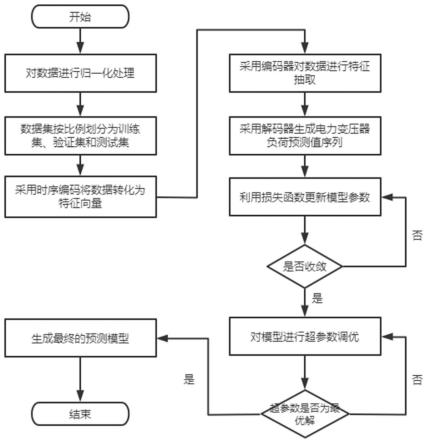
图1所示为本发明一种基于交互式多头注意力transformer模型的电力变压器负载预测方法的流程图。具体包括步骤:
[0059]
s1:采集电力变压器的负荷数据,将采集的电力变压器负荷数据按时间进行排列得到序列样本数据集xi表示i时刻观测变量的值,l
x
表示观测的时间序列长度,d
x
表示观测变量数目;
[0060]
对该序列样本数据集进行归一化处理,使样本数据数值处于[0,1]之间,得到数据集作为监督学习的样本;
[0061]
s2:将归一化处理的数据集按照7:2:1的比例划分为训练集、测试集和验证集,并保证每个数据集采样周期能代表同一时段的特征变化样本。
[0062]
并保证每个数据集采样周期能代表同一时段的特征变化样本;
[0063]
s3:定义和建立基于交互式多头注意力transformer模型,并初始化网络内部参数及学习率;原始数据经过嵌入层和位置编码层后将会转化为带有位置信息的特征向量,其中,时序编码包括全局时序编码和局部时序编码,全局时序编码由数据时间戳中的年月周信息组成,局部时序编码公式则如下所示:
[0064][0065][0066]
式中,pe表示position encoding,pos表示位置,j表示维度,
[0067]
s4:所述transformer模型由编码器和解码器组成,在编码器中,采用多头注意力层和多头注意力交互层进行特征提取,包括:将上述带有时序信息的向量输入到多头注意力层中从而获得中间值:
[0068][0069]
其中wq,wk,wv为权重矩阵,q,k,v为输入向量;
[0070]
由多个部分组成,每个部分表示一个子空间:
[0071][0072]
使用深度可分离卷积实现在不同子空间上的信息交互;
[0073]
其中,conv1和conv2分别表示depth-wise convolution和point-wise convolution,elu表示激活函数;
[0074]
然后使用线性变化层进行特征维度转换,最后通过池化层进行下采样获得输出:
[0075][0076]
在s4步骤中:
[0077]
由多头注意力层生成的输出向量
[0078][0079]
经过多头注意力交互层进行信息交互,该交互模块由深度可分离卷积,线性变化
层以及最大池化组成;对于多头自注意力机制形成的输出张量先利用1x1的pointwise卷积在通道维度上进行信息聚合。经过elu激活函数后使用depthwise卷积在空间维度上进行信息交互,以同时学习空间上的相关性和通道间的相关性。最后,利用步长为2的最大池化层实现对时间序列的蒸馏操作。其中,所述的信息交互的模块由深度可分离卷积、线性变化层以及最大池化组成,对于多头自注意力机制形成的输出张量先利用1x1的pointwise卷积在通道维度上进行信息聚合。经过elu激活函数后使用depthwise卷积在空间维度上进行信息交互,以同时学习空间上的相关性和通道间的相关性;最后,利用步长为2的最大池化层实现对时间序列的蒸馏操作。
[0080]
s4步骤中:
[0081]
由多头注意力层生成的输出向量oi=attention(qwi
iq
,kw
ik
,vw
iv
)经过多头注意力交互层进行信息交互。
[0082]
解码器的输入部分表示为其中,来自encoder输入的后k个时间步的值,作为需要预测的目标序列的占位符(用0填充);最后,全连接层用于输出预测值,其维度取决于需要预测的变量数目。
[0083]
步骤4网络收敛过程中,使用平均绝对误差(mse)损失函数和随机梯度下降的adam算法。
[0084]
s5:采用多头注意力层和多头注意力交互层构建三层解码器;首先利用来自多头注意力交互层的特征f1和来自残差连接的特征f2计算权重比例其中表示权重矩阵,bg表示偏置,sigmoid表示激活函数。然后基于该比例,对上述两个特征进行加权求和fusion(f1,f2)=g
⊙
f1+(1-g)f2[0085]
s6:采用多头注意力层和多头注意力交互层构建解码器。其中,掩码多头注意力负责将解码器的输入转换为query矩阵,而上述编码器的输出则作为key矩阵和value矩阵,由多头注意力层负责对query矩阵和key矩阵作内积运算得出贡献度得分,然后将所得贡献度得分和value矩阵相乘得到特征向量。多头注意力交互层负责对形成的特征向量进行子空间的信息交互,最后由线性变化层输出最终预测序列。
[0086]
s7:对模型过拟合评估,在训练过程中使用earlystopping防止模型过拟合;对于每一轮训练后的模型,使用步骤s2得到的验证集进行验证,随着训练轮次的增加,如果在验证集上发现测试误差上升,则停止训练;将停止之后的权重作为网络的最终参数。
[0087]
模型评估验证后,将步骤2中获得的测试集数据输入到经过步骤5验证好的模型中对未来时间值进行预测。图3展示了本方法在ett数据集上的部分预测结果,表1和表2分别展示了本方法在单变量和多变量情况下相较于其它预测方法的对比结果,由上述图表可以看出本模型的有效性和先进性。
[0088]
表1单变量时间序列预测结果
[0089][0090]
表1中,imhan为本发明提出的方法,informer、lstma、deepar、arima、prophet为对比方法。
[0091]
mae(平均绝对误差),mse(均方误差)为评价指标。
[0092]
实施例2:
[0093]
采用和实施例1相同的电力变压器负荷预测方法,获得transformer模型。本实施例中,输入多变量进行预测,所述多变量包括负载、油温、位置、气候、需求。原始数据集中的数据通过测温元件、电流和用户侧功率测量等方式获得。本实施例用多变量预测负载这一变量;公式输入的维度不同于实施例1。
[0094]
通过transformer模型获得的结果见表2:
[0095]
表2多变量时间序列预测结果
[0096][0097]
表2中,imahn为本文提出的方法,informer、lstma、lstnet为对比的预测方法。
[0098]
实施例3:应用
[0099]
模型评估验证后,将步骤2中获得的测试集数据输入到经过步骤7验证好的模型中对未来时间值进行预测,从而指导电网中变压器的选型和设置。
[0100]
对于风力发电机并网的变压器,其多变量中位置、气候根据风电场设置不同而变化,本预测方法尤其适合风力发电场变压器的负荷预测。
[0101]
虽然,以上通过实施例对本发明进行了说明,但本领域技术人员应了解,在不偏离本发明精神和实质的前提下,对本发明所做的改进和变型,均应属于本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1