一种基于值分布深度Q网络的微电网储能调度优化方法
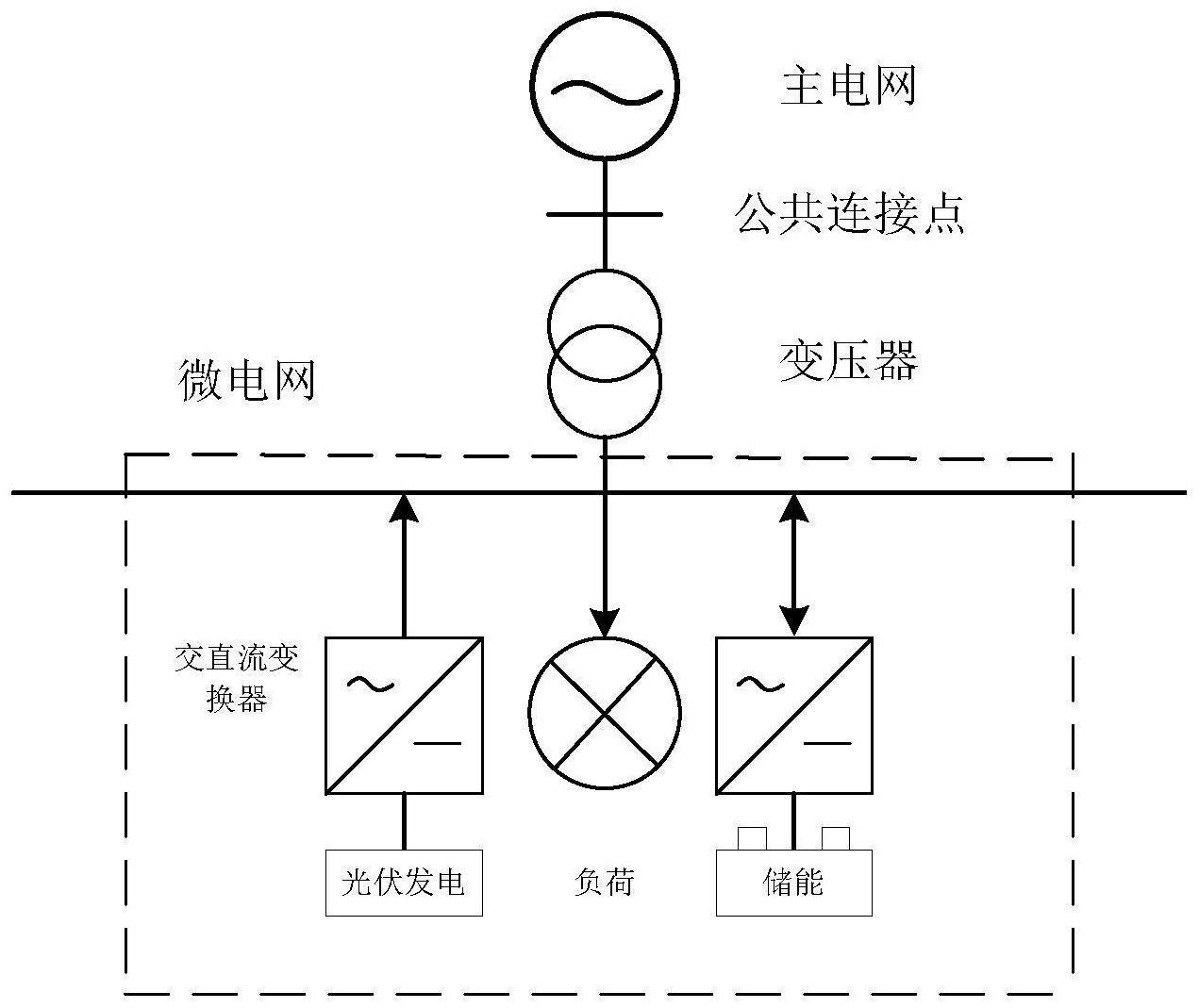
本发明涉及电力调度工程,尤其涉及一种基于值分布深度q网络的微电网储能调度优化方法。
背景技术:
1、微电网(microgrid,mg),作为新型电力系统的典型代表,其内部包含分布式供电单元、储能单元和负载单元,储能作为微电网中的核心环节,在微电网稳定运行、能量优化管理、短时供电、改善电能质量等方面起着至关重要的作用。以储能系统的控制方法为核心来研究微电网的调度策略是应对微电网优化运行问题的关键所在。
2、近年来,随着对节能减排的重视,越来越多的算法应用电力系统中。主要方法分为有模型和无模型两大类。对于有模型的方法:由于微电网同时面临能源侧和负荷侧的不确定性,这使得对于微电网的准确建模难以完成,且微电网的优化决策场景也难以表述为明确的数学表达式,会导致决策优化难以达到最优结果;对于无模型的方法:随着人工智能的兴起,将强化学习应用于电力系统中的研究也越来越多。强化学习方法是求解序贯决策的无模型方法,通过智能体与不确定环境的互动获取反馈来学习在环境中获得最大奖励的策略。现有方案大多数是基于dqn算法来实现对微电网的优化和管理,但由于微电网决策序列较长,而且新能源发电功率和负载需求功率以及电价具有波动性,会导致该方法需要大量时间去训练微电网储能调度决策。
技术实现思路
1、有鉴于此,本发明的目的在于提出一种基于值分布深度q网络的微电网储能调度优化方法,以解决有模型方法的建立数学模型困难和无法达到最优调度决策以及无模型强化学习方法的训练时间过长的问题。
2、基于上述目的,本发明提供了一种基于值分布深度q网络的微电网储能调度优化方法,包括以下步骤:
3、s1、根据目标微电网结构建立与之对应的储能系统模型;
4、s2、将微电网系统储能调度问题转换为马尔科夫决策过程,以此建立储能系统智能体状态空间、动作空间和奖励函数;
5、s3、利用值分布深度q网络强化学习算法对储能调度马尔科夫决策过程进行训练,通过与环境的交互使从环境中获得的奖励达到稳定后,得到训练好的模型;
6、s4、将微电网储能调度模型中的光伏发电组件的日发电量,日负荷量,储能系统荷电状态以及分时电价数据信息作为状态输入到训练好的模型,输出储能充放电调度策略,得出微电网运行成本最小的调度方案。
7、优选地,步骤s1进一步包括:
8、s11、建立储能系统模型:使用动态模型表示储能系统,和分别表示在时间t储能系统的充电或者放电功率,t时刻储能系统荷电状态用表示,则储能系统的模型为:
9、
10、s12、设定储能系统限制条件:对于建立的储能模型,对其在t时刻的充电功率放电功率和储能系统荷电状态加以限制:
11、
12、
13、
14、其中,分别表示储能系统充放电功率的最大值,分别表示储能系统荷电状态最小值和最大值;
15、s13、设定微电网功率平衡限制:功率平衡关系为:
16、
17、
18、其中,为t时刻微电网同外部电网的交互功率,若大于0则表示微电网向外部电网购电,若小于0则表示微电网向外部电网售电,为t时刻光伏发电功率,为t时刻储能系统充放电功率,为t时刻负载的功率需求。
19、优选地,步骤s2进一步包括:
20、s21、定义状态空间s:包括光伏发电功率、负载需求功率、储能系统荷电状态和从电网中的购电价格,状态空间为:
21、
22、在系统状态空间s中,分别表示在t时刻的光伏发电功率和负荷需求功率,表示在t时刻的储能系统的荷电状态,pricet表示在t时刻外部电网的购电价格;
23、定义动作空间a:包括储能系统的充电功率和放电功率,动作空间表示为:
24、
25、在系统动作空间a中,表示在t时刻的储能充放电功率;
26、定义奖励函数r:包括微电网系统在满足约束情况下运行时产生的成本和违反约束时的惩罚项,奖励函数表示为:
27、
28、在奖励函数r中,表示在t时刻向外部电网交换电能的功率,c是储能系统的维修成本,η表示违反约束的惩罚项;
29、建立决策方法:使用深度神经网络来近似智能体的动作-价值函数和智能体接受环境的状态量,将状态量输入到深度神经网络中,深度神经网络输出在观测状态下的状态-动作价值分布z(s,a),状态-动作价值分布函数表示智能体在观测状态st时并采取动作的长期回报的分布:
30、
31、其中,γ是折扣因子,rt表示在t时刻状态s下执行动作a后获得的奖励,st表示t时刻的状态信息,at表示t时刻的动作,深度神经网络输出的状态-动作价值分布与储能智能体可采取的动作相对应,智能体根据最大q值选取动作,其中q值的公式为:
32、
33、其中n表示神经网络输出的分布粒子数,i为第i个分布粒子,θ-是神经网络的参数,s,a为输入的状态和动作,输出为长期回报的分布z。
34、优选地,步骤s3进一步包括:
35、s31、利用随机权重θ初始化神经网络,同时令目标神经网络权重θ-等于价值网络权重θ;初始化回放记忆单元d,初始化神经网络输出的分布粒子数n;
36、s32、获取微电网的状态信息,初始化储能系统荷电状态,设置初始荷电状态为0,对初始状态信息进行预处理转化成张量;
37、s33、在每个训练周期中,依据ε-贪心策略选择动作,设定ε如下:
38、ε=0.9×(0.995×i)
39、其中,i为智能体训练的周期数,同时在[0,1]范围内等概率随机生成一个数,若这个数大于ε,那么此时智能体选取获得最大估计值的动作价值函数q所对应的动作a,若这个数小于ε,那么此时智能体从动作空间随机选取一个动作a;
40、s34、智能体在任一状态st时依据步骤s33中选取的动作执行,并观测在执行动作后获得的奖励rt同时转移到下一状态st+1;
41、s35、若此时下一状态st+1存在,将元组(st,at,rt,st+1)存入回放记忆单元,当记忆回放单元储存的样本数据达到最小样本数要求后,从回放记忆单元中选取小批量数据对智能体神经网络进行训练;
42、s36、将从回放记忆单元中选取的元组中的状态信息st输入到值分布z,选取值分布z输出的最大动作状态值q(st,at;θ),并将此时的q(st,at)作为监督信息,再将状态信息st+1也输入到值分布z中,获取此时输出的最大动作状态值对应的动作索引index,然后从目标网络中获取在输入st+1的状态下对应index的动作的q'(st+1,at+1;θ-)值,则此时神经网络的更新目标为:
43、
44、
45、其中,n为值分布的粒子个数;为通过核函数k计算出两个分布的距离,α表示神经网络的学习率;
46、对于目标值函数θ-,每隔十个训练周期,令θ-=θ用以更新目标值分布z的深度神经网络参数;
47、s37、重复步骤s31-s36,直到值分别z收敛,训练结束保存训练完成后的神经网络参数,得到训练好的模型。
48、优选地,步骤s4进一步包括:
49、s41、将微电网储能调度模型中的光伏发电组件的日发电量,日负荷量,储能系统荷电状态以及分时电价数据信息作为状态输入到训练好的模型,在每个时隙t,智能体根据学习策略做出决策,执行动作at;
50、s42、观测t+1时刻状态st+1;
51、s43、重复步骤s41-s42,直到优化决策终止,得到每个时刻的调度方案。
52、本发明的有益效果:本发明将微电网储能调度问题描述为强化学习框架下的马尔科夫决策过程,不需要对微电网储能调度进行具体的数学建模,可以避免实际当中数学建模的困难和难以收敛到最优调度策略的问题。通过智能体与环境不断交互学习最终获得最优调度策略,通过最优调度策略来对储能系统进行调控,能够有效减少微电网运行成本,降低算法在微电网储能系统中训练的时间,具有很强的实用性和可移植性。
- 还没有人留言评论。精彩留言会获得点赞!