本发明涉及风电功率预测,特别是涉及一种基于时空分布的风电功率概率密度的预测方法。
背景技术:
1、风电功率预测技术是指对未来一段时间内风电场所能输出的功率大小进行预测,以便安排调度计划。这是因为风能属于随机波动的不稳定能源,大规模的风电并入系统,必将会对电力系统的稳定性带来新的挑战。因此,准确预测风电功率,对电力调度策略的制定以及电力系统的稳定运行具有重大意义。
2、现有的风电功率预测方法包括确定性预测(点预测)和不确定性预测(区间预测),点预测方法能够得到一个确定的风电功率预测值,主要涉及支持向量机、时间序列、神经网络等,但其不能对风电功率的不确定性做出定量描述。由于风力发电十分依赖自然因素,并且容易受天气因素的影响,具有不确定性,因此,传统的点预测方法无法避免预测误差。而不确定性预测是对未来时刻的风电功率波动范围或概率密度的预测,可以反映具体时刻风电功率波动范围及其概率,其预测结果一般是以风电功率概率密度函数的形式呈现。与点预测方法相比,不确定性预测能够量化风电功率的不确定性,能够对风电功率进行更加准确的预测,为电力系统调度人员带来更加全面的决策依据。目前,传统的不确定预测是针对整个风电场范围内的所有风机出力总和进行的,主要是以时间序列预测为主,没有考虑不同位置风机的差异性,此外不确定性预测多采用基于rnn或cnn模型预测方法,而rnn或cnn模型及其变体都具有时不变性质,即模型参数随着时间的推移保持不变,持续使用相同的权重参数,基于风电功率的不确定性,这些模型的时不变性质会降低其对风电功率的预测能力,预测精度较低,无法准确预测风电功率的不确定性。
技术实现思路
1、本发明实施例的目的在于提供一种基于时空分布的风电功率概率密度的预测方法,以实现风电场内单风机风电功率的高精度预测,解决现有技术无法准确预测风电功率的不确定性的问题。
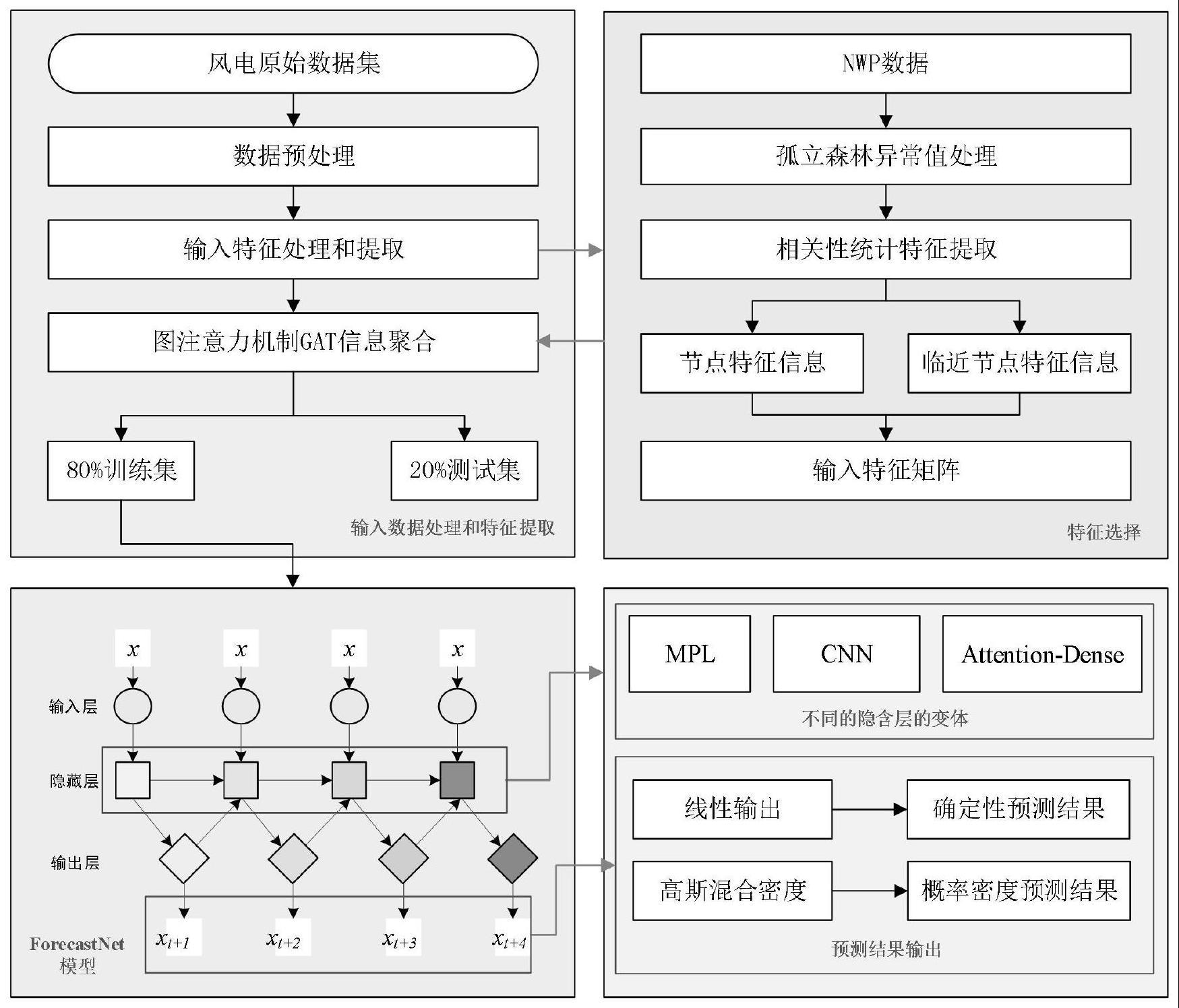
2、为解决上述技术问题,本发明所采用的技术方案是,一种基于时空分布的风电功率概率密度的预测方法,包括以下步骤:
3、s1、对风机数据进行预处理:对异常值进行检测并对其进行修复,然后对数据进行归一化处理;
4、s2、基于欧式距离和差分距离两个指标共同提取单个风机的临近节点数,基于图注意力机制对风机数据进行信息聚合,构建输入矩阵特征;
5、s3、构建不同隐含层的风电功率概率密度的预测模型;
6、s4、将获得的风电功率输入矩阵特征作为输入传送给不同隐含层的风电功率概率密度的预测模型来训练及预测,输出预测风电功率曲线。
7、进一步的,s1中风机数据包括风速、风向、温度、叶片俯仰角、风电机机舱的偏航角。
8、进一步的,所述s1具体为:
9、根据下式计算异常分数:
10、
11、式中,s(x)为样本x的异常值分数,其取值范围为[0,1];h(x)为样本在树上的路径长度,h(x)=ln(x)+ξ,ξ为欧拉常数;e(h(x))为样本x在树上的路径长度均值;c(x)为一个包含x个样本的数据集构成的二叉树的平均搜索路径长度,其中,
12、
13、其中h(·)为调和数;使用拉格朗日插值法对异常值进行修复:
14、
15、其中,xi、xj为表示节点i、j的风速;yi为风电功率;l()为拉格朗日插值多项式;同时对风电功率数据进行归一化处理,消除量纲影响,将每一风电功率数据转化为[0,1]之间的风电功率数据:
16、
17、其中,xw′为风电功率的归一化值,max(xw)为风电功率数据最大值,min(xw)为风电功率数据最小值,xw为风电功率实际值。
18、进一步的,所述s2中,提取单个风机的临近节点数的过程具体为:
19、欧氏距离相关性:计算某个风机节点与其他节点间的欧式距离:
20、
21、其中,(xa,ya)与(xb,yb)为风机a、b的二维空间位置;
22、选择距离最接近的k个节点作为该风机节点的临近节点,如下式所示:
23、
24、式中,a(i,j)为欧式距离相关性得到的风机临近节点矩阵;n(i)为欧氏距离最接近的k个的风机节点集合;
25、差分距离相关性:捕获风机之间的隐式关系,通过计算两个节点间的差分相似度sim(i,j),将最近的k个节点作为差分临近节点,表示为集合ns(i),其中:
26、
27、t为总的时间序列t内的某个时刻,w代表风速,xi,w∈rt×1表示第i个节点的风力涡轮机的风速序列,xj,w∈rt×1表示第j个节点的风力涡轮机的风速序列。
28、进一步的,所述s2中,基于图注意力机制对风机数据进行信息聚合过程具体为:
29、s201、计算各数据特征向量在中心目标节点与邻居节点注意力分数,节点j的特征对节点i上的注意力值为eij:
30、
31、s202、使用激活函数激活权重分数得到ei,j:
32、ei,j=leakyrelu(at[whi||whj])
33、s203、权重归一化,后续为了信息聚合需要所有权重之和为1,使用softmax对节点的所有邻接节点注意力值进行权重归一化操作,归一化后的值为αij:
34、
35、s204、通过图注意力层将节点自身特征信息和邻居节点特征信息按照一定的权重系数进行相加求和,进行特征提取形成新的节点来表示特征,输出结果为新的节点特征:
36、
37、s205、多头注意力机制将多个节点的输出结果进行列向量拼接,得到最后的新节点特征,新节点特征的计算公式:
38、
39、其中,eij为中心目标节点与邻居节点注意力分数,即节点i的特征对节点j上的注意力值;α代表节点间的相关度计算函数;hi为i节点的输出向量;w为权重,由模型训练得到,用于将原始节点的特征映射到一个新的维度;ei,j为激活函数激活的权重分数,其中||为向量竖向拼接操作,将映射后的列向量进行拼接;leaky relu为激活函数;α为待学习的向量,at为向量α的转置;h‘i为新节点特征;σ(·)为激活函数;αij为节点i特征在节点j上的注意力分数,eik表示邻居节点;代表第k个注意力机制计算得到的注意力分数归一化值;wk为线性变换的权重矩阵,k表示为k的集合。
40、进一步的,s3中所述风电功率概率密度的预测模型包括多层神经网络,每一层神经网络包括依次连接的输入层、隐含层和输出层。
41、进一步的,所述隐含层为如下形式的前馈形网络的一种:
42、a.隐含层为mlp多层感知器,风电功率概率密度预测模型隐含层采用mlp结构,其中dense为全连接层,mlp网络的隐含层和输出层都是全连接层,每一层都具有24个relu神经元单元,其中的神经元节点完全连接;
43、b.隐含层为cnn,其结构包括卷积层、池化层和全连接层,其中卷积层由24个relu神经元构成;
44、c.隐含层为基于注意力机制的全连接层,在全连接层的基础上增加了注意力机制的模块。
45、进一步的,s4具体为:选择出力最高且时空关联性较高的n个风力涡轮机的数据作为训练模型的历史数据,使用这些数据进行预测作为其他涡轮机的输出,并将预测结果的平均值作为风电厂的其他涡轮机的预测结果;
46、其中,所述n值的确定方法为:通过在模型中采用线性输出的方法得到不同n值的预测结果,选取误差指标最小的n值作为最后结果。
47、进一步的,所述预测包括确定性预测、多部预测及不确定性预测;
48、其中,多部预测为每一步预测未来12个时间点的数据,在下一个时刻预测前把上一步得到的预测结果与历史特征合并,共同作为下一个模型的输入;
49、确定性预测:在模型输出层采用线性输出的方式并通过多步预测得到确定性的预测结果;
50、不确定性预测:在模型输出层采用高斯混合密度网络进行概率密度输出得到风电功率的区间预测结果;根据区间覆盖率cp和区间平均宽度nwp指标评判模型优劣,并根据根据不同的隐含层模型对模型进行改进。
51、进一步的,所述区间覆盖率cp和区间平均宽度nwp分别为:
52、
53、
54、其中,c为测试集中真实值落在预测区间内的数目;v为测试集中真实值总数目;ymax是预测时刻t测试集风电功率最大值,ymin为预测时刻t测试集风电功率最小值;ut为预测区间上界;lt为预测区间下界。
55、与现有技术相比,本发明的有益效果是:
56、(1)基于图注意力网络和相关距离函数对风电数据输入进行信息聚合能够在一定程度上改善预测模型对时空数据的提取能力。
57、(2)forecastnet模型时不变特性和交错输出特性,在进行多步预测过程中可以有效地解决神经网络模型传递的梯度爆炸或消失的问题,训练速度更快。
58、(3)使用高出力风机数据作为训练模型,基于训练好的模型对其他风力涡轮机进行预测用以代表其他涡轮机的输出,取最高出力的n个风机数据进行训练,将得到的预测结果取组合加权作为预测结果矫正,简化了预测流程。