基于强化学习的充放电策略网络训练方法和储能控制方法与流程
本说明书实施例涉及储能管控,尤其是一种基于强化学习的充放电策略网络训练方法和储能控制方法。
背景技术:
1、随着电力供给侧结构不断调整,可再生能源接入电网的比例不断增大,使得峰谷负荷差被进一步拉大,加重了电力供应和电力需求间不匹配的问题。对此,用户侧储能技术被提出,其通过将多余的电力在用户侧存储起来,在需要的时候再释放出来,从而实现能源的高效利用。
2、用户侧储能需通过储能电池实现,储能电池持续大功率充放电将会导致其容量、性能退化。现有的方法未考虑储能电池的性能退化和时变用户电力负荷下用户侧储能装置的实时充放电控制,用户侧储能的运行控制有待进一步优化。
技术实现思路
1、针对现有技术的上述问题,本说明书实施例的目的在于,提供一种基于强化学习的充放电策略网络训练方法和储能控制方法,以解决现有技术中由于未考虑电池性能退化和时变用户电力负荷的因素导致用户侧储能控制不准确和能源浪费的问题。
2、为了解决上述技术问题,本说明书实施例的具体技术方案如下:
3、第一方面,本说明书实施例提供一种基于强化学习的充放电策略网络训练方法,包括:
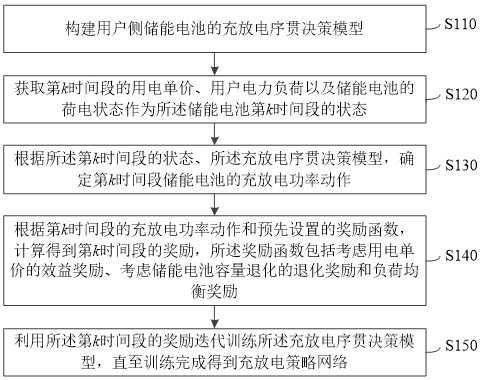
4、构建用户侧储能电池的充放电序贯决策模型;
5、获取第 k时间段的用电单价、用户电力负荷以及储能电池的荷电状态作为所述储能电池第 k时间段的状态;
6、根据所述第 k时间段的状态、所述充放电序贯决策模型,确定第 k时间段储能电池的充放电功率动作;
7、根据第 k时间段的充放电功率动作和预先设置的奖励函数,计算得到第 k时间段的奖励,所述奖励函数包括考虑用电单价的效益奖励、考虑储能电池容量退化的退化奖励和负荷均衡奖励;
8、利用所述第 k时间段的奖励迭代训练所述充放电序贯决策模型,直至训练完成得到充放电策略网络。
9、具体地,利用所述第 k时间段的奖励迭代训练所述充放电序贯决策模型,直至训练完成得到充放电策略网络,包括:
10、根据所述第 k时间段的奖励训练所述充放电序贯决策模型,得到第 k+1时间段的状态;
11、根据所述第 k+1时间段的状态和所述充放电序贯决策模型,确定第 k+1时间段储能电池的充放电功率动作;
12、根据第 k+1时间段储能电池的充放电功率动作和预先设置的奖励函数,计算得到第 k+1时间段的奖励;
13、判断所述第 k+1时间段的奖励是否满足预定条件;
14、若是,则将所述充放电序贯决策模型输出作为所述充放电策略网络;
15、若否,则重复以上步骤对所述充放电序贯决策模型进行迭代更新。
16、优选地,所述奖励函数为:
17、 r k = ω1 r b( k) + ω2 r s( k) + ω3 r a( k)
18、其中, r k为第 k时间段的奖励; ω1、 ω2和 ω3为权重因子; r b( k)为第 k时间段的效益奖励; r s( k)为第 k时间段的负荷均衡奖励; r a( k)为第 k时间段的储能电池退化奖励;
19、所述效益奖励为:
20、
21、其中, p demand( i)为第 i时间段的用户电力负荷; t d为时间段的时间间隔; e i为第 i时间段的用电单价; p b ( i)为第 i时间段的储能电池充放电功率; n为时间段的数量;
22、所述负荷均衡奖励为:
23、 r s ( k) = p b ( k) - p b ( k-1)
24、其中, p b ( k)和 p b ( k-1)分别为第 k时间段和第 k-1时间段的储能电池充放电功率;
25、所述储能电池退化奖励为:
26、
27、其中, m为预指数因子; c rate为充放电速率;σ为幂指数; r为通用气体常数; t为绝对温度; a( c rate)为安时吞吐量。
28、具体地,所述安时吞吐量为:
29、
30、其中, t k为第 k时间段的时刻; τ表示时间; i( τ)为第 τ时刻的电流; q b为储能电池的额定容量。
31、具体地,第 k时间段的储能电池的荷电状态通过如下充放电模型得到:
32、
33、其中, soc( k)为第 k个时间段储能电池的荷电状态; soc0为初始时间段储能电池的荷电状态; p b( i)为第 i时间段的储能电池充放电功率,当储能电池放电时, p b( i)>0,当储能电池充电时, p b( i)<0; t d为各时间段的时间间隔; v b为储能电池的开路电压; q b为储能电池的额定容量。
34、进一步地,所述第 k时间段用户侧储能电池的充放电功率动作位于动作集合中,所述动作集合为:
35、
36、其中, a为动作集合; p b为用户用电负荷;和分别为最大充电功率和最大放电功率; n a为动作集合中的动作数量。
37、更进一步地,判断所述第 k+1时间段的奖励是否满足预定条件,为:
38、判断所述第 k+1时间段的奖励和与第 k+1时间段顺序相邻的其他多个时间段的奖励是否在预设的差异范围内,且所述第 k+1时间段的奖励大于其他多个时间段的奖励。
39、第二方面,本说明书实施例提供一种储能控制方法,所述储能控制方法应用如上述技术方案提供的基于强化学习的充放电策略网络训练方法训练得到的充放电策略网络,所述储能控制方法包括:
40、获取当前时间段的用电单价、用户电力负荷以及储能电池的荷电状态;
41、将当前时间段的用电单价、用户电力负荷以及储能电池的荷电状态输入至所述充放电策略网络中,获得所述充放电策略网络输出的当前时间段的用户侧储能电池的充放电功率。
42、第三方面,本说明书实施例提供一种基于强化学习的充放电策略网络训练装置,包括:
43、模型构建模块,用于构建用户侧储能电池的充放电序贯决策模型;
44、状态获取模块,用于获取第 k时间段的用电单价、用户电力负荷以及储能电池的荷电状态作为所述充放电序贯决策模型第 k时间段的状态;
45、充放电功率动作确定模块,用于根据所述第 k时间段的状态、所述充放电序贯决策模型,确定第 k时间段储能电池的充放电功率动作;
46、奖励计算模块,用于根据第 k时间段的充放电功率动作和预先设置的奖励函数,计算得到第 k时间段的奖励,所述奖励函数包括考虑用电单价的效益奖励、考虑储能电池容量退化的退化奖励和负荷均衡奖励;
47、训练模块,用于利用所述第 k时间段的奖励迭代训练所述充放电序贯决策模型,直至训练完成得到充放电策略网络。
48、第四方面,本说明书实施例提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述技术方案提供的基于强化学习的充放电策略网络训练方法或储能控制方法。
49、采用上述技术方案,本说明书实施例提供的一种基于强化学习的充放电策略网络训练方法和储能控制方法,基于强化学习的方法构建了用户侧储能电池的充放电序贯决策模型,设计了效益奖励、负荷均衡奖励和考虑了用户侧储能电池在运行过程中性能退化因素的储能电池退化奖励,充分利用了用户侧储能的削峰填谷能力,降低了用电负荷方差和电池容量损失,提高了供电经济性,减少了能源的损失。
50、为让本说明书实施例的上述和其他目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附图式,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!